性能之殇:从冯·诺依曼瓶颈谈起
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:机器之心
:JohnLui
本文作者根据自己的认知,讨论了人们为提高性能做出的种种努力,包括硬件层面的 CPU、RAM、磁盘,操作系统层面的并发、并行、事件驱动,软件层面的多进程、多线程,网络层面的分布式等。
本文共分为七个部分:
天才冯·诺依曼与冯·诺依曼瓶颈
分支预测、流水线与多核 CPU
通用电子计算机的胎记:事件驱动
Unix 进程模型的局限
DPDK、SDN 与大页内存
现代计算机最亲密的伙伴:局部性与乐观
分布式计算、超级计算机与神经网络共同的瓶颈
(一)天才冯·诺依曼与冯·诺依曼瓶颈
电子计算机与信息技术是最近几十年人类科技发展最快的领域,无可争议地改变了每个人的生活:从生活方式到战争方式,从烹饪方式到国家治理方式,都被计算机和信息技术彻底地改变了。如果说核武器彻底改变了国与国之间相处的模式,那么计算机与信息技术则彻底改变了人类这个物种本身,人类的进化也进入了一个新的阶段。
简单地说,生物进化之前还有化学进化。然而细胞一经诞生,中心法则的分子进化就趋于停滞了:38 亿年来,中心法则再没有新的变动,所有的蛋白质都由 20 种标准氨基酸连成,连碱基与氨基酸对应关系也沿袭至今,所有现代生物共用一套标准遗传密码。正如中心法则是化学进化的产物,却因为开创了生物进化而停止了化学进化,人类是生物进化的产物,也因为开创了文化进化和技术进化而停止了生物进化——进化已经走上了更高的维度。 ——《进化的阶次 | 混乱博物馆》
本文目标
本文的目标是在我有限的认知范围内,讨论一下人们为了提高性能做出的种种努力,这里面包含硬件层面的 CPU、RAM、磁盘,操作系统层面的并发、并行、事件驱动,软件层面的多进程、多线程,网络层面的分布式,等等等等。事实上,上述名词并不局限于某一个层面,计算机从 CPU 内的门电路到显示器上浏览器中的某行字,是层层协作才得以实现的;计算机科学中的许多概念,都跨越了层级:事件驱动就是 CPU 和操作系统协作完成的。
天才 冯·诺依曼
冯·诺依曼 1903 年 12 月 28 日出生于奥匈帝国布达佩斯,1957 年 2 月 8 日卒于美国,终年 53 岁。在他短暂的一生中,他取得了巨大的成就,远不止于世人熟知的「冯·诺依曼架构」。
约翰·冯·诺伊曼,出生于匈牙利的美国籍犹太人数学家,现代电子计算机与博弈论的重要创始人,在泛函分析、遍历理论、几何学、拓扑学和数值分析等众多数学领域及计算机学、量子力学和经济学中都有重大贡献。 ——约翰·冯·诺伊曼的维基百科
除了对计算机科学的贡献,他还有一个称号不被大众所熟知:「博弈论之父」。博弈论被认为是 20 世纪经济学最伟大的成果之一。(说到博弈论,我相信大多数人第一个想到的肯定跟我一样,那就是「纳什均衡」)
冯·诺依曼架构
冯·诺依曼由于在曼哈顿工程中需要大量的运算,从而使用了当时最先进的两台计算机 Mark I 和 ENIAC,在使用 Mark I 和 ENIAC 的过程中,他意识到了存储程序的重要性,从而提出了存储程序逻辑架构。
「冯·诺依曼架构」定义如下:
以运算单元为中心
采用存储程序原理
存储器是按地址访问、线性编址的空间
控制流由指令流产生
指令由操作码和地址码组成
数据以二进制编码
优势
冯·诺依曼架构第一次将存储器和运算器分开,指令和数据均放置于存储器中,为计算机的通用性奠定了基础。虽然在规范中计算单元依然是核心,但冯·诺依曼架构事实上导致了以存储器为核心的现代计算机的诞生。
注:请各位在心里明确一件事情:存储器指的是内存,即 RAM。磁盘理论上属于输入输出设备。
该架构的另一项重要贡献是用二进制取代十进制,大幅降低了运算电路的复杂度。这为晶体管时代超大规模集成电路的诞生提供了最重要的基础,让我们实现了今天手腕上的 Apple Watch 运算性能远超早期大型计算机的壮举,这也是摩尔定律得以实现的基础。
冯·诺伊曼瓶颈
冯·诺依曼架构为计算机大提速铺平了道路,却也埋下了一个隐患:在内存容量指数级提升以后,CPU 和内存之间的数据传输带宽成为了瓶颈。

上图是 i9-7980XE 18 核 36 线程的民用最强 CPU,其配合超频过的 DDR4 3200MHz 的内存,测试出的内存读取速度为 90GB/S。看起来很快了是不是?看看图中的 L1 Cache,3.7TB/S。
我们再来算算时间。这颗 CPU 最大睿频 4.4GHz,就是说 CPU 执行一个指令需要的时间是 0.000000000227273 秒,即 0.22ns(纳秒),而内存的延迟是 68.1ns。换句话说,只要去内存里取一个字节,就需要 CPU 等待 300 个周期,何其的浪费 CPU 的时间啊。
CPU L1 L2 L3 三级缓存是使用和 CPU 同样的 14 纳米工艺制造的硅半导体,每一个 bit 都使用六个场效应管(通俗解释成三极管)构成,成本高昂且非常占用 CPU 核心面积,故不能做成很大容量。
除此之外,L1 L2 L3 三级缓存对计算机速度的提升来源于计算机内存的「局部性」,相关内容我们之后会专门讨论。
(二)分支预测、流水线与多核 CPU
CPU 硬件为了提高性能,逐步发展出了指令流水线(分支预测)和多核 CPU,本文我们就将简单地探讨一下它们的原理和效果。
指令流水线
在一台纯粹的图灵机中,指令是一个一个顺序执行的。而现实世界的通用计算机所用的很多基础算法都是可以并行的,例如加法器和乘法器,它们可以很容易地被切分成可以同时运行的多个指令,这样就可以大幅提升性能。
指令流水线,说白了就是 CPU 电路层面的并发。
Intel Core i7 自 Sandy Bridge(2010)架构以来一直都是 14 级流水线设计。基于 Cedar Mill 架构的最后一代奔腾 4,在 2006 年就拥有 3.8GHz 的超高频率,却因为其长达 31 级的流水线而成了为样子货,被 AMD 1GHz 的芯片按在地上摩擦。
RISC 机器的五层流水线示意图
下图形象地展示了流水线式如何提高性能的。

缺点
指令流水线通过硬件层面的并发来提高性能,却也带来了一些无法避免的缺点。
设计难度高,一不小心就成为了高频低能的奔四
并发导致每一条指令的执行时间变长
优化难度大,有时候两行代码的顺序变动就可能导致数倍的性能差异,这对编译器提出了更高的要求
如果多次分支预测失败,会导致严重的性能损失
分支预测
指令形成流水线以后,就需要一种高效的调控来保证硬件层面并发的效果:最佳情况是每条流水线里的十几个指令都是正确的,这样完全不浪费时钟周期。而分支预测就是干这个的:
分支预测器猜测条件表达式两路分支中哪一路最可能发生,然后推测执行这一路的指令,来避免流水线停顿造成的时间浪费。但是,如果后来发现分支预测错误,那么流水线中推测执行的那些中间结果全部放弃,重新获取正确的分支路线上的指令开始执行,这就带来了十几个时钟周期的延迟,这个时候,这个 CPU 核心就是完全在浪费时间。
幸运的是,当下的主流 CPU 在现代编译器的配合下,把这项工作做得越来越好了。
还记得那个让 Intel CPU 性能跌 30% 的漏洞补丁吗,那个漏洞就是 CPU 设计的时候,分支预测设计的不完善导致的。
多核 CPU
多核 CPU 的每一个核心拥有自己独立的运算单元、寄存器、一级缓存、二级缓存,所有核心共用同一条内存总线,同一段内存。
多核 CPU 的出现,标志着人类的集成电路工艺遇到了一个严酷的瓶颈,没法再大规模提升单核性能,只能使用多个核心来聊以自慰。实际上,多核 CPU 性能的提升极其有限,远不如增加一点点单核频率提升的性能多。
优势
多核 CPU 的优势很明显,就是可以并行地执行多个图灵机,可以显而易见地提升性能。只不过由于使用同一条内存总线,实际带来的效果有限,并且需要操作系统和编译器的密切配合才行。
题外话: AMD64 技术可以运行 32 位的操作系统和应用程序,所用的方法是依旧使用 32 位宽的内存总线,每计算一次要取两次内存,性能提升也非常有限,不过好处就是可以使用大于 4GB 的内存了。大家应该都没忘记第一篇文章中提到的冯·诺依曼架构拥有 CPU 和内存通信带宽不足的弱点。(注:AMD64 技术是和 Intel 交叉授权的专利,i7 也是这么设计的)
劣势
多核 CPU 劣势其实更加明显,但是人类也没有办法,谁不想用 20GHz 的 CPU 呢,谁想用这八核的 i7 呀。
内存读写效率不变,甚至有降低的风险
操作系统复杂度提升很多倍,计算资源的管理复杂了太多了
依赖操作系统的进步:微软以肉眼可见的速度,在这十几年间大幅提升了 Windows 的多核效率和安全性:XP 只是能利用,7 可以自动调配一个进程在多个核心上游走,2008R2 解决了依赖 CPU0 调度导致死机的 bug(中国的银行提的 bug 哦),8 可以利用多核心启动,10 优化了杀进程依赖 CPU0 的问题。
超线程技术
Intel 的超线程技术是将 CPU 核心内部再分出两个逻辑核心,只增加了 5% 的裸面积,就带来了 15%~30% 的性能提升。
怀念过去
Intel 肯定怀念摩尔定律提出时候的黄金年代,只依靠工艺的进步,就能一两年就性能翻番。AMD 肯定怀念 K8 的黄金一代,1G 战 4G,靠的就是把内存控制器从北桥芯片移到 CPU 内部,提升了 CPU 和内存的通信效率,自然性能倍增。而今天,人类的技术已经到达了一个瓶颈,只能通过不断的提升 CPU 和操作系统的复杂度来获得微弱的性能提升,呜呼哀哉。
不过我们也不能放弃希望,AMD RX VAGA64 显卡拥有 2048 位的显存位宽,理论极限还是很恐怖的,这可能就是未来内存的发展方向。
(三)通用电子计算机的胎记:事件驱动
Event-Driven(事件驱动)这个词这几年随着 Node.js® 的大热也成了一个热词,似乎已经成了「高性能」的代名词,殊不知事件驱动其实是通用计算机的胎记,是一种与生俱来的能力。本文我们就要一起了解一下事件驱动的价值和本质。
通用电子计算机中的事件驱动
首先我们定义当下最火的 x86 PC 机为典型的通用电子计算机:可以写文章,可以打游戏,可以上网聊天,可以读 U 盘,可以打印,可以设计三维模型,可以编辑渲染视频,可以作路由器,还可以控制巨大的工业机器。那么,这种计算机的事件驱动能力就很容易理解了:
假设 Chrome 正在播放 Youtube 视频,你按下了键盘上的空格键,视频暂停了。这个操作就是事件驱动:计算机获得了你单击空格的事件,于是把视频暂停了。
假设你正在跟人聊 QQ,别人发了一段话给你,计算机获得了网络传输的事件,于是将信息提取出来显示到了屏幕上,这也是事件驱动。
事件驱动的实现方式
事件驱动本质是由 CPU 提供的,因为 CPU 作为 控制器 + 运算器,他需要随时响应意外事件,例如上面例子中的键盘和网络。
CPU 对于意外事件的响应是依靠 Exception Control Flow(异常控制流)来实现的。
强大的异常控制流
异常控制流是 CPU 的核心功能,它是以下听起来就很牛批的功能的基础:
时间片
CPU 时间片的分配也是利用异常控制流来实现的,它让多个进程在宏观上在同一个 CPU 核心上同时运行,而我们都知道在微观上在任一个时刻,每一个 CPU 核心都只能运行一条指令。
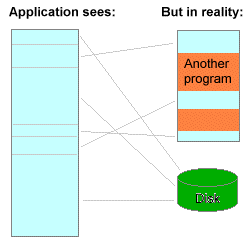
虚拟内存
这里的虚拟内存不是 Windows 虚拟内存,是 Linux 虚拟内存,即逻辑内存。
逻辑内存是用一段内存和一段磁盘上的存储空间放在一起组成一个逻辑内存空间,对外依然表现为「线性数组内存空间」。逻辑内存引出了现代计算机的一个重要的性能观念:
内存局部性天然的让相邻指令需要读写的内存空间也相邻,于是可以把一个进程的内存放到磁盘上,再把一小部分的「热数据」放到内存中,让其作为磁盘的缓存,这样可以在降低很少性能的情况下,大幅提升计算机能同时运行的进程的数量,大幅提升性能。
虚拟内存的本质其实是使用 缓存 + 乐观 的手段提升计算机的性能。
系统调用
系统调用是进程向操作系统索取资源的通道,这也是利用异常控制流实现的。
硬件中断
键盘点击、鼠标移动、网络接收到数据、麦克风有声音输入、插入 U 盘这些操作全部需要 CPU 暂时停下手头的工作,来做出响应。
进程、线程
进程的创建、管理和销毁全部都是基于异常控制流实现的,其生命周期的钩子函数也是操作系统依赖异常控制流实现的。线程在 Linux 上和进程几乎没有功能上的区别。
编程语言中的 try catch
C++ 编译成的二进制程序,其异常控制语句是直接基于异常控制流的。Java 这种硬虚拟机语言,PHP 这种软虚拟机语言,其异常控制流的一部分也是有最底层的异常控制流提供的,另一部分可以由逻辑判断来实现。
基于异常控制流的事件驱动
其实现在人们在谈论的事件驱动,是 Linux kernel 提供的 epoll,是 2002 年 10 月 18 号伴随着 kernel 2.5.44 发布的,是 Linux 首次将操作系统中的 I/O 事件的异常控制流暴露给了进程,实现了本文开头提到的 Event-Driven(事件驱动)。
Kqueue
FreeBSD 4.1 版本于 2000 年发布,起携带的 Kqueue 是 BSD 系统中事件驱动的 API 提供者。BSD 系统如今已经遍地开花,从 macOS 到 iOS,从 watchOS 到 PS4 游戏机,都受到了 Kqueue 的蒙荫。
epoll 是什么
操作系统本身就是事件驱动的,所以 epoll 并不是什么新发明,而只是把本来不给用户空间用的 api 暴露在了用户空间而已。
epoll 做了什么
网络 IO 是一种纯异步的 IO 模型,所以 Nginx 和 Node.js® 都基于 epoll 实现了完全的事件驱动,获得了相比于 select/poll 巨量的性能提升。而磁盘 IO 就没有这么幸运了,因为磁盘本身也是单体阻塞资源:即有进程在写磁盘的时候,其他写入请求只能等待,就是天王老子来了也不行,磁盘做不到呀。所以磁盘 IO 是基于 epoll 实现的非阻塞 IO,但是其底层依旧是异步阻塞,即便这样,性能也已经爆棚了。Node.js 的磁盘 IO 性能远超其他解释型语言,过去几年在 web 后端霸占了一些对磁盘 IO 要求高的领域。
(四)Unix 进程模型的局限
Unix 系统 1969 年诞生于 AT&T 旗下的贝尔实验室。1971 年,Ken Thompson(Unix 之父)和 Dennis Ritchie(C 语言之父)共同发明了 C 语言,并在 1973 年用 C 语言重写了 Unix。
Unix 自诞生起就是多用户、多任务的分时操作系统,其引入的「进程」概念是计算机科学中最成功的概念之一,几乎所有现代操作系统都是这一概念的受益者。但是进程也有局限,由于 AT&T 是做电话交换起家,所以 Unix 进程在设计之初就是延续的电话交换这个业务需求:保证电话交换的效率,就够了。
1984 年,Richard Stallman 发起了 GNU 项目,目标是创建一个完全自由且向下兼容 Unix 的操作系统。之后 Linus Torvalds 与 1991 年发布了 Linux 内核,和 GNU 结合在了一起形成了 GNU/Linux 这个当下最成功的开源操作系统。所以 Redhat、CentOS、Ubuntu 这些如雷贯耳的 Linux 服务器操作系统,他们的内存模型也是高度类似 Unix 的。
Unix 进程模型介绍
进程是操作系统提供的一种抽象,每个进程在自己看来都是一个独立的图灵机:独占 CPU 核心,一个一个地运行指令,读写内存。进程是计算机科学中最重要的概念之一,是进程使多用户、多任务成为了可能。
上下文切换
操作系统使用上下文切换让一个 CPU 核心上可以同时运行多个进程:在宏观时间尺度,例如 5 秒内,一台电脑的用户会认为他的桌面进程、音乐播放进程、鼠标响应进程、浏览器进程是在同时运行的。

图片来自《CS:APP》
上下文切换的过程
以下就是 Linux 上下文切换的过程:
假设正在运行网易云音乐进程,你突然想搜歌,假设焦点已经位于搜索框内。
当前进程是网易云音乐,它正在优哉游哉的播放着音乐
你突然打字,CPU 接到键盘发起的中断信号(异常控制流中的一个异常),准备调起键盘处理进程
将网易云音乐进程的寄存器、栈指针、程序计数器保存到内存中
将键盘处理进程的寄存器、栈指针、程序计数器从内存中读出来,写入到 CPU 内部相应的模块中
执行程序计数器的指令,键盘处理程序开始处理键盘输入
完成了一次上下文切换
名词解释
寄存器:CPU 核心里的用于暂时存储指令、地址和数据的电路,和内核频率一样,速度极快
栈指针:该进程所拥有的栈的指针
程序计数器:简称 PC,它存储着内核将要执行的下一个指令的内存地址。程序计数器是图灵机的核心组成部分。还记得冯·诺依曼架构吗,它的一大创造就是把指令和数据都存在内存里,让计算机获得了极大的自由度。
Unix 进程模型的局限
Unix 进程模型十分的清晰,上下文切换使用了一个非常简单的操作就实现了多个进程的宏观同时运行,是一个伟大的杰作。但是它却存在着一个潜在的缺陷,这个缺陷在 Unix 诞生数十年之后才渐渐浮出了水面。
致命的内存
进程切换过程中需要分别写、读一次内存,这个操作在 Unix 刚发明的时候没有发现有什么性能问题,但是 CPU 裹挟着摩尔定律一路狂奔,2000 年,AMD 领先 Intel 两天发布了第一款 1GHz 的微处理器「AMD Athlon 1GHz」,此时一个指令的执行时间已经低到了 1ns,而其内存延迟高达 60ns,这导致了一个以前不曾出现的问题:
上下文切换读写内存的时间成了整个系统的性能瓶颈。
软件定义一切
我们将在下一篇文章探讨 SDN(软件定义网络),在这里我们先来看一下「软件定义一切」这个概念。当下,不仅有软件定义网络,还有软件定义存储,甚至出现了软件定义基础架构(这不就是云计算嘛)。是什么导致了软件越来越强势,开始倾入过去只有专业的硬件设备才能提供的高性能高稳定性服务呢?我认为,就是通用计算机的发展导致的,确切地说,是 CPU 和网络的发展导致的。
当前的民用顶级 CPU 的性能已经爆表,因为规模巨大,所以其价格也要显著低于同性能的专用处理器:自建 40G 软路由的价格大约是 40G 专用路由价格的二十分之一。
(五)DPDK、SDN 与大页内存
上文我们说到,当今的 x86 通用微处理器已经拥有了十分强大的性能,得益于其庞大的销量,让它的价格和专用 CPU 比也有着巨大的优势,于是,软件定义一切诞生了!
软路由
说到软路由,很多人都露出了会心的微笑,因为其拥有低廉的价格、超多的功能、够用的性能和科学上网能力。现在网上能买到的软路由,其本质就是一个 x86 PC 加上多个网口,大多是基于 Linux 或 BSD 内核,使用 Intel 低端被动散热 CPU 打造出的千兆路由器,几百块就能实现千兆的性能,最重要的是拥有 QOS、多路拨号、负载均衡、防火墙、VPN 组网、科学上网等强大功能,传统路由器抛开科学上网不谈,其他功能也不是几百块就搞得定的。
软路由的弱点
软路由便宜,功能强大,但是也有弱点。它最大的弱点其实是性能:传统 *UNIX 网络栈的性能实在是不高。
软路由的 NAT 延迟比硬路由明显更大,而且几百块的软路由 NAT 性能也不够,跑到千兆都难,而几百块的硬路由跑到千兆很容易。那怎么办呢?改操作系统啊。
SDN
软件定义网络,其本质就是使用计算机科学中最常用的「虚拟机」构想,将传统由硬件实现的 交换、网关、路由、NAT 等网络流量控制流程交由软件来统一管理:可以实现硬件不动,网络结构瞬间变化,避免了传统的停机维护调试的烦恼,也为大规模公有云计算铺平了道路。
虚拟机
虚拟机的思想自底向上完整地贯穿了计算机的每一个部分,硬件层有三个场效应管虚拟出的 SRAM、多个内存芯片虚拟出的一个「线性数组内存」,软件层有 jvm 虚拟机,PHP 虚拟机(解释器)。自然而然的,当网络成为了更大规模计算的瓶颈的时候,人们就会想,为什么网络不能虚拟呢?
OpenFlow
最开始,SDN 还是基于硬件来实施的。Facebook 和 Google 使用的都是 OpenFlow 协议,作用在数据链路层(使用 MAC 地址通信的那一层,也就是普通交换机工作的那一层),它可以统一管理所有网关、交换等设备,让网络架构实时地做出改变,这对这种规模的公司所拥有的巨大的数据中心非常重要。
DPDK
DPDK 是 SDN 更前沿的方向:使用 x86 通用 CPU 实现 10Gbps 甚至 40Gbps 的超高速网关(路由器)。
DPDK 是什么
Intel DPDK 全称为 Intel Data Plane Development Kit,直译为「英特尔数据平面开发工具集」,它可以摆脱 *UNIX 网络数据包处理机制的局限,实现超高速的网络包处理。

DPDK 的价值
当下,一台 40G 核心网管路由器动辄数十万,而 40G 网卡也不会超过一万块,而一颗性能足够的 Intel CPU 也只需要几万块,软路由的性价比优势是巨大的。
实际上,阿里云和腾讯云也已经基于 DPDK 研发出了自用的 SDN,已经创造了很大的经济价值。
怎么做到的?
DPDK 使用自研的数据链路层(MAC 地址)和网络层(ip 地址)处理功能(协议栈),抛弃操作系统(Linux,BSD 等)提供的网络处理功能(协议栈),直接接管物理网卡,在用户态处理数据包,并且配合大页内存和 NUMA 等技术,大幅提升了网络性能。有论文做过实测,10G 网卡使用 Linux 网络协议栈只能跑到 2G 多,而 DPDK 分分钟跑满。
用户态网络栈
上篇文章我们已经说到,Unix 进程在网络数据包过来的时候,要进行一次上下文切换,需要分别读写一次内存,当系统网络栈处理完数据把数据交给用户态的进程如 Nginx 去处理还会出现一次上下文切换,还要分别读写一次内存。夭寿啦,一共 1200 个 CPU 周期呀,太浪费了。
而用户态协议栈的意思就是把这块网卡完全交给一个位于用户态的进程去处理,CPU 看待这个网卡就像一个假肢一样,这个网卡数据包过来的时候也不会引发系统中断了,不会有上下文切换,一切都如丝般顺滑。当然,实现起来难度不小,因为 Linux 还是分时系统,一不小心就把 CPU 时间占完了,所以需要小心地处理阻塞和缓存问题。
NUMA
NUMA 来源于 AMD Opteron 微架构,其特点是将 CPU 直接和某几根内存使用总线电路连接在一起,这样 CPU 在读取自己拥有的内存的时候就会很快,代价就是读取别 U 的内存的时候就会比较慢。这个技术伴随着服务器 CPU 核心数越来越多,内存总量越来越大的趋势下诞生的,因为传统的模型中不仅带宽不足,而且极易被抢占,效率下降的厉害。

NUMA 利用的就是电子计算机(图灵机 + 冯·诺依曼架构)天生就带的涡轮:局部性。涡轮:汽车发动机加上涡轮,可以让动力大增油耗降低
细说大页内存
内存分页
为了实现虚拟内存管理机制,前人们发明了内存分页机制。这个技术诞生的时候,内存分页的默认大小是 4KB,而到了今天,绝大多数操作系统还是用的这个数字,但是内存的容量已经增长了不知道多少倍了。
TLB miss
TLB(Translation Lookaside Buffers)转换检测缓冲区,是内存控制器中为增虚拟地址到物理地址的翻译速度而设立的一组电子元件,最近十几年已经随着内存控制器被集成到了 CPU 内部,每颗 CPU 的 TLB 都有固定的长度。
如果缓存未命中(TLB miss),则要付出 20-30 个 CPU 周期的带价。假设应用程序需要 2MB 的内存,如果操作系统以 4KB 作为分页的单位,则需要 512 个页面,进而在 TLB 中需要 512 个表项,同时也需要 512 个页表项,操作系统需要经历至少 512 次 TLB Miss 和 512 次缺页中断才能将 2MB 应用程序空间全部映射到物理内存;然而,当操作系统采用 2MB 作为分页的基本单位时,只需要一次TLB Miss 和一次缺页中断,就可以为 2MB 的应用程序空间建立虚实映射,并在运行过程中无需再经历 TLB Miss 和缺页中断。
大页内存
大页内存 HugePage 是一种非常有效的减少 TLB miss 的方式,让我们来进行一个简单的计算。
2013 年发布的 Intel Haswell i7-4770 是当年的民用旗舰 CPU,其在使用 64 位 Windows 系统时,可以提供 1024 长度的 TLB,如果内存页的大小是 4KB,那么总缓存内存容量为 4MB,如果内存页的大小是 2MB,那么总缓存内存容量为 2GB。显然后者的 TLB miss 概率会低得多。
DPDK 支持 1G 的内存分页配置,这种模式下,一次性缓存的内存容量高达 1TB,绝对够用了。
不过大页内存的效果没有理论上那么惊人,DPDK 实测有 10%~15% 的性能提升,原因依旧是那个天生就带的涡轮:局部性。
(六)现代计算机最亲密的伙伴:局部性与乐观
冯·诺依曼架构中,指令和数据均存储在内存中,彻底打开了计算机「通用」的大门。这个结构中,「线性数组」内存天生携带了一个涡轮:局部性。
局部性分类
空间局部性
空间局部性是最容易理解的局部性:如果一段内存被使用,那么之后,离他最近的内存也最容易被使用,无论是数据还是指令都是这样。举一个浅显易懂的例子:
循环处理一个 Array,当处理完了 [2] 之后,下一个访问的就是 [3],他们在内存里是相邻的。
时间局部性
如果一个变量所在的内存被访问过,那么接下来这一段内存很可能被再次访问,例子也非常简单:
$a = [];if ( !$b ) {$a[] = $b;}
在一个 function 内,一个内存地址很可能被访问、修改多次。
乐观
「乐观」作为一种思考问题的方式广泛存在于计算机中,从硬件设计、内存管理、应用软件到数据库均广泛运用了这种思考方式,并给我们带来了十分可观的性能收益。
乐观的 CPU
第一篇文章中的 L1 L2 L3 三级缓存和第二篇文章中的分支预测与流水线,均是乐观思想的代表。
乐观的虚拟内存
虚拟内存依据计算机内存的局部性,将磁盘作为内存的本体,将内存作为磁盘的缓存,用很小的性能代价带来了数十倍并发进程数,是乐观思想的集大成者。
乐观的缓存
Java 经典面试题 LRU 缓存实现,也是乐观思想的一种表达。
同样,鸟哥的 yac 也是这一思想的强烈体现。
设计 Yac 的经验假设
对于一个应用来说, 同名的 Cache 键, 对应的 Value, 大小几乎相当.
不同的键名的个数是有限的.
Cache 的读的次数, 远远大于写的次数.
Cache 不是数据库, 即使 Cache 失效也不会带来致命错误.
Yac 的限制
key 的长度最大不能超过 48 个字符. (我想这个应该是能满足大家的需求的, 如果你非要用长 Key, 可以 MD5 以后再存)
Value 的最大长度不能超过 64M, 压缩后的长度不能超过 1M.
当内存不够的时候, Yac 会有比较明显的踢出率, 所以如果要使用 Yac, 那么尽量多给点内存吧.
乐观锁
乐观锁在并发控制和数据库设计里都拥有重要地位,其本质就是在特定的需求下,假定不会冲突,冲突之后再浪费较长时间处理,比直接每次请求都浪费较短时间检测,总体的性能高。乐观锁在算法领域有着非常丰富而成熟的应用。
乐观的分布式计算
分布式计算的核心思想就是乐观,由 95% 可靠的 PC 机组成的分布式系统,起可靠性也不会达到 99.99%,但是绝大多数场景下,99% 的可靠性就够了,毕竟拿 PC 机做分布式比小型机便宜得多嘛。下一篇文章我会详细介绍分布式计算的性能之殇,此处不再赘述。
乐观的代价
出来混,早晚是要还的。
乐观给了我们很多的好处,总结起来就是一句话:以微小的性能损失换来大幅的性能提升。但是,人在河边走,哪有不湿鞋。每一个 2015 年 6 月入 A 股的散户,都觉得大盘还能再翻一番,岂不知一周之后,就是股灾了。
乐观的代价来自于「微小的性能损失」,就跟房贷市场中「微小的风险」一样,当大环境小幅波动的时候,他确实能承担压力,稳住系统,但是怕就怕突然雪崩:
虚拟内存中的内存的局部性突然大幅失效,磁盘读写速度成了内存读写速度,系统卡死
分布式数据库的六台机器中的 master 挂了,系统在一秒内选举出了新的 master,你以为系统会稳定运行?master 挂掉的原因就是压力过大,这样就会导致新的 master 瞬间又被打挂,然后一台一台地继续,服务彻底失效。例如:「故障说明」对六月六日 LeanCloud 多项服务发生中断的说明
(七)分布式计算、超级计算机与神经网络共同的瓶颈
分布式计算是这些年的热门话题,各种大数据框架层出不穷,容器技术也奋起直追,各类数据库(Redis、ELasticsearch、MongoDB)也大搞分布式,可以说是好不热闹。分布式计算在大热的同时,也存在着两台机器也要硬上 Hadoop 的「面向简历编程」,接下来我就剖析一下分布式计算的本质,以及我的理解和体会。
分布式计算的本质
分布式计算来源于人们日益增长的性能需求与落后的 x86 基础架构之间的矛盾。恰似设计模式是面向对象对现实问题的一种妥协。
x86 服务器
x86 服务器,俗称 PC 服务器、微机服务器,近二十年以迅雷不及掩耳盗铃之势全面抢占了绝大部分的服务器市场,它和小型机比只有一个优势,其他的全是缺点,性能、可靠性、可扩展性、占地面积都不如小型机,但是一个优势就决定了每年 2000 多亿美元的 IDC 市场被 x86 服务器占领了 90%,这个优势就是价格。毕竟有钱能使磨推鬼嘛。
现有的分布式计算,无论是 Hadoop 之类的大数据平台,还是 HBase 这样的分布式数据库,无论是 Docker 这种容器排布,还是 Redis 这种朴素分布式数据库,其本质都是因为 x86 的扩展性不够好,导致大家只能自己想办法利用网络来自己构建一个宏观上更强性能更高负载能力的计算机。
x86 分布式计算,是一种新的计算机结构。
基于网络的 x86 服务器分布式计算,其本质是把网络当做总线,设计了一套新的计算机体系结构:
每一台机器就等于一个运算器加一个存储器
master 节点就是控制器加输入设备、输出设备
x86 分布式计算的弱点
上古时代,小型机的扩展能力是非常变态的,到今天,基于小型机的 Oracle 数据库系统依旧能做到惊人的性能和可靠性。实际上单颗 x86 CPU 的性能已经远超 IBM 小型机用的 PowerPC,但是当数量来到几百颗,x86 服务器集群就败下阵来,原因也非常简单:
小型机是专门设计的硬件和专门设计的软件,只面向这种规模(例如几百颗 CPU)的计算
小型机是完全闭源的,不需要考虑扩展性,特定的几种硬件在稳定性上前进了一大步
x86 的 IO 性能被架构锁死了,各种总线、PCI、PCIe、USB、SATA、以太网,为了个人计算机的便利性,牺牲了很多的性能和可靠性
小型机使用总线通信,可以实现极高的信息传递效率,极其有效的监控以及极高的故障隔离速度
x86 服务器基于网络的分布式具有天然的缺陷:
操作系统决定了网络性能不足
网络需要使用事件驱动处理,比总线电路的延迟高几个数量级
PC 机的硬件不够可靠,故障率高
很难有效监控,隔离故障速度慢
x86 分布式计算的基本套路
Google 系大数据处理框架
2003 年到 2004 年间,Google 发表了 MapReduce、GFS(Google File System)和 BigTable 三篇技术论文,提出了一套全新的分布式计算理论。MapReduce 是分布式计算框架,GFS(Google File System)是分布式文件系统,BigTable 是基于 Google File System 的数据存储系统,这三大组件组成了 Google 的分布式计算模型。
Hadoop、Spark、Storm 是目前最重要的三大分布式计算系统,他们都是承袭 Google 的思路实现并且一步一步发展到今天的。
MapReduce 的基本原理也十分简单:将可以并行执行的任务切分开来,分配到不同的机器上去处理,最终再汇总结果。而 GFS 是基于 Master-Slave 架构的分布式文件系统,其 master 只扮演控制者的角色,操控着所有的 slave 干活。
Redis、MongoDB 的分布式
Redis 有两个不同的分布式方案。Redis Cluster 是官方提供的工具,它通过特殊的协议,实现了每台机器都拥有数据存储和分布式调节功能,性能没有损失。缺点就是缺乏统一管理,运维不友好。Codis 是一个非常火的 Redis 集群搭建方案,其基本原理可以简单地描述如下:通过一个 proxy 层,完全隔离掉了分布式调节功能,底层的多台机器可以任意水平扩展,运维十分友好。
MongoDB 官方提供了一套完整的分布式部署的方案,提供了 mongos 控制中心,config server 配置存储,以及众多的 shard(其底层一般依然有两台互为主从强数据一致性的 mongod)。这三个组件可以任意部署在任意的机器上,MongoDB 提供了 master 选举功能,在检测到 master 异常后会自动选举出新的 master 节点。
问题和瓶颈
人们费这么大的劲研究基于网络的 x86 服务器分布式计算,目的是什么?还不是为了省钱,想用一大票便宜的 PC 机替换掉昂贵的小型机、大型机。虽然人们已经想尽了办法,但还是有一些顽固问题无法彻底解决。
master 失效问题
无论怎样设计,master 失效必然会导致服务异常,因为网络本身不够可靠,所以监控系统的容错要做的比较高,所以基于网络的分布式系统的故障恢复时间一般在秒级。而小型机的单 CPU 故障对外是完全无感的。
现行的选举机制主要以节点上的数据以及节点数据之间的关系为依据,通过一顿猛如虎的数学操作,选举出一个新的 master。逻辑上,选举没有任何问题,如果 master 因为硬件故障而失效,新的 master 会自动顶替上,并在短时间内恢复工作。
而自然界总是狠狠地打人类的脸:
硬件故障概率极低,大部分 master 失效都不是因为硬件故障
如果是流量过大导致的 master 失效,那么选举出新的 master 也无济于事:提升集群规模才是解决之道
即使能够及时地在一分钟之内顶替上 master 的工作,那这一分钟的异常也可能导致雪崩式的 cache miss,从磁盘缓存到虚拟内存,从 TLB 到三级缓存,再到二级缓存和一级缓存,全部失效。如果每一层的失效会让系统响应时间增加五倍的话,那最终的总响应时长将是惊人的。
系统规模问题
无论是 Master-Slave 模式还是 Proxy 模式,整个系统的流量最终还是要落到一个特定的资源上。当然这个资源可能是多台机器,但是依旧无法解决一个严重的问题:系统规模越大,其本底性能损失就越大。
这其实是我们所在的这个宇宙空间的一个基本规律。我一直认为,这个宇宙里只有一个自然规律:熵增。既然我们这个宇宙是一个熵增宇宙,那么这个问题就无法解决。
超级计算机
超级计算机可以看成一个规模特别巨大的分布式计算系统,他的性能瓶颈从目前的眼光来看,是超多计算核心(数百万)的调节效率问题。其本质是通信速率不够快,信息传递的太慢,让数百万核心一起工作,传递命令和数据的工作占据了绝大多数的运行时间。
神经网络
深度学习这几年大火,其原因就是卷积神经网络(CNN)造就的 AlphaGo 打败了人类,计算机在这个无法穷举的游戏里彻底赢了。伴随着 Google 帝国的强大推力,深度学习,机器学习,乃至人工智能,这几个词在过去的两年大火,特别是在中美两国。现在拿手机拍张照背后都有机器学习你敢信?
机器学习的瓶颈,本质也是数据交换:机器学习需要极多的计算,而计算速度的瓶颈现在就在运算器和存储器的通信上,这也是显卡搞深度学习比 CPU 快数十倍的原因:显存和 GPU 信息交换的速度极快。
九九归一
分布式系统的性能问题,表现为多个方面,但是归根到底,其原因只是一个非常单纯的矛盾:人们日益增长的性能需求和数据一致性之间的矛盾。一旦需要强数据一致性,那就必然存在一个限制性能的瓶颈,这个瓶颈就是信息传递的速度。
同样,超级计算机和神经网络的瓶颈也都是信息传递的速度。
那么,信息传递速度的瓶颈在哪里呢?
我个人认为,信息传递的瓶颈最表层是人类的硬件制造水平决定的,再往底层去是冯·诺依曼架构决定的,再往底层去是图灵机的逻辑模型决定的。可是图灵机是计算机可行的理论基础呀,所以,还是怪这个熵增宇宙吧,为什么规模越大维护成本越高呢,你也是个成熟的宇宙了,该学会自己把自己变成熵减宇宙了。

原文链接:
https://lvwenhan.com/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/492.html
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~