【ICML2020】文本摘要生成模型PEGASUS

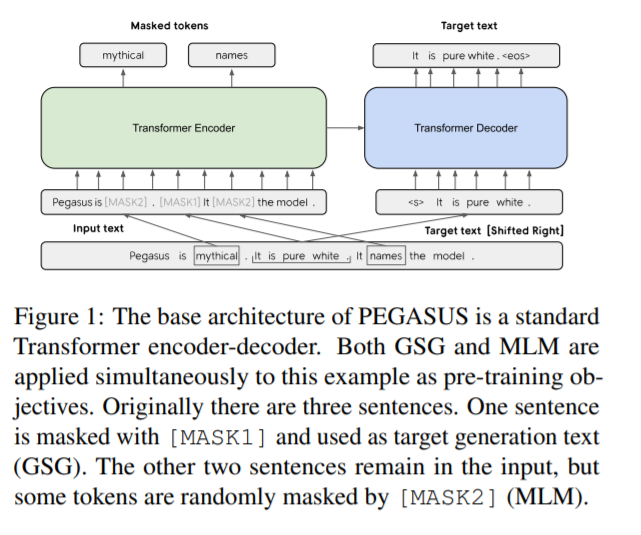
近些年 Transformers 在海量语料上进行自监督预训练再到下游各种NLP任务(当然也包括文本摘要)上微调的方案已取得巨大成功。但是,尚未有针抽象文本摘要(abstractive text summarization)定制预训练目标。此外,目前抽象文本摘要任务也缺乏跨领域的系统评价。为此,本文提出了一种新的自监督预训练目标:GSG(Gap Sentences Generation),以适配Transformer-based的encoder-decoder模型在海量文本语料上预训练。在 PEGASUS 中, 将输入文档中的“重要句子”删除或者遮蔽,再利用剩余的句子在输出中生成这些被删除或遮蔽的句子。从输入和输出看,该目标与文本摘要类似。本文以12个文本摘要数据集(包括新闻、科学、故事、使用说明、电子邮件、专利和立法议案)对最好的PEGASUS模型进行全面测试。实验结果是:PEGASUS刷新12个数据集的ROUGE得分记录。另外,PEGASUS模型在处理低资源摘要数据集也显示出惊人的性能,在6个数据集上仅以1000个样本就超过了之前的最先进结果。最后,本文还对PEGASUS模型生成的摘要结果进行人工评测,结果表明本文的模型在多个数据集上达到与人工摘要相媲美的性能。
https://www.zhuanzhi.ai/paper/8f361c083ad031d1b9f06afc2f10928c
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PEGA” 可以获取《【ICML2020】文本摘要生成模型PEGASUS》专知下载链接索引



登录查看更多
相关内容
Arxiv
1+阅读 · 2020年10月15日
Arxiv
6+阅读 · 2020年8月13日
Arxiv
17+阅读 · 2020年6月2日

相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2020年10月15日
Arxiv
6+阅读 · 2020年8月13日
Arxiv
17+阅读 · 2020年6月2日