AI综述专栏| 大数据近似最近邻搜索哈希方法综述(下)(附PDF下载)
AI综述专栏
在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。
导读
最近邻搜索(Nearest Neighbor Search)也称作最近点搜索,是指在一个尺度空间中搜索与查询点最近点的优化问题。最近邻搜索在很多领域中都有广泛应用,如:计算机视觉、信息检索、数据挖掘、机器学习,大规模学习等。其中在计算机视觉领域中应用最广,如:计算机图形学、图像检索、复本检索、物体识别、场景识别、场景分类、姿势评估,特征匹配等。由于哈希方法可以在保证正确率的前提下减少检索时间,如今哈希编码被广泛应用在各个领域。本文是关于大数据近似最近邻搜索问题中应用哈希方法的综述。文章分为两部分,本篇为第二部分。
「关注本公众号,回复"曹媛",获取完整版PPT」
该文是曹媛博士论文的一部分,谢绝拷贝,违者必究
2.2 数据自身特性
2.2.1 相似度度量
2.2.1.1 欧氏距离
通常情况下,原始空间中的两个x 点 和 y 之间的相似度是由欧氏距离度量的:
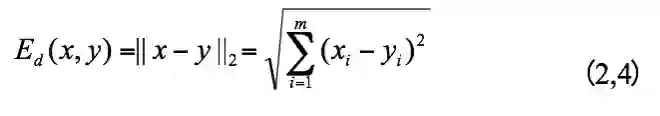
大多数哈希方法都基于此,如上面提到的LSH和SH。
2.2.1.2 核距离
上面提到的哈希方法有一定的局限性,即假设原始空间中的点是由向量形式表示的。然而在很多实际应用中,如多媒体、生物、网络等,数据点往往具有复杂的表现形式,如图、树、序列,集合等。对于这些常见的数据类型,大量复杂的核被用来定义数据点之间的相似度。而且在图像检索等视觉应用中,即使图像是由向量形式表示的,核距离与欧氏距离相比可以更好地展现出图像之间的语义相似度。除此之外,对于很多机器学习应用,无法知道原始空间的明确数据,只可以计算点对的核函数相似度。因此在这些情况下,很多处理核函数相似度的哈希方法被提出,它们既可以适用于向量输入也可以适用于非向量输入。
核函数包括线性核函数,多项式核函数,高斯核函数等。其中,高斯核函数是最常见的,也叫做径向基函数,它是一种沿着径向对称的标量函数,定义如下:
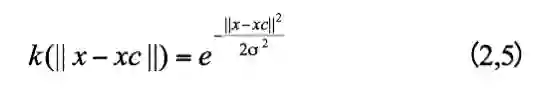
其中,xc 是核函数的中心,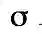
2.2.1.3 语义距离
非监督哈希方法不需要利用带标签训练数据点的标签信息,其目标函数的构造依赖于预先设定的相似度矩阵。然而在图像检索等应用中,图像之间相似度并不是由一个简单的度量标准定义的,因为它并不能保证图像之间的语义相似度。语义相似度往往由带标签的图像对给出,也就是说,原始空间中相似的图像对至少拥有一个共同的标签。对于这样的成对标签数据,监督哈希方法可以生成保持语义相似度的哈希码。其中,Semi-Supervised Hashing (SSH) 是经典的处理语义相似度的哈希方法,详见[1]。
2.2.2 数据模态
2.2.2.1 单模态
近年来,大多数哈希方法都依赖于同质相似度,即数据库中的数据本体都是同一种类型的,这样的哈希方法称作单模态哈希方法。但是随着因特网和多媒体设备的快速发展,我们可以很容易获得大量数据,如文本,图像,视频等。随着数据规模的扩大,数据本体的密度也不断扩大。在实际应用中,异质本体也是普遍存在的,即一些数据库包含的同一种数据本体有多种视角。因此,多模态哈希方法被提出来解决从多种异构领域中搜索出相似数据本体的问题。
2.2.2.2 多模态
初始的多模态哈希方法一般通过将原始空间中的异质数据点映射到一个统一的汉明空间中再进行相似度搜索排序。这种方法的关键问题是如何同时构造多种模态之间的潜在联系以及如何保持在每个模态下的相似度关系。一种方法将多模态本体的每个模态翻译成其中的同一种模态,然后进行单模态搜索。然而这种类型方法有两大缺点:1) 在翻译过程中有一定的近似误差而且很依赖于具体应用。2) 翻译过程往往很慢,导致无法适用于很多实际应用。因此,近期又产生了一些新的多模态哈希方法,详见[1]。
2.2.3 数据流动性
2.2.3.1 固定数据库
目前大多数哈希方法处理数据库中的数据是固定的。但在实际应用中,数据往往连续生成。比如,百度的数据中心搜索机器每天都新增大量文本图像之类的网页。对于这种流动性数据,已有的哈希方法必须重新训练新的哈希函数,这种效率根本无法适应数据库中数据数量的增长和多样性的变化。
2.2.3.2 在线数据库
因此,近期出现了一些可以处理流动数据的在线哈希方法。详见[1]。
2.3 哈希平台
2.3.1 单机
之前讨论的哈希方法处理的都是单一中心机器上的数据,然而随着数据库规模的扩大,数据常常是分布式存储的,一种直观的方法是将所有的数据读取到同一个工作站中,然后像在单机上一样训练哈希函数。但是这将导致计算,时间和空间复杂度太高。
2.3.2 分布式
Hashing for Distributed Data (HDD) 是一种分布式哈希方法。HDD 分布式地学习哈希函数。由于在训练过程中没有节点之间训练数据的交换,通信成本很小,使得HDD可以适用于任何大规模分布式应用。
3 哈希排序方法简介
哈希排序指的是在哈希过程的最后一步,对数据库中所有点哈希得到的二进制码的排序问题。汉明距离是最常用的二进制码排序标准,但它无法对那些与查询点具有相同汉明距离的二进制码排序。如图3.1所示,假设数据库中的点都是二维的,红色叉表示查询点并被编码为“11”,绿色圆点表示查询点的真实 -最近邻。很显然,所有编码为“01”和“10”的点都与查询点具有相同的汉明距离。然而,由于查询点的真实 -最近邻中包含了部分编码为“01”的点而并不包含任何编码为“10”的点,因此编码“01”应该排在编码“10”的前面。在这个例子中,汉明距离无法给出一个合理的哈希排序。
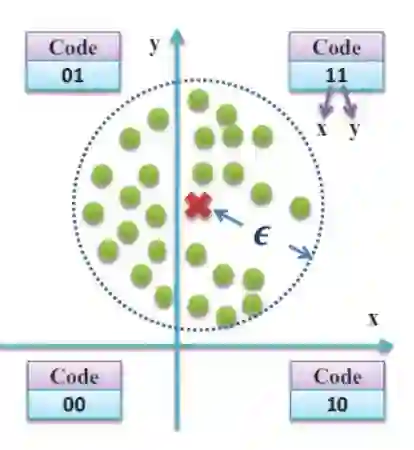
图3.1 汉明距离排序示例
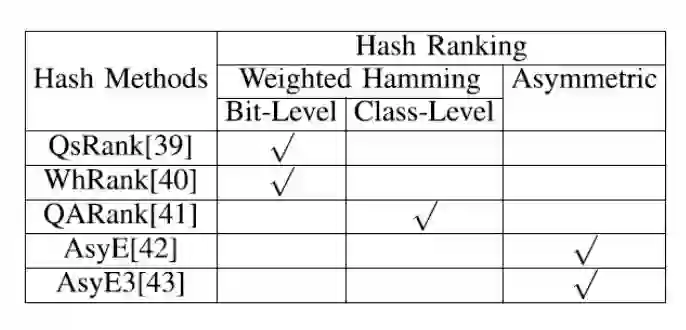
表3.1 哈希排序方法分类
因此从2011年开始不断有人研究哈希排序算法。近年来的哈希排序成果主要基于两类距离:加权汉明距离和非对称距离。几种代表性的哈希排序方法分类详见表3.1,其中标号为[1]中参考文献。
3.1 加权汉明距离
加权汉明距离的权重一般由两部分组成:Offline权重和Online权重。Offline权重不依赖于查询点,根据数据库中点的分布计算得出。该权重一般在投影空间中求解,因为投影空间 P 的信息量远远大于二进制空间 B ;Online权重依赖于查询点,根据查询点与数据库中点的相对分布关系求解。加权汉明距离的权重基本上有两种计算方法:按位算权重和按类别算权重。
3.1.1 按位算权重
按位算权重即对哈希后的每一位计算一个权重 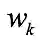
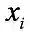
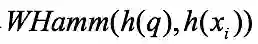
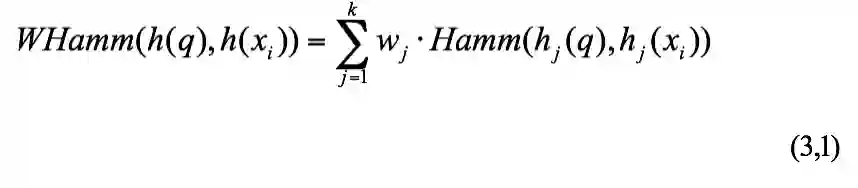
经典的代表算法有QsRank,WhRank等,详见[1]。
3.1.2 按类别算权重
按类别算权重适用于将标签作为相似度表示的数据库,如CIFAR,NUS-WIDE等。我们以Lost in Binarization为例阐述类别权重的计算方法。
Offline权重学习阶段。输入数据库点的二进制码以及类别间的相似度就可以迭代输出 k个类别的权重
。其目标函数旨在最大化类间距离和最小化类内距离。
Online权重学习阶段。首先,计算查询点 q 与数据库中所有点哈希后的二进制码之间的汉明距离,返回与查询点 q 最相近的前 k 个点,并记录它们的标签集合为 T 以及每个标签中含有点的个数( k 近邻中)为
。则查询点q 的最终权重
定义如下:
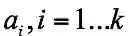
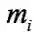
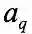
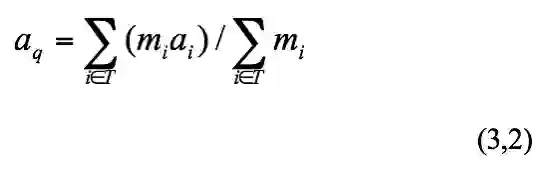
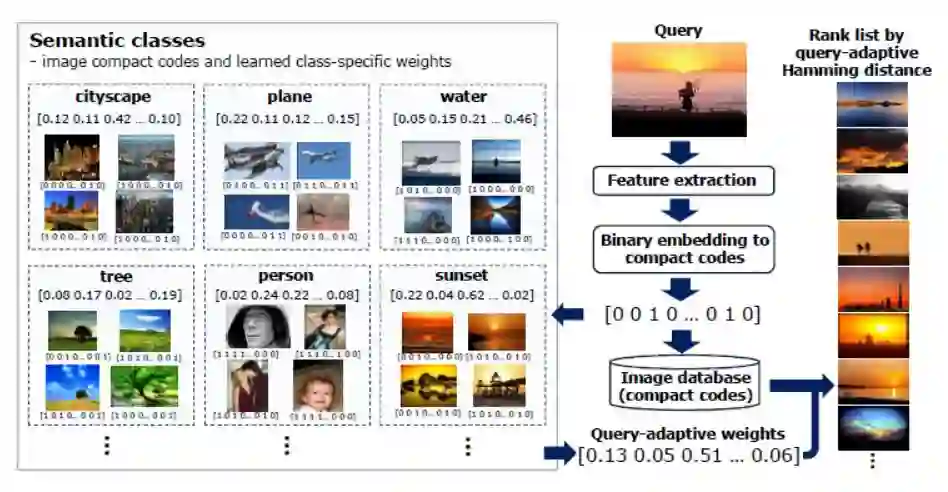
图3.2显示了以图像搜索为例,应用上述权重对汉明距离进行重排序的完整过程。
3.2 非对称距离
哈希编码分为投影和量化为二进制两个过程。非对称的意思是只对数据库中的点二进制化,而对查询点只投影不量化。因此,将非二进制的查询点与二进制的数据库点之间的距离称作非对称距离,详见[1]。非对称距离可以提高检索精度主要有以下两点原因:
由于没有对查询点二进制化,因此可以获取查询点更精准的位置信息,从而提高检索精度。在存储上,仅仅多额外存储一个查询点的非二进制化向量与检索过程的整个存储量级相比是可以忽略的。
非对称距离的实数量级与汉明距离的整数量级相比,可以对距离空间进行更浓密的划分。也就是说,非对称距离可以将汉明距离无法区分的二进制码重新排序,从而提高检索精度。
4 总结
我们简述了哈希方法的发展历史,并从一个新颖的角度对哈希方法进行清晰地分类。该文很适合对哈希方向感兴趣的读者快速找到他们感兴趣的分支。
参考文献
Yuan Cao, Heng Qi, Wenrui Zhou, Kato Jien, Keqiu Li, Xiulong Liu, and Jie Gui. "Binary hashing for approximate nearest neighbor search on big data: A survey." IEEE Access 6 (2018): 2039-2054.

历史文章推荐:
AI综述专栏 | 脑启发的视觉计算2017年度关键进展回顾(附PPT)
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI



