【大咖解读】谢国彤:疾病预测的机器学习、深度学习和经典回归方法

新智元专栏
作者:谢国彤
【新智元导读】AI在医疗中的应用场景十分复杂也十分重要,包括疾病的诊断、预测、治疗和管理等。有感于 “搞人工智能技术的人不知道医疗里重要又可解的问题是什么,搞医疗的人不知道技术究竟能帮到什么程度”,前 IBM 认知医疗研究总监、平安医疗科技研究院副院长谢国彤博士针对疾病预测技术的核心概念、主要方法和发展趋势,带来详细解读。

去年在新智元上写了《我看到的靠谱医疗 AI 应用场景和关键技术》,原本计划要写个 “连续剧” 的,后来诸多事情就耽误了。一晃快一年了,现在推出第二篇,疾病预测技术的概念、方法和趋势,浅析前文中提到的疾病预测技术的核心概念、主要方法和发展趋势。
疾病风险预测核心解决的问题是预测个体在未来一段时间内患某种疾病(或发生某种事件)的风险概率。疾病预测会根据某个人群定义,例如全人群、房颤人群、心梗住院人群等,针对某个预测目标,例如脑卒中、心衰、死亡等,设定特定的时间窗口,包括做出预测的时间点,和将要预测的时间窗,预测目标的发生概率。
利用真实世界数据进行疾病预测面临如下一些技术挑战:
数据质量差:电子病历数据中很多字段有缺失,导致关键特征无法提取;甚至有无意或有意的输入错误,给数据分析造成了噪音。
数据维度高:医疗的数据涉及患者的病情主诉、既往病史、家族遗传史、个人史、体格检查信息、诊断、检验、检查、用药和手术等方面。一个疾病登记库中每位患者的数据往往达到 2000 维,而真实电子病历的数据甚至会达到几万维。如此高维度、稀疏的数据给预测带来了挑战。
数据时序性:患者在一段时间内会有持续的医疗记录,如住院期间的多次记录,或者一年内的多次门诊记录。如果涉及可穿戴式设备收集的实时数据,更是每分每秒都在变化。为了从数据中更好的提炼预测信号,必须对数据的时间序列信息进行分析挖掘。
数据不均衡:很多疾病的发病率都不高,比如房颤患者发生脑卒中的平均概率是 10%,脑卒中患者出院后导致残疾的平均概率是 4%。造成数据中正例相对较少,很不均衡,对机器学习算法的要求更高。
疾病预测的主要方法可以简单的分为经典回归方法、机器学习方法和深度学习方法三大类。下面分别用三篇论文举例介绍一下。
基于经典回归方法的疾病预测
传统的疾病风险预测主要基于 Cox 比例风险回归模型(简称 Cox 模型)及逻辑回归模型。例如,[Wang et al. 2003] 发表于 JAMA 的文章利用 Cox 模型,基于弗雷明汉(Framingham)心脏研究来建立房颤患者发生脑卒中及死亡的风险预测模型,方法流程见图 1。该研究用患者在确诊房颤前最近一次检查的数据作为风险因素的基线数据,观测的起点为房颤确诊,观测时间窗为 10 年。基于之前房颤预测脑卒中的研究,两个非常重要的连续变量,即年龄和收缩压被直接放入了多变量模型。其他的风险因子采用逐步回归法确定,符合检验标准 P<0.10 的变量会被放入模型,包括服用抗压药物、有心肌梗塞或充血性心脏衰竭病史(在确诊房颤前)、有卒中或短暂性脑缺血发作史(在确诊房颤前)、吸烟、心电图判断的左心室肥厚、糖尿病和临床性心脏瓣膜病。

图 1 基于 Cox 回归的脑卒中及死亡风险预测
该研究 [Wang et al. 2003] 的统计分析方法采用了 Cox 比例风险模型(proportional hazards model),是由英国统计学家 D.R. Cox 提出的一种半参数回归模型。该模型以生存结局和生存时间为应变量,可同时分析多个因素对生存期的影响,能分析带有删失生存时间的数据,且不要求估计数据的生存分布类型。Cox 模型在医学研究中得到了广泛的应用,是传统生存分析和风险预测中应用最多的多因素回归分析方法。
脑卒中预测模型的评估考虑了校准度(calibration)及区分度(discrimination)。校准度是指预测结果和实际结果的一致度,用 Hosmer-Lemeshow(H-L)统计量评价;区分度采用 c 统计,即受试者工作特征曲线(receiver operating characteristic curve,又称 ROC 曲线)下的面积(AUC)。脑卒中预测模型和脑卒中或死亡预测模型的 H-L 统计量分别为 7.6 和 6.5,脑卒中预测模型的 AUC 为 0.66,而脑卒中或死亡预测模型的 AUC 为 0.70。
基于机器学习方法的疾病预测
尽管传统的回归方法在疾病预测方面有广泛的应用,但这些方法在预测准确度和模型可解释方面,都仍有提升的空间。近年来,机器学习领域的特征选择和有监督学习建模方法越来越多地用于疾病预测问题。一些机器学习方法可以提高预测模型的可解释性,例如决策树方法。另一方面,一些较新的机器学习方法可以带来更好的预测性能。
2010 年发表于 KDD 的文章 [Khosla et al. 2010] 采用了特征选择和机器学习方法来预测 5 年内的脑卒中发生率。该研究的数据来自心血管健康研究(CHS) 数据集,主要针对 65 岁以上人群。该数据记录了 1989-1999 年 5021 位患者将近 1000 个的属性数据,包括医疗检查,问卷,电话联系等。预处理后最终的数据集包括 4988 个样本,其中 299 个个体发生了脑卒中,共包含 796 个特征。数据被随机分成 9:1 的训练集和测试集,同时保证正负样本比例不变,方法流程见图 2。
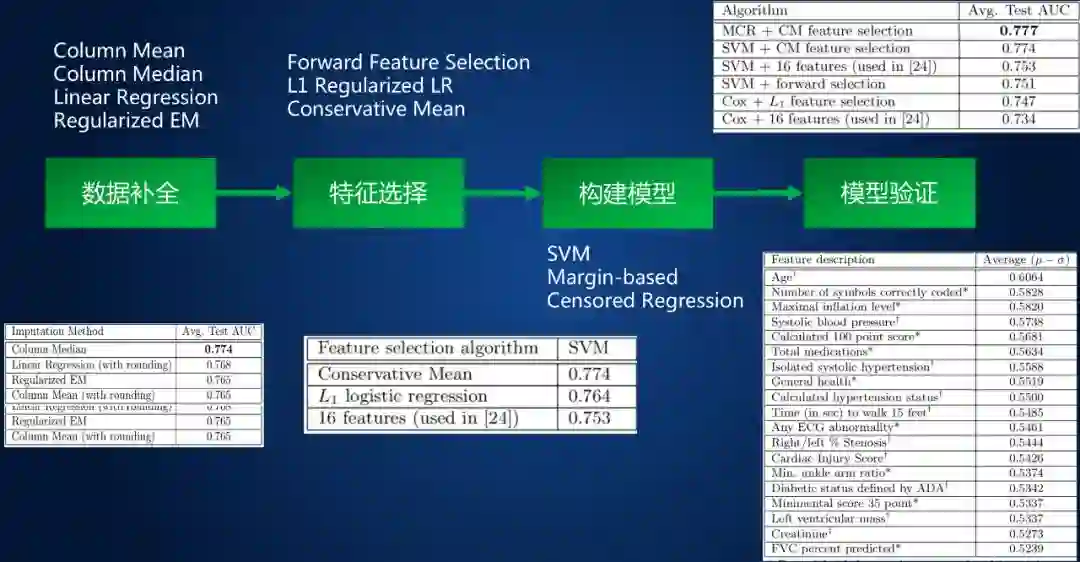
图 2 基于机器学习的脑卒中风险预测
该研究采用了四种方法进行缺失值填充,包括均值填充、中位数填充、线性回归及期望最大化方法;特征选择方法有 3 种,包括前向特征选择、L1 正则化和保守均值特征选择 (µ - σ);建模时尝试了支持向量机(SVM)和基于边缘的删失回归方法。使用 L1 正则化逻辑回归进行特征选择,然后使用 SVM 进行预测,采用 10 倍交叉验证的平均测试 AUC 为 0.764,优于 L1 正则化 Cox 模型。将各种特征选择算法与预测算法相结合的平均显示,保守均值和基于边缘的删失回归相结合在 AUC 评价标准中能达到 0.777,为性能最佳的结果。
基于深度学习方法的疾病预测
近年来,深度学习技术飞速发展,对图像识别、语音识别、自然语言理解等多个领域产生了颠覆性的改变。对于电子病历数据分析方面,也已有一些研究利用深度学习方法来建立疾病风险预测模型,采用了 CNN 或 RNN 的模型。
[Cheng et al. 2016] 基于 30 余万患者为期 4 年的电子健康档案 (EHR) 数据,采用 CNN 网络来预测未来的疾病发生事件。研究的关键问题是如何从电子健康档案的既往时序数据出发,建立有效模型,预测患者疾病发生的风险概率。该研究的数据集来源于 319,650 例患者为期 4 年的真实电子健康档案,抽取慢性心衰(CHF,充血性心力衰竭)和慢阻肺(COPD,慢性阻塞性肺病)相关数据,其中 CHF 测试数据集包括 1127 正例患者,3850 负例对照;COPD 测试数据集包括 477 正例患者,2385 负例对照。该研究采用卷积神经网络 (CNN) 作为有监督学习模型,首先将每个患者的电子健康档案数据简化映射为二维 EHR 矩阵,纵轴为患者临床事件的类型,对应到 ICD-9 的编码,横轴为患者临床事件的发生时间,以天为计算单位。考虑 EHR 矩阵相关的特点,该研究基于以下假设建立卷积神经网络模型:1)假设临床事件之间不存在相关性;2)同一临床事件在时间上存在相关性;3)不同患者入院的时间长度不同,体现为 EHR 矩阵的大小不一致。文章最终采用了 INPUT-CONV-POOL-FC 共四层的卷积神经网络模型,方法流程如下图 3 所示。

图 3 卷积神经网络模型
因为患者的电子健康档案矩阵是变长的,所以沿时间轴被分割为不同时段子矩阵,然后先针对每个子矩阵提取特征,再将不同子矩阵的特征集成。按照分割、提取、集成步骤的不同,该研究采用了几种不同的集成方法,然后比较不同的方法在慢性心衰和慢阻肺两组测试数据集上的预测性能。最终发现综合分割、提取、集成的混合策略 SF-CNN 效果最好。
目前更多的人尝试用RNN(Recurrent Neural Network)的方法来分析电子病历中的临床事件之前的时序关系(Temporal Relation)。[Chio et.al 2016] 在心衰(HF,Heart Failure)的预测上率先使用了基于RNN的方法,基于3884个正例和28,903个负例数据,时间跨度从2000年5月,到2013年5月共3年的时间。针对单个临床事件的建模采用了自然语言理解中常用的one-hot向量的方式,把任何一个临床事件都表示成N维的向量,但向量的最后一位是事件发生时间距离预测时间的间隔,类似于一个时间戳(timestamp)。然后使用了GRU(Gated Recurrent Unit,门循环单元)从每个输入的临床事件向量计算相应的隐状态,在最终的隐状态上应用逻辑回归模型计算最后的HF风险概率。跟LR(Logistic Regression),SVM和KNN等多种经典回归或机器学习方法试验对比后发现,基于RNN方法的预测AUC有提高。
从以上针对经典回归方法、机器学习方法和深度学习方法的分析可以发现,疾病预测技术必要的组成部分包括数据补全、特征表示、特征选择和预测建模等几个关键步骤,总结见表 1。
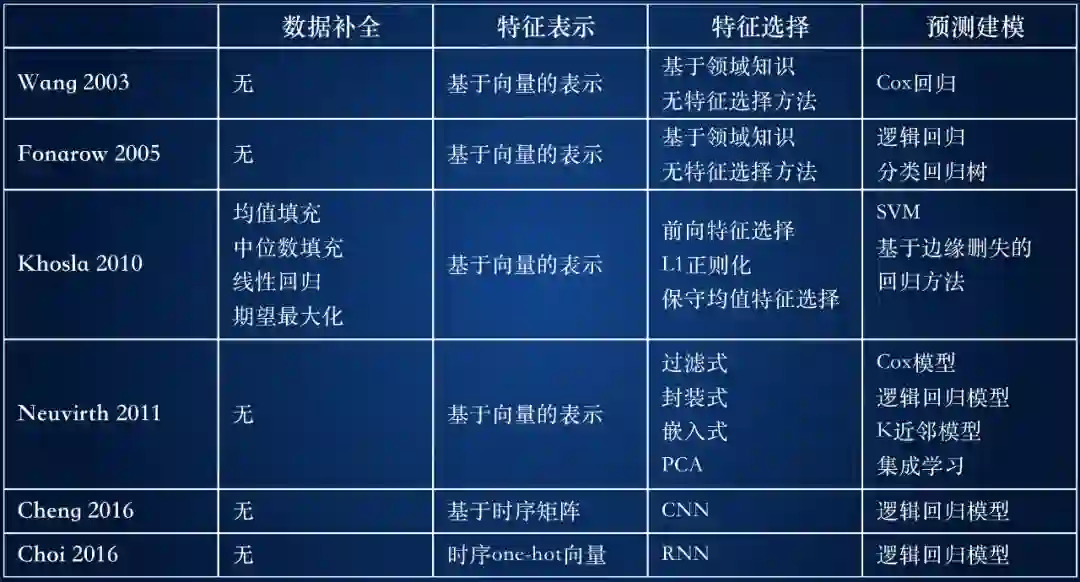
表 1 疾病预测方法分析对比
从中可以看出:
预测建模的方法本身并没有太多的突破:除了 [Khosla et al. 2010] 融合了 SVM 和 Cox 回归的特性发明了基于边缘删失的回归方法,绝大多数的工作创新集中在特征表示和特征选择。
患者特征从基于向量的表示方法向时序矩阵转变:经典的机器学习和统计方法普遍采用基于向量的表示方法,采用多种特征选择算法提取最有预测能力的特征。最新的深度学习的方法采用时序矩阵或时序向量的方法,尽量捕捉真实世界数据中的时序信号。
深度学习方法变革了特征提取方法,但降低了可解释性:在特征选择时通过 CNN 或 RNN 的方法对原始特征进行多层的变换,把原始特征映射到新的空间中,提高分类的能力,但同时降低了模型的可解释性。
疾病预测技术的研究可以关注下面两个重点:
基于多模态数据的预测:医疗数据是多模态的,包含结构化数据、文本、影像和流数据(心率、血氧、呼吸等)。目前的预测方法主要处理结构化的数据,如果需要文本、影像或者流数据中的特征,就先用某些方法把需要的特征从这些非结构化数据中抽取出来。如何借助多个端到端的网络处理多模态的数据并进行融合、预测是很重要的技术挑战。
医学领域知识和机器学习方法的融合预测:在目前的疾病预测方法中,医学领域知识和机器学习方法是割裂的。经典的统计方法完全基于医学领域知识手工的挑选待选特征,然后利用统计的方法计算每个特征的重要性,构建预测模型。机器学习的方法则完全从数据出发,并不参考在某个预测领域中过去几十年积累的已知的风险因素和权重,也不重视模型的可解释性,用特征表示和提取的方法从海量数据中自动的提取特征,构建模型。如何有效的融合医学领域知识和机器学习方法,构建可解释性强的预测模型是未来技术创新的重要方向。
最后,感谢万祎,贾文笑和李非同学对本文的贡献,更要感谢每一位有耐心看完这篇长文的读者。
参考文献
1. [Wang et al. 2003] Wang TJ, Massaro JM, Levy D, et al. A risk score for predicting stroke or death in individuals with new-onset atrial fibrillation in the community: the Framingham Heart Study. JAMA. 2003; 290 (8): 1049-1056.
2. [Fonarow et al. 2005] Fonarow GC, Adams KF Jr, Abraham WT, Yancy CW, Boscardin WJ. Risk stratification for in-hospital mortality in acutely decompensated heart failure: classification and regression tree analysis. JAMA. 2005 Feb 2;293(5):572-80.
3. [Khosla et al. 2010] Khosla A, Cao Y, Lin CC, Chiu HK, Hu J, Lee H. An integrated machine learning approach to stroke prediction. In: Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, 2010 Jul 25 (pp. 183-192).
4. [Neuvirth et al. 2011] Neuvirth H, Ozery-Flato M, Hu J, Laserson J, Kohn MS, Ebadollahi S, Rosen-Zvi M. Toward personalized care management of patients at risk: the diabetes case study. In: Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 2011 Aug 21 (pp. 395-403).
5. [Cheng et al. 2016] Cheng Y, Wang F, Zhang P, Hu JY. Risk prediction with electronic health records: a deep learning approach. SIAM Conference on Data Mining (SDM 2016)
6. [Choi et al. 2016] Choi E, Schuetz A, Stewart WF, Sun JM. Using recurrent neural network models for early detection of heart failure onset. J Am Med Inform Assoc 2016;0:1–9.





