瑞士小哥开源文本英雄Texthero:一行代码完成数据预处理,网友:早用早下班!

新智元报道
新智元报道
来源:GitHub
编辑: 白峰
【新智元导读】自然语言处理任务的数据通常是杂乱无章的,而文本预处理要消耗大量的时间和精力。近日,GitHub上开源了一个NLP工具箱Texthero,不仅功能完善一个pipeline完成所有操作,速度还超快堪比SpaCy,一起来尝鲜吧!
NLPer最头疼的可能就是数据预处理了,拿到的多源数据通常长下面这样,乱成一团。

「我只想远离我的数据集,休息一下。」
如果你已经处理过文本数据并应用过一些机器学习算法,那么你肯定了解「NLP 管道」是多么复杂。
你通常需要写一堆正则表达式来清理数据,使用 NLTK、 SpaCy 或 Textblob 预处理文本,使用 Gensim (word2vec)或 sklearn (tf-idf、 counting 等)将文本向量化。
即使对于 Python 专家来说,如果考虑不周全,不理解哪些任务是必需的,也很容易迷失在不同的包文档中。
而现在有一个全新的自然语言处理工具箱,你只需要打开一个新的笔记本,就能像Pandas一样开始文本数据分析了,先睹为快!

文本英雄:一个pipeline完成所有NLP操作

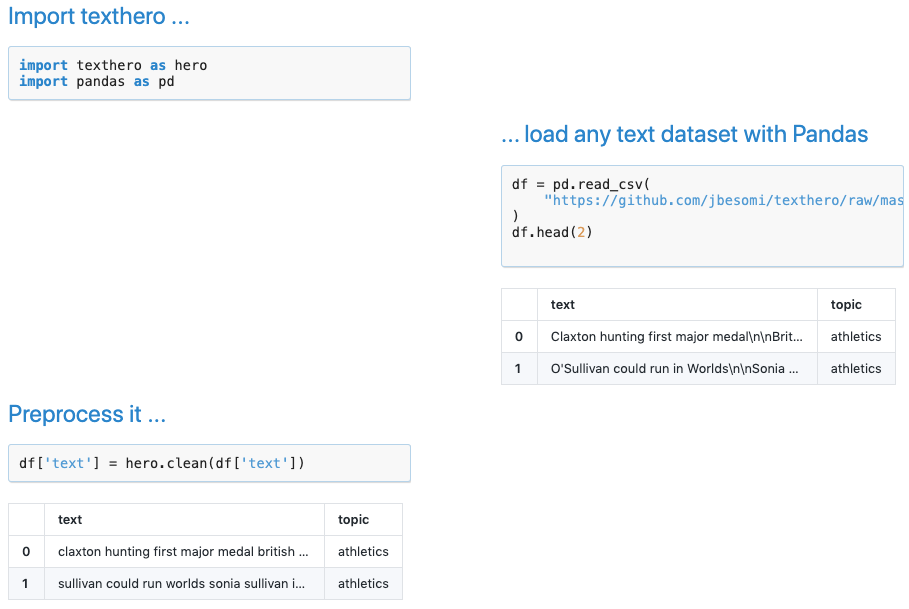

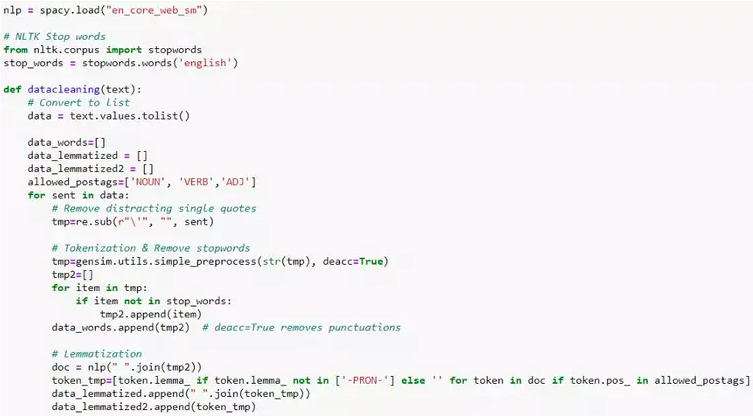
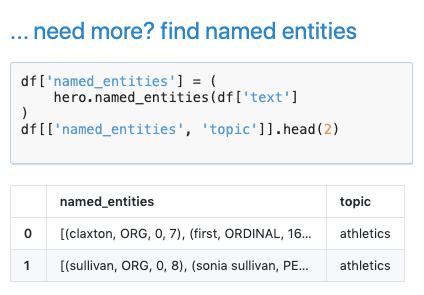
关键短语和关键字提取,命名实体识别等等。
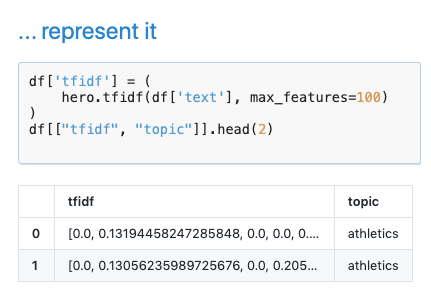

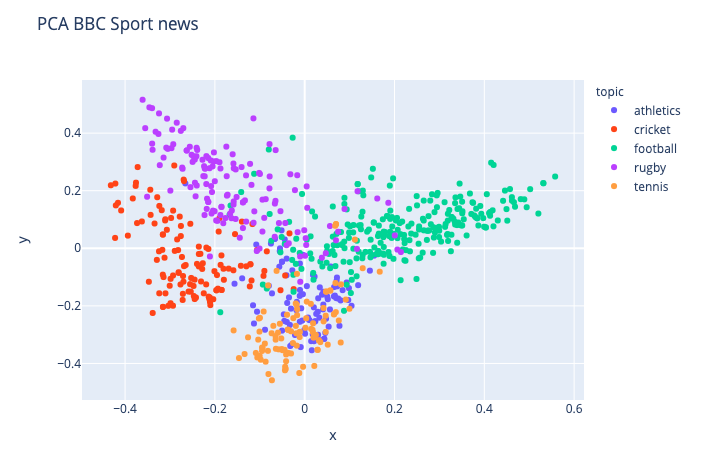
不仅功能强大速度还超快!

网友:恨不生同时,早用早下班!



登录查看更多
相关内容
Arxiv
4+阅读 · 2018年6月11日
Arxiv
5+阅读 · 2018年5月23日

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年6月11日
Arxiv
5+阅读 · 2018年5月23日