【ACL2020】北大提出低资源场景下的对话生成任务定制模型
宋伊萍1, 刘泽群1, 闭玮2, 严睿3, 张铭1
1北京大学计算机科学技术系
2腾讯AI实验室
3北京大学王选计算机研究所
网址:https://www.zhuanzhi.ai/paper/529f7172baf2b3f41bdc860e25519b5d
代码链接:https://github.com/zequnl/CMAML
视频链接:https://v.youku.com/v_show/id_XNDcyMTM0NDQ2MA==.html?spm=a2hbt.13141534.0.13141534

摘要:用最少的语料训练生成模型是构建开放域对话系统的关键挑战之一。现有的方法倾向于使用元学习框架,首先预训练所有非目标任务的参数,然后在目标任务上进行微调。然而,微调的方法仅仅将不同任务从参数角度区分开来,却忽略了模型的结构,因此容易产生相似的对话模型。本文提出了CMAML算法,可以为每一个对话任务定制一个独特的模型。在CMAML中,每个对话模型由一个共享模块、一个选通模块和一个私有模块组成。前两个模块是所有任务共享的,第三个私有模块具有独特的网络结构与参数,以捕捉相应任务的特征。训练中,不相似的任务网络结构没有重叠,相似的任务共享部分网络结构和参数,因此CMAML可以适用于低资源场景。在两个数据集上的实验表明,CMAML在任务一致性、回复质量和多样性方面都优于所有基线模型,且在低资源文本生成任务上具有较强的通用性。
一、 低资源生成任务与元学习
大数据时代的到来,让很多领域的研究者们不再为数据的不足而担忧。然而依旧有很多精细化的场景对数据质量要求高,数据难以收集,或者需要领域专家对数据进行标注和筛选。例如,分类任务中的图像细分类、罕见疾病的诊断,生成任务中的多语言机器翻译、个性化对话系统。因此,仅使用少量训练样本,即在低资源设定下(few-shot),完成分类或者生成任务是机器学习领域的重要研究课题。
在每个生成任务只有很少的训练样本的条件下训练并得到一批生成任务的模型,称为低资源文本生成。以个性化对话系统为例,由于能够收集到的单个用户的对话语料远不足以支撑训练出该用户的个性化对话模型,因此需要探究如何在低资源场景下利用多个用户的个性化语料完成个性化对话系统的构建。相比于分类任务,生成任务的模型复杂、参数多,因此在训练过程中,生成任务更倾向于把多个任务的数据进行共享以增加数据量,而忽略了保留任务本身独特的特征。
图1.用户的个性化特征
近年来,有人提出了一些将低资源生成任务看作元学习问题的研究。元学习有三种不同的方法:基于度量的方法、基于模型的方法和基于优化的方法。前两个是为分类问题而设计的,第三个是模型无关的。因此,可以考虑将最流行的基于优化的MAML(Model Agnostic Meta Learning)方法应用于对话生成任务。
MAML的目标是在应用于新任务时,通过最大化损失函数的灵敏度来寻找模型参数的初始值。对于一个目标任务,它的对话模型是通过对MAML的初始参数进行微调,并结合其特定任务的训练样本得到的。生成对话模型的目标是构建一个函数,将用户查询映射到回复,其中函数由模型结构和参数决定。MAML只从参数优化的角度搜索最优参数设置,而忽略了从结构优化的角度搜索最优网络结构。
为了调整MAML获得更大的模型多样性,本文设定了三个目标:首先,为不同的生成任务定制模型;其次,每个任务的独特模型结构能够记忆任务特征;第三,与MAML相比,不需要额外的训练数据。因此,本文提出了CMAML(Customized Model Agnostic Meta-Learning Algorithm)算法。
二、 CMAML模型介绍
下面,本文首先描述CMAML产出的对话模型的网络结构,然后介绍其训练方法。
对于每个任务,相应的生成模型由三部分组成:共享模块(shared module)、私有模块(private module)和门控模块(gating module)。共享模块是一个传统的序列到序列模型(seq2seq),旨在学习一般的生成能力。此模块在任务之间共享。私有模块旨在记住任务独特的特性。所有任务的私有模块都是从seq2seq解码器中的同一个多层感知机(Multi Layer Perception, MLP)开始,然后在训练过程中演变成不同的结构。门控模块用于平衡前两个模块的贡献,并且也在任务之间共享。
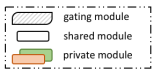

图2.对话模型seq2SPG
训练过程分为两个阶段:预训练和定制化模型培训。
第一个阶段是预训练阶段。在预训练中,CMAML使用原始MAML算法获得一个预训练的对话模型作为所有任务的初始模型。此时,不同任务的模型具有相同的网络结构和参数。
第二个训练阶段是定制化模型训练。在定制化模型训练中,本文首先从MAML初始化开始,用自己的训练数据对每个任务的整个对话模型进行微调,并对私有模块的参数进行L-1正则化。这里L-1正则化的目的是使参数稀疏,使得只有有利于生成任务特定语句的参数才是活动的。
然后,本文应用自上而下的策略来修剪每个任务的私有模块的MLP网络。本文不修剪与MLP的输入和输出连接的层。对于其他层,本文首先从最接近输出的层开始修剪。当本文处理第l层时,它的上层应该已经修剪过了。本文只保留当前处理层的边,其重量超过某一特定值阈值。如果l层中连接到某个节点的所有边都被修剪,那么l-1层中连接到该节点的所有边也将被修剪。
这里,私有模块是用来捕获每个任务的唯一性的,它应该仅仅使用单一任务的数据数据进行训练。然而,在低资源场景下,本文并没有足够的训练数据来训练这部分。幸运的是,所有私有模块都是从相同的MLP结构演变而来的,相似的任务自然会有重叠的网络结构,即修剪后的剩余边缘重叠,而不相似的任务没有重叠。如图所示:
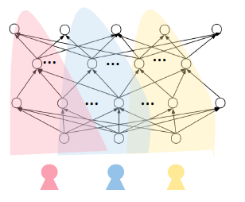
图3.根据用户个性化特点定制出不同的网络结构
最后,在对私有网络进行剪枝后,本文实施联合元训练算法。对于共享模块和选通模块,所有任务共享相同的参数,并使用所有训练数据对它们进行训练。对于私有模块,每个任务有其独特的网络结构,并使用单个任务的数据对该网络进行训练。联合训练依旧采用MAML的训练框架。
整体来看,模型的共性由共享模块代表;模型的个性由每个任务独有的私有模块刻画,且私有模块上的每个参数都从自身角度对任务进行了聚类;每个任务对共享模块和私有模块的权衡由门控模块决定。由此,CMAML算法在低资源场景下对不同任务定制出了独特的文本生成模型。框架图如下:
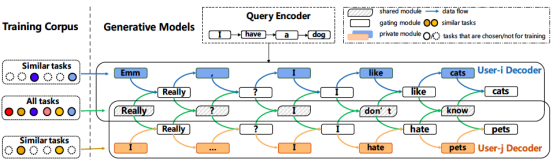
图4. CMAML算法在个性化对话场景下的框架图
三、 实验分析
为了验证CMAML的有效性,本文在两个数据集上进行了实验:Persona-chat和Mojitalk。在Persona-chat中,本文把为用户建立对话模型看作是一项任务。在Mojitalk中,本文将使用指定的表情(emoji)生成对话回复视为一项任务。
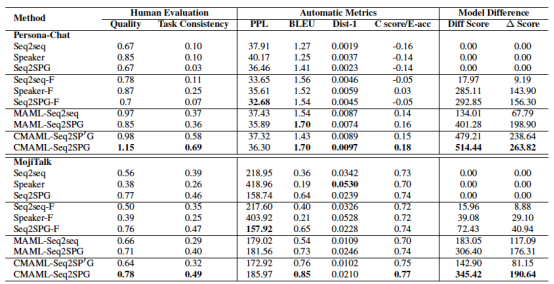
图5.两个数据集上的实验结果
结果表明,预训练-调优的方法优于仅使用预训练的方法。MAML算法在质量分数上的表现并不比预训练-调优的方法好,但多样性分数相对较高。这表明MAML有助于提高回复多样性。特别的,本文提出的CMAML方法在对话回复质量和多样性方面比所有的基线方法好。特别是CMAML的模型差异得分最高,说明CMAML确实可以使不同任务的模型更加多样化。
本文还评估了各种方法在不同的低资源场景下设置。
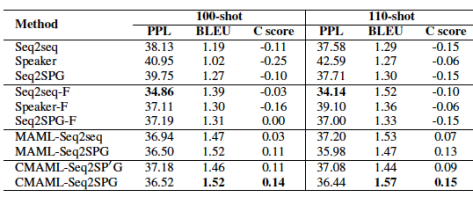
图6.在不同数据量下的实验结果
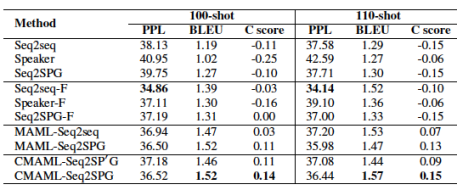
图7.在不同任务相似度下的实验结果
可以,对于非MAML方法,任务一致性并没有随着数据的增长而提高。而对于基于MAML的方法,句子质量和任务一致性都随着数据的增长而增加。实验结果还表明,当任务不太相似时,基于MAML的方法表现更好。
四、 总结与展望
在以往的工作中,研究者们仅仅从模型参数的角度去区分不同的任务,这就造成了在生成模型对数据不敏感的情况下,各个任务对应的生成模型差异小,无法体现任务的个性化特征。
本文提出的CMAML算法可以为每个任务定制一个具有独特的网络结构和参数的模型,且每个生成任务只需要一到两百个训练样本。独特的模型结构可以记住每个任务的独有特征,且相似的任务可以从模型结构的角度共享训练数据。这里,每个任务独特的模型结构可以看作是记录模型特性的记忆模块,相似的任务有可重叠的记忆单元。此外,CMAML具有良好的通用性,其定义的生成模型和训练算法对任务没有特殊要求,能够适应各种低资源下的生成场景。
低资源场景(few-shot)下的文本生成模型的构建对单个任务的数据量依旧有一定要求,一个更加极端的条件是零资源场景(zero-shot)。零资源场景下的机器学习任务更加困难,却也十分有意义,例如模型冷启动问题等。未来,作者将继续关注低资源和零资源相关课题的研究。




