一文读完GitHub30+篇顶级机器学习论文(附摘要和论文下载地址)
新智元AI World 2017世界人工智能大会开场视频
中国人工智能资讯智库社交主平台新智元主办的 AI WORLD 2017 世界人工智能大会11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:http://www.iqiyi.com/v_19rrdp002w.html
下午:http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元编译
作者:常佩琦 弗格森
【新智元导读】 今天介绍Github上的开源项目,专门用于更新最新的研究突破,具体说来,就是什么算法在哪一个数据集上取得了state-of-the-art 的成果,包括语音、计算机视觉和NLP、迁移学习、强化学习。在这里,你可以读懂2017机器学习领域究竟在哪些方向上取得了突破,各大前沿机构和学术大牛们在哪些方向上发力。比如,Hinton掀起深度学习革命的Capsule 网络、再到谷歌的“一个模型学习所有”“Attention is all you need”以及Facebook在机器翻译上的屡次突破,以及让大家兴奋的AlphaGo Zero等等。
学术领域,最新的机器学习技术都做到了什么水平?Github上有一个开源项目,专门用于更新最新的研究突破,具体说来,就是什么算法在哪一个数据集上取得了state-of-the-art 的成果。大类包括:监督学习、半监督学习和无监督学习、迁移学习、强化学习,小类包括语音、计算机视觉和NLP。
这一份列表几乎囊括了2017年机器学习领域所有最重大的突破,从微软对话语音识别错误率将至5.1%、到Hinton掀起深度学习革命的Capsule 网络、再到谷歌的“一个模型学习所有”“Attention is all you need”以及Facebook在机器翻译上的屡次突破,以及让大家兴奋的AlphaGo Zero。
这不仅仅是一份论文和代码资源的列表,更是2017年机器学习和人工智能里程碑的表单,在这里,你可以读懂2017机器学习领域究竟在哪些方向上取得了突破,各大前沿机构和学术大牛们在哪些方向上发力。
作者说:“本库为所有机器学习问题提供了当前最优结果,并尽最大努力使库保持随时更新状态”,我们也同样期待这一列表不断更新,出现更多让人拍案叫绝的最新研究成果,将人工智能不断往前推进。
最新更新时间:2017年11月17日
本库的分类如下:
监督学习
1. Speech
2. 计算机视觉
3. NLP
半监督学习:计算机视觉
无监督学习
1. Speech
2. 计算机视觉
3. NLP
迁移学习
强化学习
NLP
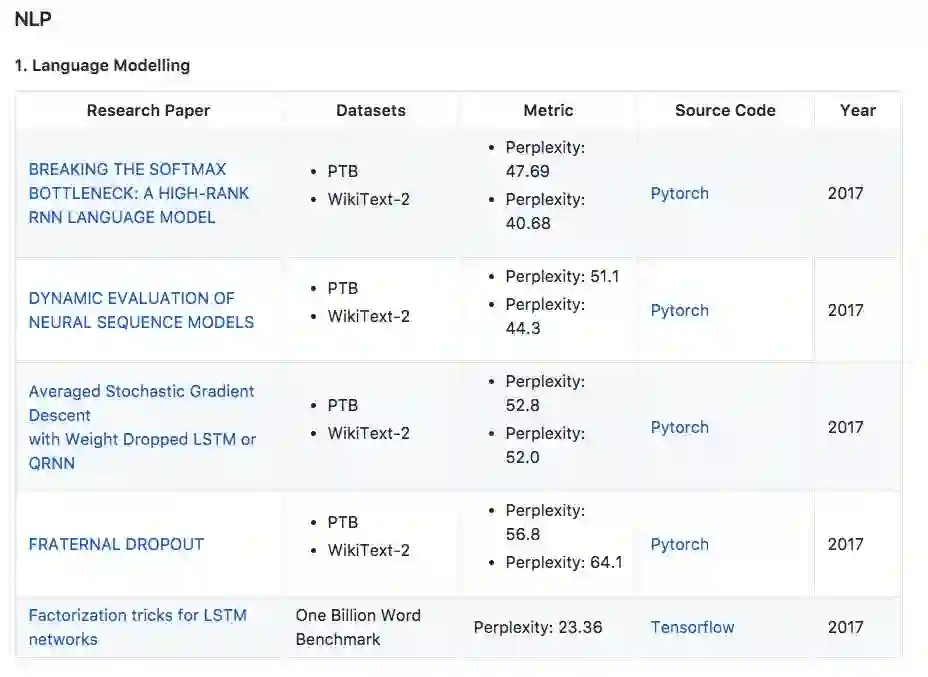
1. 语言建模
论文:BREAKING THE SOFTMAX BOTTLENECK: A HIGH-RANK RNN LANGUAGE MODEL
地址:https://arxiv.org/pdf/1711.03953.pdf
本文将语言建模作为一个矩阵分解问题,并表明基于Softmax的模型(包括大多数神经语言模型)的表达受到Softmax瓶颈的限制。 鉴于自然语言高度依赖于上下文,这意味着在实践中Softmax与分布式词嵌入没有足够的能力来建模自然语言。 本文提出了一个简单有效的解决方法,并且将Penn Treebank和WikiText-2中的perplexities分别提高到47.69和40.68。
论文:DYNAMIC EVALUATION OF NEURAL SEQUENCE MODELS
地址:https://arxiv.org/pdf/1709.07432.pdf
本文提出使用动态评估来改进神经序列模型的性能。 模型通过基于梯度下降的机制适应最近的历史,将以更高概率分配给重新出现的连续模式。动态评估将Penn Treebank和WikiText-2数据集上的perplexities分别提高到51.1和44.3。
论文:Averaged Stochastic Gradient Descent with Weight Dropped LSTM or QRNN
地址:https://arxiv.org/pdf/1708.02182.pdf
提出了使用DropConnect作为经常正则化形式的权重下降的LSTM。此外,本文引入NT-ASGD,平均随机梯度方法的变体,其中平均触发是使用非单调条件确定的,而不是由用户调整。使用这些和其他正则化策略,本文在两个数据集上实现了state-of-the-art word level perplexities:Penn Treebank上的57.3和WikiText-2上的65.8。在结合我们提出的模型探索神经缓存的有效性时,在Penn Treebank上实现了更低的52.8的state-of-the-art word level perplexities,而在WikiText-2上达到了52.0。
论文:FRATERNAL DROPOUT
地址:https://arxiv.org/pdf/1711.00066.pdf
提出一个叫做fraternal dropout的技术。首先用不同的dropout mask训练两个同样的RNN,并最小化预测差异。本文评估了提出的模型,并在Penn Treebank和Wikitext-2上达到了当前最优结果。
论文:Factorization tricks for LSTM networks
地址:https://arxiv.org/pdf/1703.10722.pdf
提出了两个带映射的LSTM修正单元,来减少参数数量和加快训练速度。
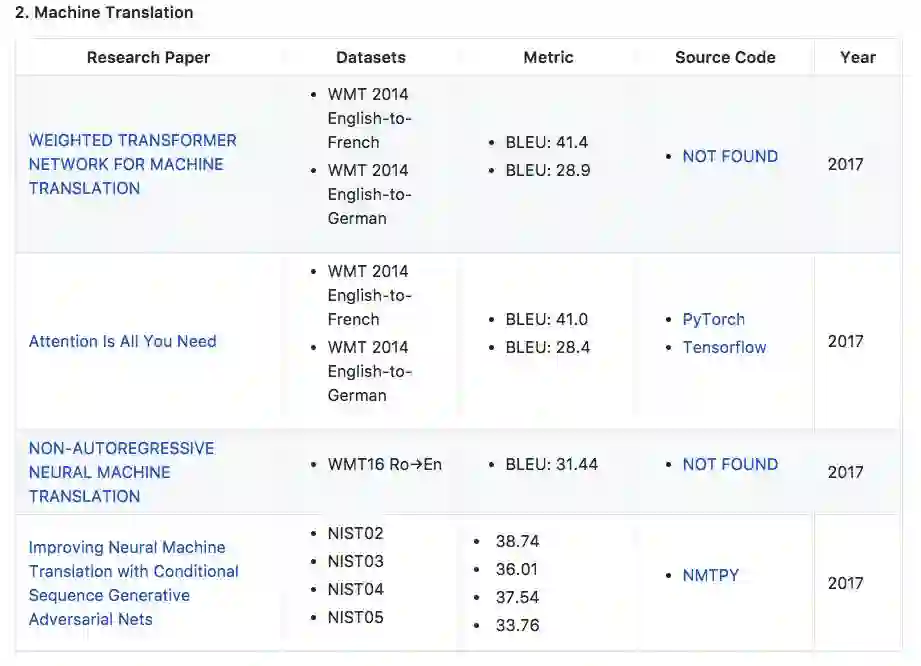
2. 机器翻译
论文:WEIGHTED TRANSFORMER NETWORK FOR MACHINE TRANSLATION
地址:https://arxiv.org/pdf/1711.02132.pdf
在WMT 2014英德翻译任务和英法翻译任务中,模型的性能分别提高了0.5 BLEU points和0.4。
论文:Attention Is All You Need
地址:https://arxiv.org/abs/1706.03762
在WMT 2014英德翻译任务和英法翻译任务中,模型的性能分别提高到28.4 BLEU points和41.0 BLEU points。
论文:NON-AUTOREGRESSIVE NEURAL MACHINE TRANSLATION
地址:https://einstein.ai/static/images/pages/research/non-autoregressive-neural-mt.pdf
论文:Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets
地址:https://arxiv.org/abs/1703.04887
3. 文本分类
论文:Learning Structured Text Representations
地址:https://arxiv.org/abs/1705.09207
提出了学习结构化的文本表征,关注在没有语篇分析和额外标注资源下学习结构化的文本表征。在Yelp数据集的准确率达到68.6。
论文:Attentive Convolution
地址:https://arxiv.org/pdf/1710.00519.pdf
本文提出了AttentiveConvNet,通过卷积操作,拓展文本处理的范围。从本地上下文和非本地上下文提取出的信息来得到单词更高级别的特征。在Yelp数据集的准确率达到67.36。
4. 自然语言推理
论文:NATURAL LANGUAGE INFERENCE OVER INTERACTION SPACE
地址:https://arxiv.org/pdf/1709.04348.pdf
介绍了交互式推理网络(IIN),这是一种新型的神经网络架构,能够实现对句子的高层次的理解。我们证明了一个交互张量包含了语义信息以解决自然语言推理。准确率达88.9。
5. 问题回答
论文:Interactive AoA Reader+ (ensemble)
地址:https://rajpurkar.github.io/SQuAD-explorer/
斯坦福问答数据集(SQuAD)是一个新兴阅读理解数据集,其问答基于维基百科,由众包方式完成。
6. 命名实体识别
论文:Named Entity Recognition in Twitter using Images and Text
地址:https://arxiv.org/pdf/1710.11027.pdf
论文提出了一种新型的多层级架构,该架构并不依赖于具体语言学的资源和解码规则。模型在Ritter数据集上F-measure的表现为0.59。
7. 依存关系句法分析
论文:Globally Normalized Transition-Based Neural Networks
地址:https://arxiv.org/pdf/1603.06042.pdf
本文提出了以全球标准化的基于转换的神经网络模型,实现了语音标记、依存关系句法分析和句子压缩的当前最优结果。UAS准确度为94.08%,LAS准确度为92.15%。
计算机视觉
分类
论文:Dynamic Routing Between Capsules
地址:https://arxiv.org/pdf/1710.09829.pdf
Capsule 是一组神经元,其输入输出向量表示特定实体类型的实例化参数我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的 capsule 通过变换矩阵对更高级别的 capsule 的实例化参数进行预测。
论文:High-Performance Neural Networks for Visual Object Classification
地址:https://arxiv.org/pdf/1102.0183.pdf
摘要:论文中提出了一种卷积神经网络变体的快速全可参数化的 GPU 实现。在 NORB 数据集上效果不错,测试误差在2.53 ± 0.40。
论文:ShakeDrop regularization
地址:https://openreview.net/pdf?id=S1NHaMW0b
论文:Aggregated Residual Transformations for Deep Neural Networks
地址:https://arxiv.org/pdf/1611.05431.pdf
论文:Random Erasing Data Augmentation
地址:https://arxiv.org/abs/1708.04896
论文:Learning Transferable Architectures for Scalable Image Recognition
地址:https://arxiv.org/pdf/1707.07012.pdf
论文:Squeeze-and-Excitation Networks
地址:https://arxiv.org/pdf/1709.01507.pdf
论文:Aggregated Residual Transformations for Deep Neural Networks
地址:https://arxiv.org/pdf/1611.05431.pdf
2. 实例分割
论文:Mask R-CNN
地址:https://arxiv.org/pdf/1703.06870.pdf
论文提出一个概念上简单灵活通用的物体分割框架。这种叫做Mask R-CNN的方法,拓展了Faster RNN。在COCO数据集上的平均精准度达到37.1%。
3. 视觉问题回答
论文:Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
地址:https://arxiv.org/abs/1708.02711
提出了视觉问答的最新模型,在2017VOA挑战中获得冠军。整体分数达到69。
语音
ASR (语音识别)
论文:微软2017年发布的对话语音识别系统
数据集: Switchboard Hub5'00
错误率:5.1%
论文地址:https://arxiv.org/pdf/1708.06073.pdf
微软在官方的介绍是:改进语音模型引入了 CNN-BLSTM(convolutional neural network combined with bidirectional long-short-term memory)。另外,在 frame/senone 和词语层面都使用了结合多个声学模型的预测的方法。 通过使用整个对话过程来加强识别器的语言模型,以预测接下来可能发生的事情,使得模型有效地适应了对话的话题和语境。
论文:使用虚拟对抗训练实现分布式顺滑 (2016年)
数据集:SVHN NORB
错误率:24.63(SVHN )9.88 (NORB)
论文地址:https://arxiv.org/pdf/1507.00677.pdf
作者提出了一个局部分布顺滑的概念,作为一个正则化的项目,来提升模型分布的顺滑。
论文: 虚拟对抗训练: 一个面向监督和半监督的正则化方法 (2017年)
数据集:MNIST
错误率:1.27
论文地址:https://arxiv.org/pdf/1704.03976.pdf
论文: 用GAN生成非标签样本 (2017年)
数据集&准确率:
Market-1501 (Rank-1: 83.97 mAP: 66.07)
CUHK-03 (Rank-1: 84.6 mAP: 87.4)
DukeMTMC-reID( Rank-1: 67.68 mAP: 47.13)
CUB-200-2011(Test Accuracy: 84.4)
论文地址: https://arxiv.org/pdf/1701.07717.pdf
计算机视觉 :生成模型
论文:PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION (2017年)
数据集: Unsupervised CIFAR 10
得分:8.80
论文地址:https://arxiv.org/pdf/1704.03976.pdf
Progressive Growing of GANs for Improved Quality, Stability, and Variation”。其中“Progressive Growing”指的是先训练4x4的网络,然后训练8x8,不断增大,最终达到1024x1024。作者使用的数据集以CelebA为基础,还进行了额外的处理,包括超分辨率、模糊背景、对齐。
机器翻译
论文: 无监督机器翻译:是使用单语语料(2017年)
数据集:WMT16 (en-fr fr-en de-en en-de) ;Multi30k-Task1(en-fr fr-en de-en en-de)
得分: BLEU:(32.76 32.07 26.26 22.74);BLEU:(15.05 14.31 13.33 9.64)
论文地址 :https://arxiv.org/pdf/1711.00043.pdf
作者提出了一种新的神经机器翻译方法,其中翻译模型仅使用单语言数据集学习,句子或文档之间没有任何对齐。这个方法的原理是从一个简单的无监督逐字翻译模型开始,并基于重构损失迭代地改进这个模型,并且使用鉴别器来对齐源语言和目标语言的潜在分布。
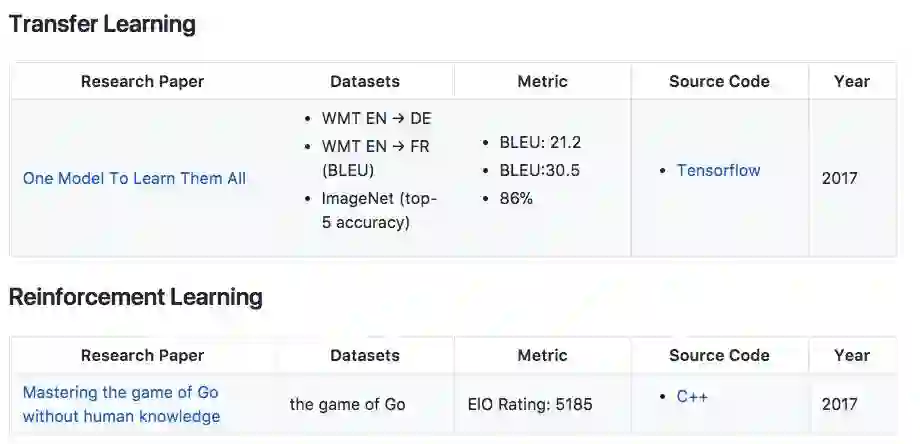
论文:一个模型学习一切(2017年)
数据集:WMT EN → DE ;WMT EN → FR (BLEU);ImageNet (top-5 accuracy)
得分&准确率:BLEU: 21.2;BLEU:30.5;86%
论文地址 : https://arxiv.org/pdf/1706.05137.pdf
作者提出了一个多模型适用的架构 MultiModel,用单一的一个深度学习模型,学会各个不同领域的多种不同任务。
论文:无需人类知识掌握围棋
数据集:the game of Go
ElO Rating: 5185
代码:https://github.com/gcp/leela-zero
论文地址 :http://www.gwern.net/docs/rl/2017-silver.pdf
迄今最强最新的版本AlphaGo Zero,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo
作者的说明:本库为所有机器学习问题提供了当前最优结果,并尽最大努力使库保持随时更新状态。 如果用户发现某个问题的当前最优结果结果已过时或缺失,请提出此问题,并附带以下信息:研究论文名称、数据集、度量标准,源代码和年份)。 我们会立即解决。
我们试图让所有类型的机器学习问题有最新结果。 我无法单独做这件事,因此需要大家的帮助。 如果读者发现数据集的当前最优结果,请提交Google表单或提出问题。 请在Twitter,Facebook和其他社交媒体上分享。
原文链接:https://github.com/RedditSota/state-of-the-art-result-for-machine-learning-problems
(欢迎读者朋友加入新智元读者群一起交流探讨,请加微信:aiera2015)




