将整本《绿野仙踪》存入纳米级DNA中,高效准确,读取无压力
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
如何将一整本《绿野仙踪》,存进纳米级的DNA里?

现在,德克萨斯大学奥斯汀分校的科学家们做到了。
他们开创了一套新的DNA数据编码和解码方法,不仅非常高效,还可以长期保存数据。
最关键的突破在于,准确率也非常高。
DNA技术近些年之所以受到关注,是因为它具有不可忽视的潜力:存储密度大。
例如,一个鞋盒能装下的所有DNA,足以保存100个大型数据中心的所有数据。
但这项技术除了昂贵,还有个最大的问题:错误率高。
光是插入和删除两种错误,就占据DNA合成错误的50%以上。
而这套新的DNA数据编解码方法,专门针对DNA合成错误进行修复,使得数据在被存储后,还能完好地被提取出来。(文末附论文链接)
一起来看看这种方法的妙处。
DNA合成:两大瓶颈
成本昂贵
事实上,微软在2016年就已经利用DNA存储技术完成了约200MB数据的保存,包括《战争与和平》等。
作为一种优良的存储介质,DNA不仅能实现更高的存储密度,而且还具有良好的耐久性,40万年前的古人类基因也能被重建。

如果反过来,想要将数据存储在DNA中,基本方法就是将0和1转换为4种核苷酸(碱基组成的序列)。
不过,虽然微软没公布200MB数据合成的成本,那会儿每个碱基的价格通常在0.7元左右。
而200MB数据的保存,用了大约15亿个碱基……
如此昂贵的DNA合成价格,却只能保存200MB的数据,相比之下,几百元的硬盘它不香吗?
不过,成本起码会随技术发展下降,最关键的问题,还是DNA合成的错误率高。
错误率高
在DNA合成过程中,存在替换、插入与删除三种常见的错误。
来看看这3种错误产生的方式。
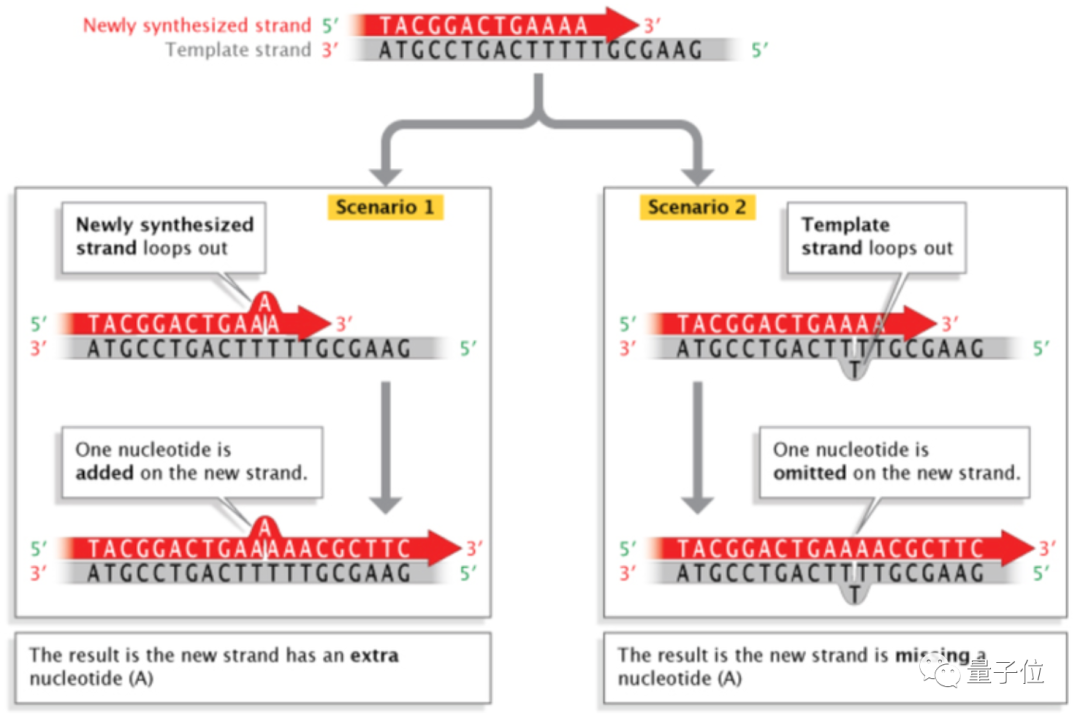
在DNA复制过程中,如果其中一条链「手滑」了,就会产生插入和删除错误。
插入:下图左,由于子链在复制过程中「滑动」了一下,原本已经合进子链的腺嘌呤(A)被拱了起来,导致原来的位置上多了一个腺嘌呤(A);
删除:下图右,由于母链在复制过程中「滑动」了一下,导致一个胸腺嘧啶(T)还没被复制就被跳过了,子链上少了个腺嘌呤(A)。
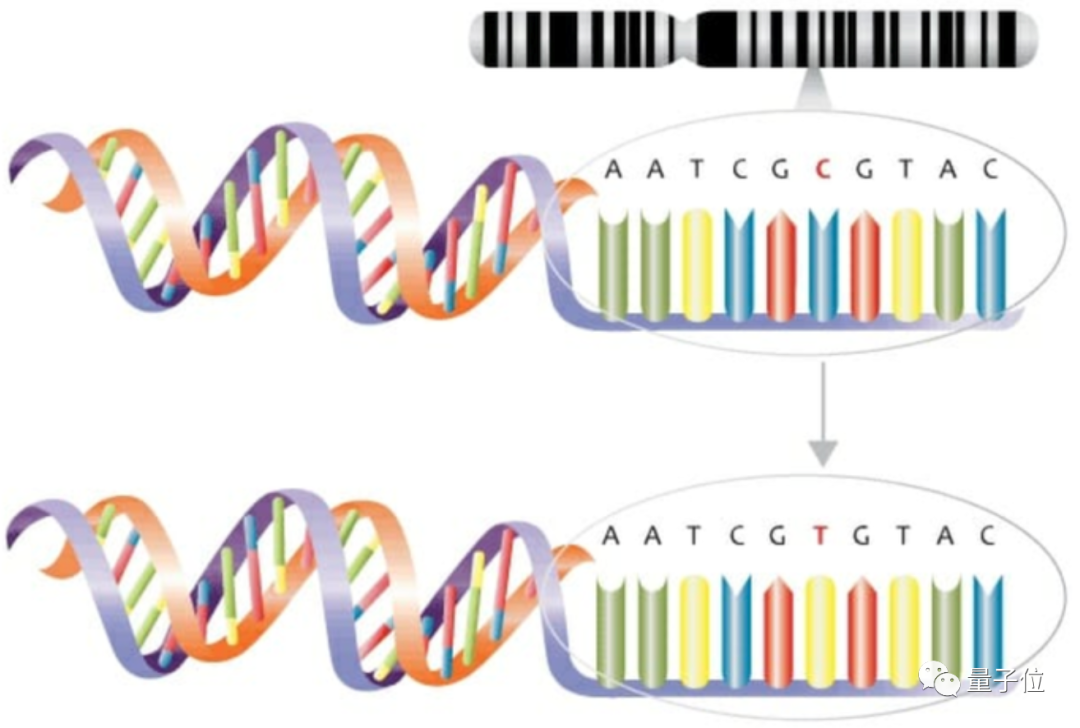
下图是一种替换错误,DNA中将胞嘧啶(C)替换成了胸腺嘧啶(T)。
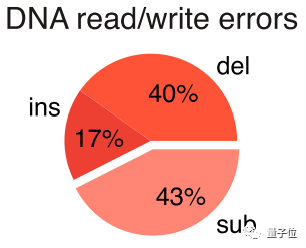
而根据统计,在DNA合成会出现的错误中,插入和删除的错误占据了57%。
以往虽然也有针对DNA合成的纠错方式,但效率不高。
好消息是,现在科学家们研究出了一种新的编解码方式HEDGES,全名Hash Encoded, Decoded by Greedy Exhaustive Search,可以更高效地将数据合入DNA,或取出来。
HEDGES高效纠错
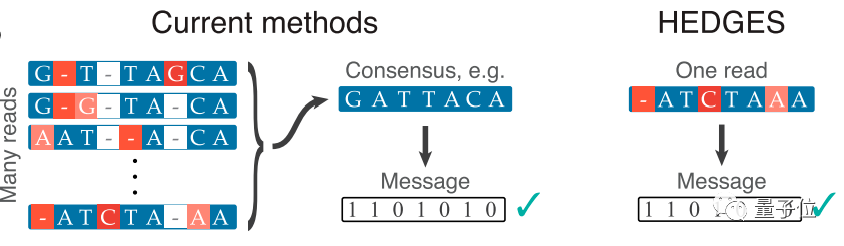
下图是在解码时,传统纠错方式和HEDGES纠错方式的对比。
其中,红色部分是发生替换、插入或删除错误的地方,蓝色部分是正确序列。
从图中可见,传统DNA合成在解码纠错时,需要对一条链进行多次合成,然后进行比对,得出正确率高的正确碱基对,从而降低错误率。
但HEDGES只需要进行单次读取,就能将发生缺失、删除和替换错误的地方纠正过来,并得出正确的信息。
这种高效纠错的能力,与HEDGES编解码的方式密不可分。
HEDGES编解码依据的是一种自动加密算法,这种算法在古代战事中很常见:
假设一方要传递「黎明时进攻」的明文,现在双方已知关键词是「QUEENLY」,那么密钥就是「QUEENLY+明文」,加密时,用维吉尼亚密码把「明文+密钥」翻译成密文。

然后,对方只需要掌握“QUEENLY”和密文,就能将明文解密出来了。
不过,这种算法用于DNA编码时,会出现冗余的情况,例如,在半速率编码(每个核苷酸编码1比特数据)时,如果输入1比特数据,则会输出2比特的数据量。
接下来,采用哈希算法,结合数据本身、数据所在DNA链的ID和先前数据,做个「数字签名」,就能保障数据传递的安全性,如下图。
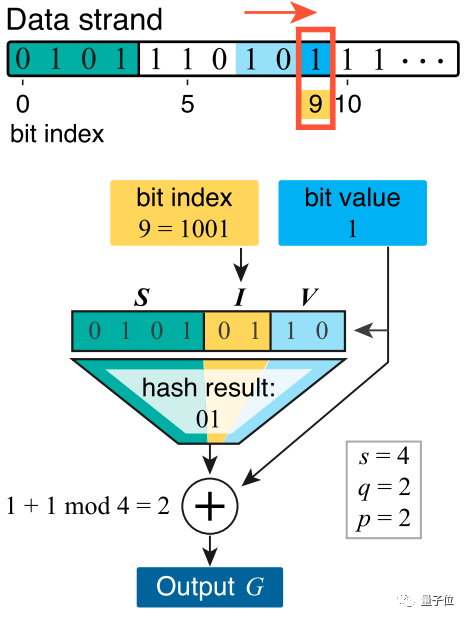
而DNA进行解码的过程,实际上类似于自动加密算法的破译过程,将所有合成过程中可能出现的「错误」列出来,一一进行排查。
解码中会出现删除、插入的错误,下图就出现了插入错误。
这时候,经过哈希算法加密的「数字签名」,可以排除掉不正确的解码假设。
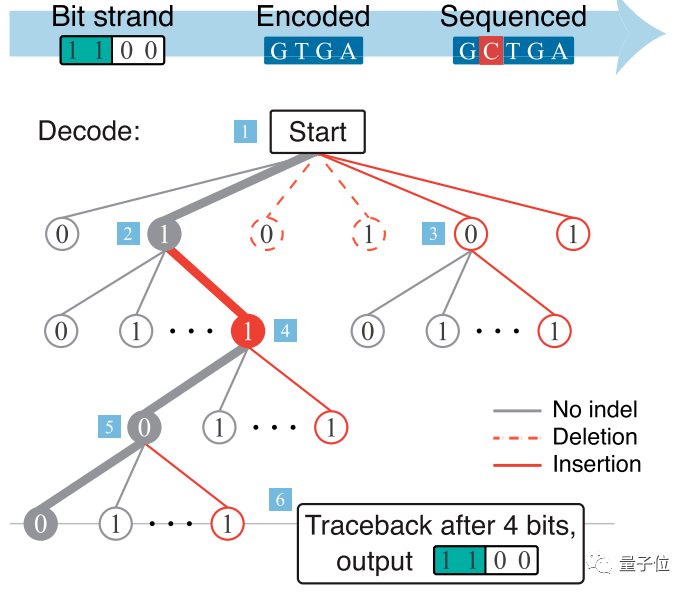
例如,包含数据所在链的ID部分,在解码时,如果发现解码得出的链ID与「数字签名」包含的ID信息不一致,这一系列错误假设就会直接被「解决掉」。
这样,就能纠正在解码过程中出现的插入和删除的错误。
当然,这只是数据编解码的过程,除此之外,团队在外部存储方式上也设计了新方法。
首先,输入的各种类型的数据信息会被转换成特定数据存储格式,然后通过一种名为RS(Reed–Solomon)的外部方式,进行基于DNA的存储。
这种类似于「对角线」一样的存储方式,使得合成过程中产生的错误能更均匀地分布,并被测量出来,提高了纠错性能。
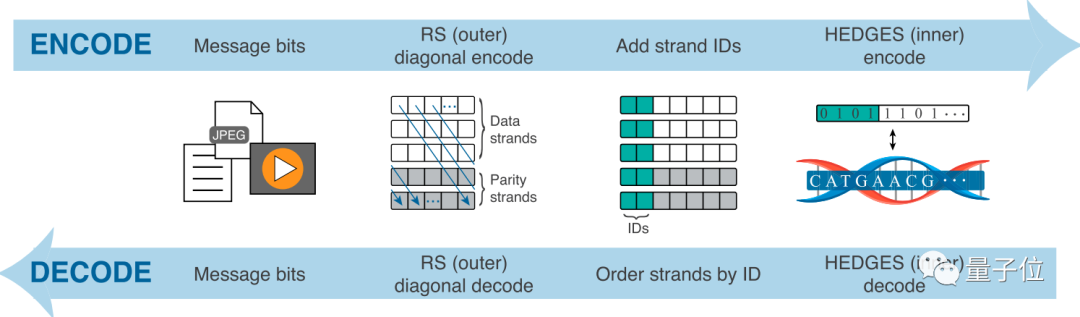
正是通过这种编解码方法,团队成功完成了《绿野仙踪》的DNA数据存储、解读。
结果耐温稳定
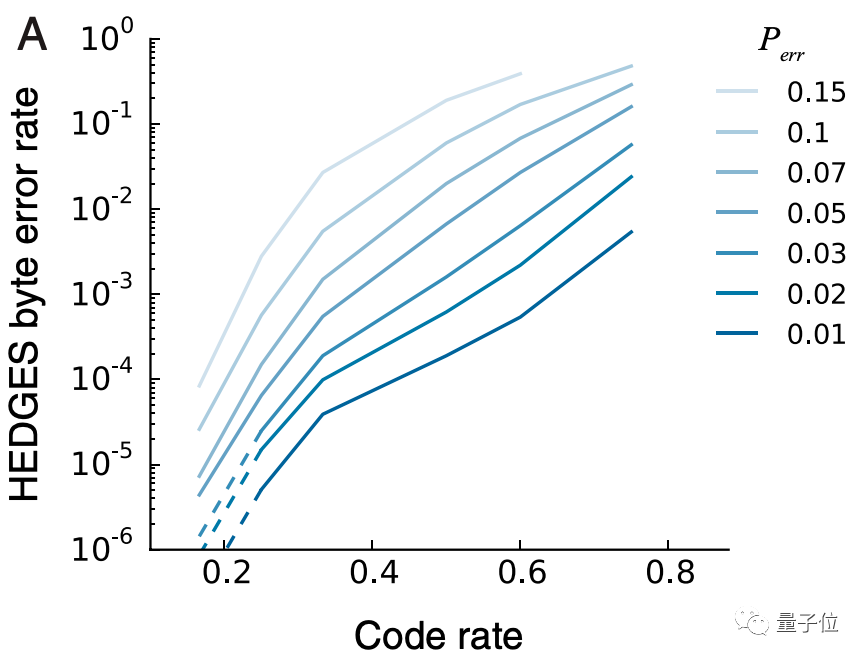
从结果来看,整体错误率基本只有1%,而且在温度诱变的情况下,经过2小时和8小时,错误率上升基本在0.1%左右,非常稳定。
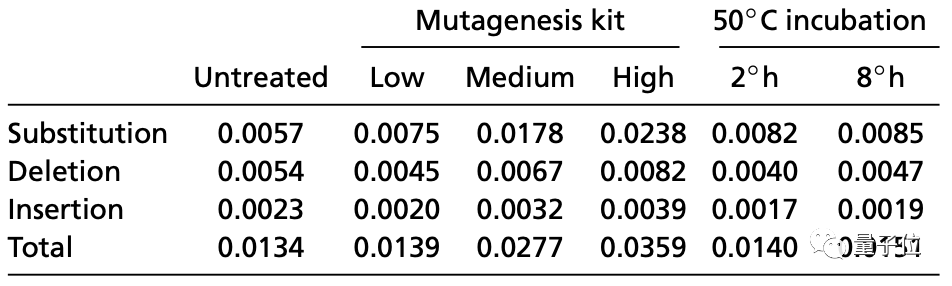
而从整体数据来看,采用HEDGES进行编码,在编码率小于0.2、每个核苷酸出错概率Perr小于0.01的时候,错误率理论上能逼近0。
看起来,DNA数据存储,未来说不定真能取代硬盘。
作者介绍

论文一作是William H. Press,美国国家科学院院士,1948年出生,毕业于哈佛大学,并于1972年在加州理工学院取得博士学位。
Press教授曾在哈佛大学任教天文物理学20余年,在广义相对论和天体物理学方面都有所建树。自2007年后,在德克萨斯大学奥斯汀分校任教,目前是计算机科学和合成生物学的教授。
论文链接:
https://www.pnas.org/content/pnas/early/2020/07/15/2004821117.full.pdf
参考链接:
https://www.popularmechanics.com/science/a33327626/scientists-encoded-wizard-of-oz-in-dna/
https://spectrum.ieee.org/nanoclast/semiconductors/memory/dna-data-storage-method-sets-standard-for-highdensity-data-future
https://en.wikipedia.org/wiki/William_H._Press
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
报名 |「隐私计算+AI」技术直播
不了解任何隐私AI技术的情况下,开发者怎样做到只改动两三行代码,就将现有AI代码转换为具备数据隐私保护功能的程序?


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !

