中科院自动化所刘成林研究员《文档分析与识别技术回顾与反思》[VALSE Webinar]|PPT下载

个人主页:
http://www.nlpr.ia.ac.cn/liucl
报告摘要:
自上世纪50年代以来,文字识别(广义地,称为文档分析)的研究和应用取得了巨大的进展。50-70年代以统计模式识别和特征匹配方法为主;80-90年代提出了很多结构分析方法,并且字符切分、字符串识别和版面分析受到重视;2000年以来继续在文档分析与识别的各个方面持续提高;2013年开始深度学习(深度神经网络)逐渐成为主导性的方法,使文字检测和识别的性能得到明显提升。随着识别精度不断提升和应用的展开,文字识别的可靠性、泛化性、可解释性要求开始凸显,在这些方面传统的模式识别和文字识别方法表现出一定的优势或互补性,与深度学习方法结合可开辟新的研究途径。本报告对文字识别领域历史上主要方法进行回顾,对当前主要方法的特点和一些最新研究动态进行分析,并对将来的研究提出一些建议。
请关注专知公众号(点击上方蓝色专知关注)
后台回复“DOCR” 就可以获取《文档分析与识别技术回顾与反思》PPT下载链接~






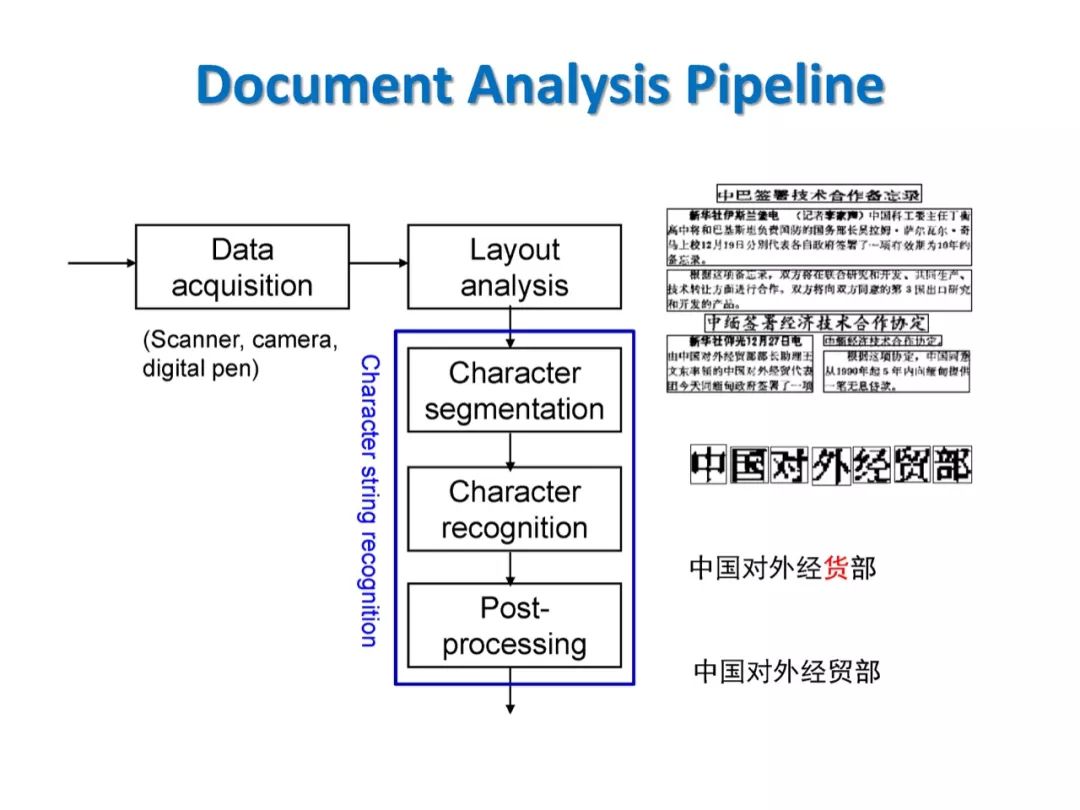
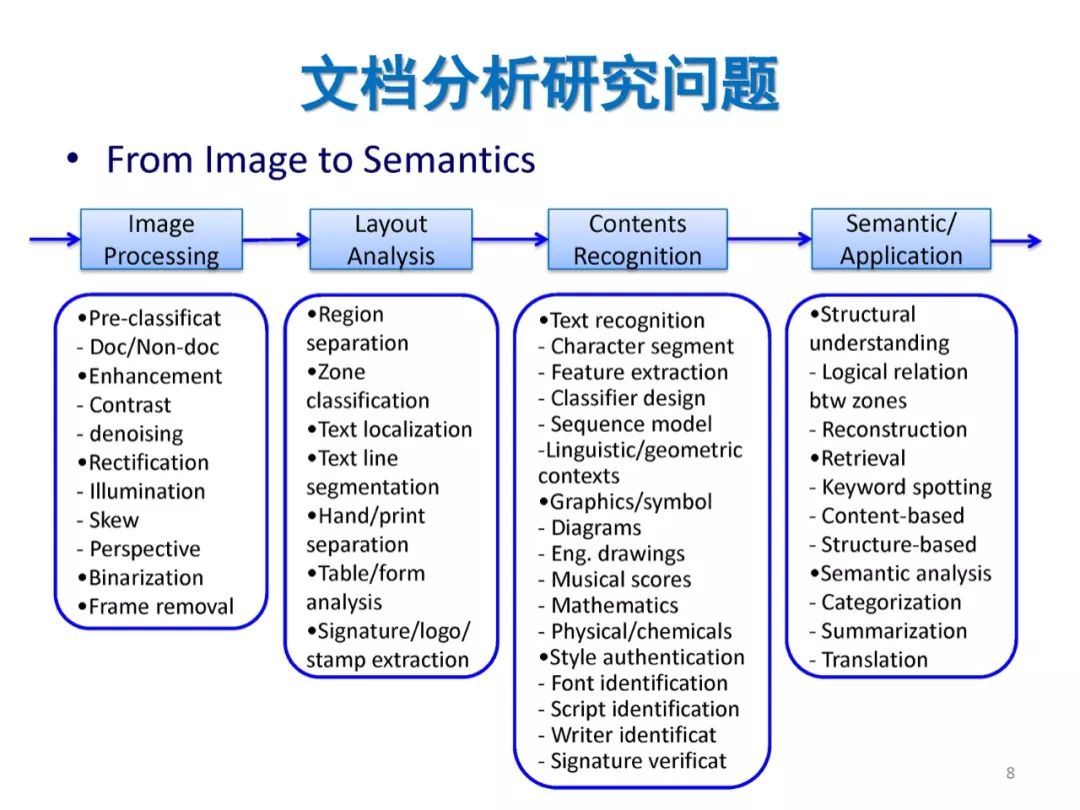



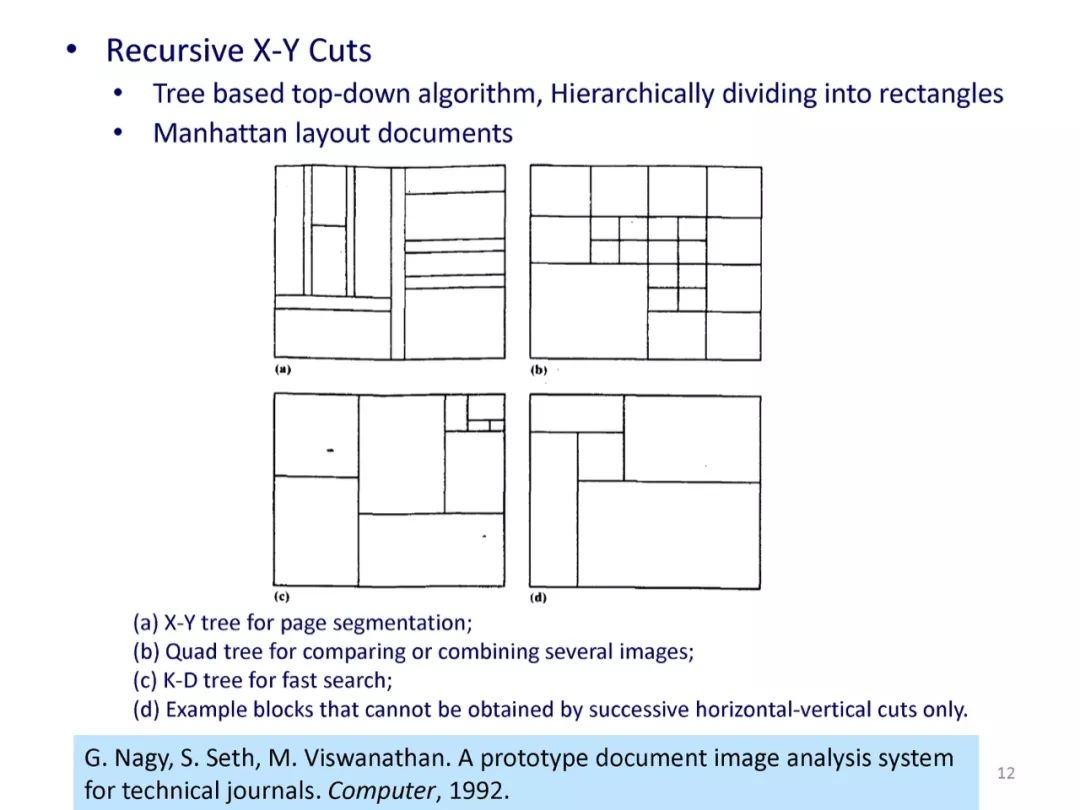



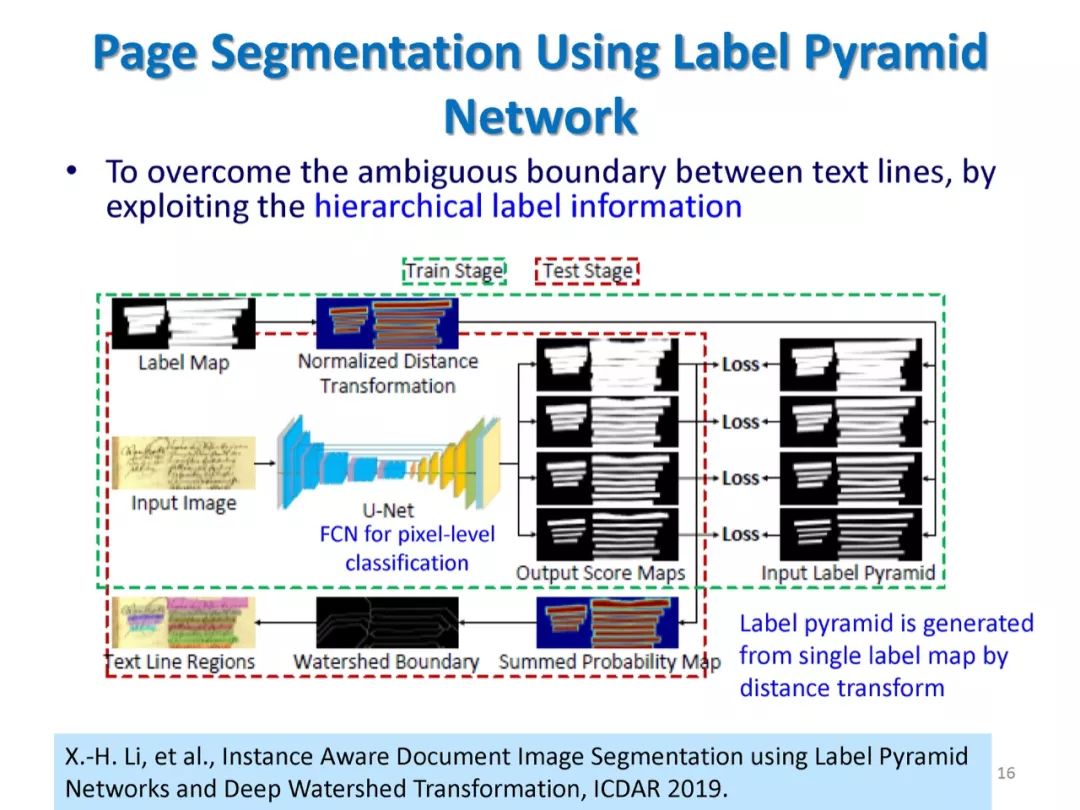




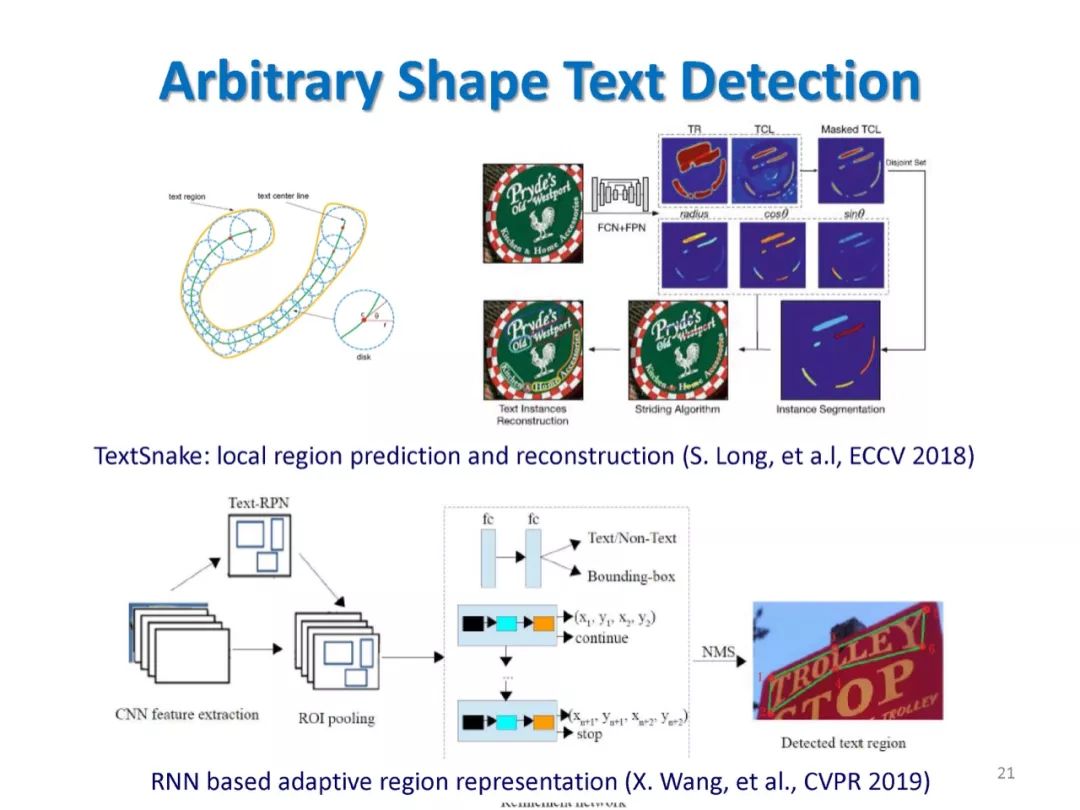
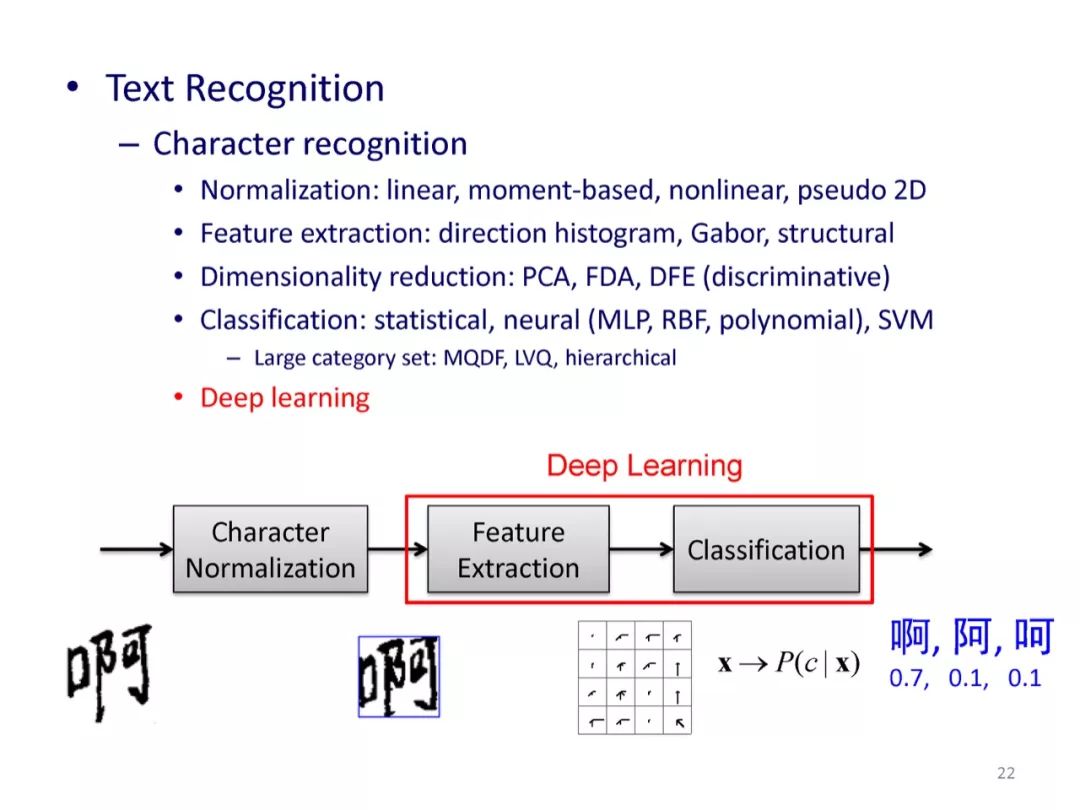






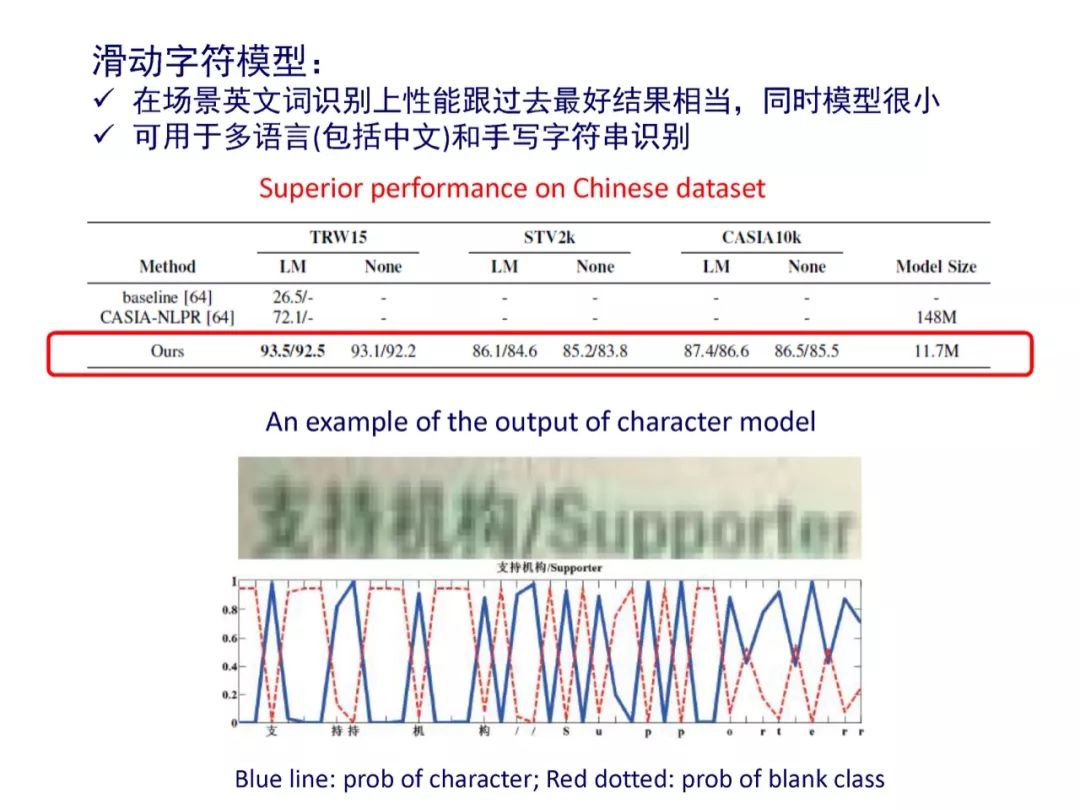

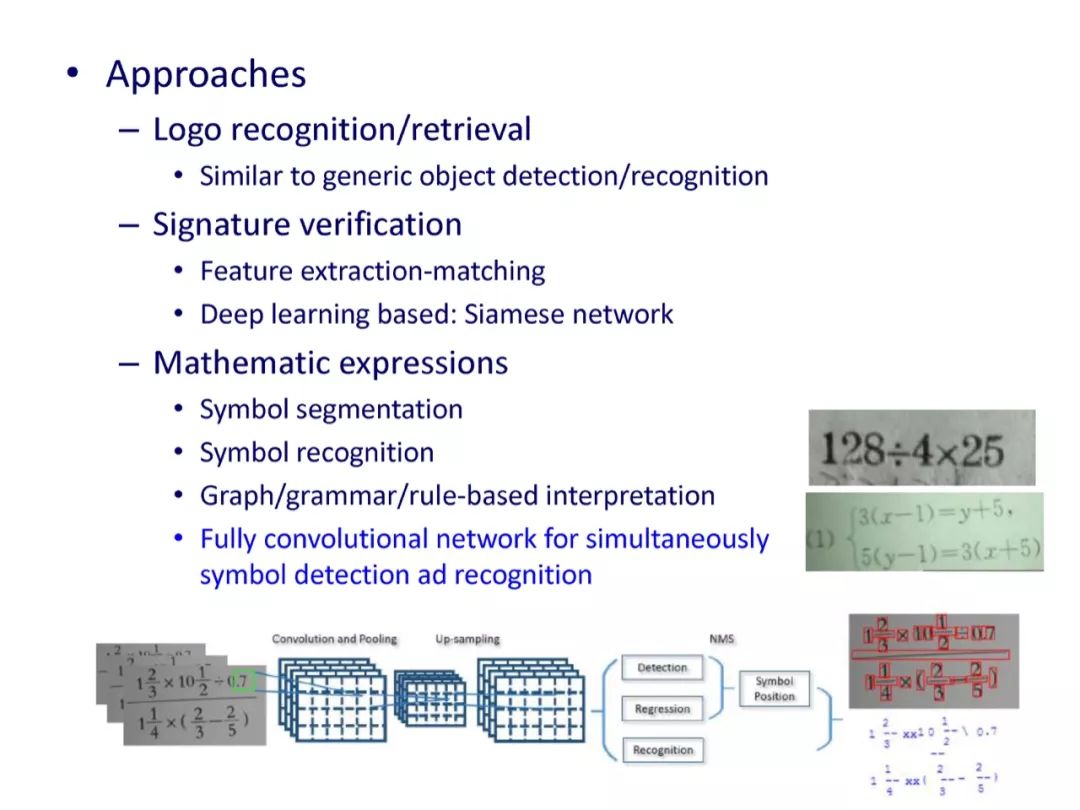



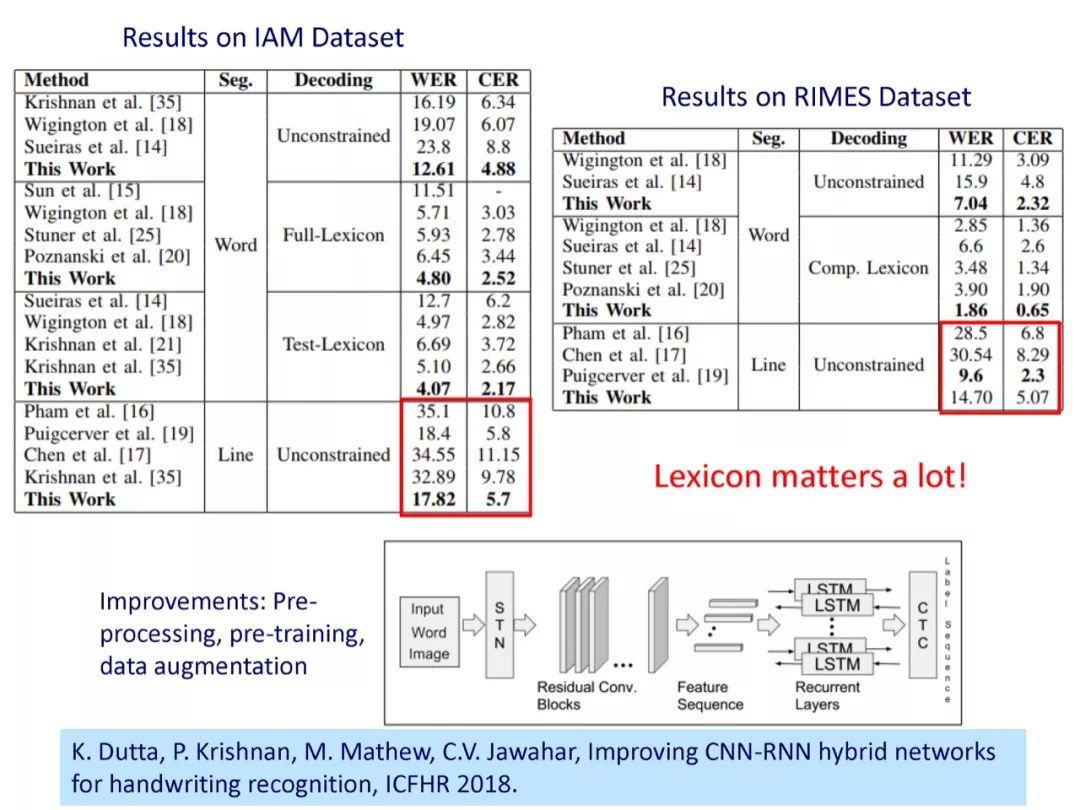

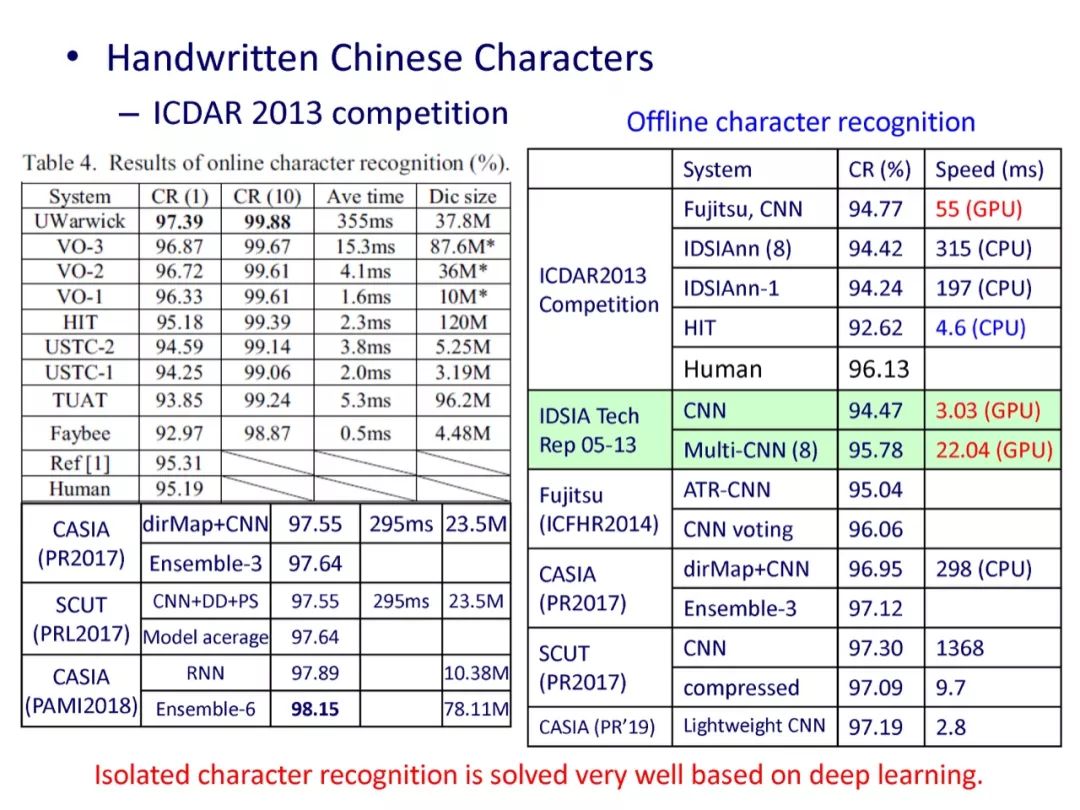

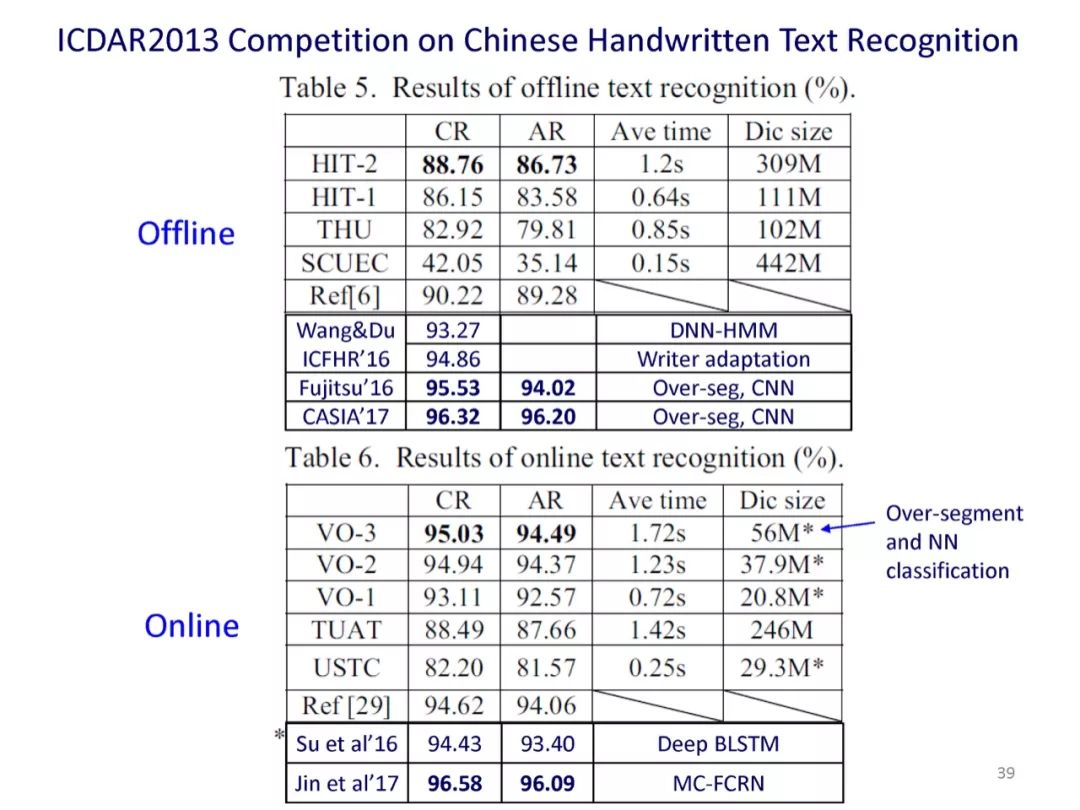





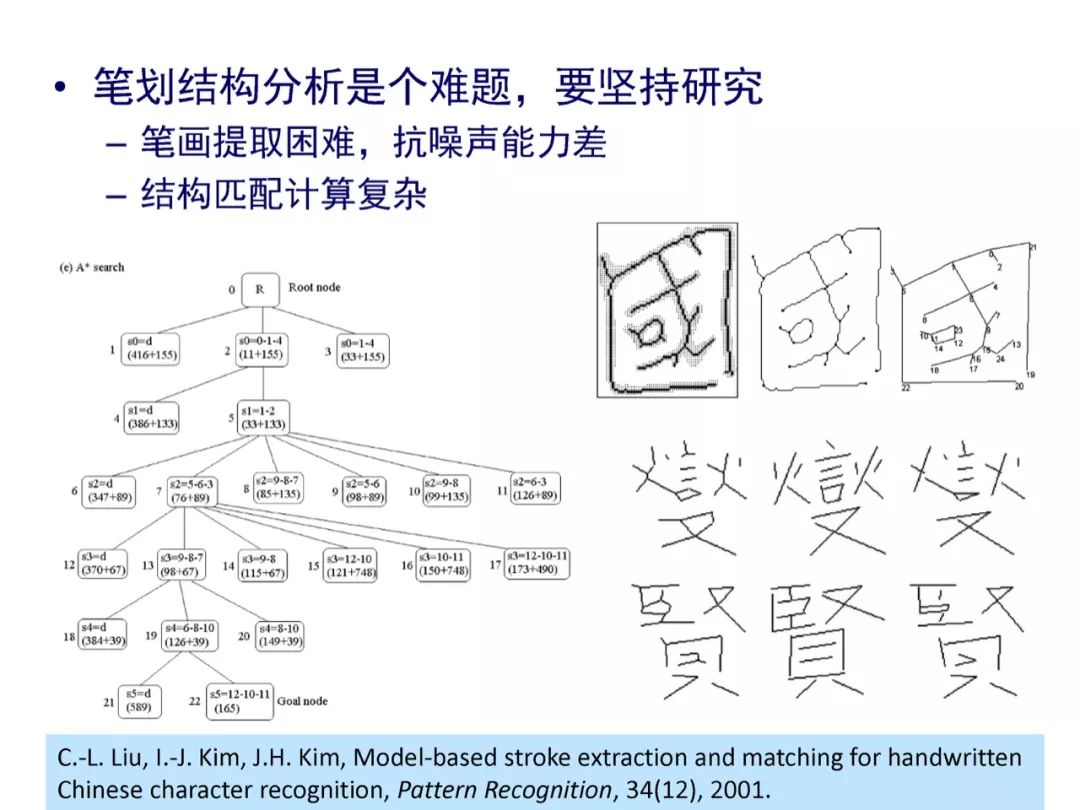




参考文献:
[1] G. Nagy, G.L. Shelton, Self-corrective character recognition systems, IEEE Trans. Information Theory, 12(2): 215-222, 1966.
[2] H. Fujisawa, Forty years of research in character and document recognition—an industrial perspective, Pattern Recognition, 41(8): 2453-2446, 2008.
[3] Cheng-Lin Liu, In-Jung Kim, Jin H. Kim, Model-based stroke extraction and matching for handwritten Chinese character recognition, Pattern Recognition, 34(12): 2339-2352, 2001.
[4] Xu-Yao Zhang, Yoshua Bengio, Cheng-Lin Liu, New benchmark for online and offline handwritten Chinese character recognition with deep convolutional network and adaptation, Pattern Recognition, 61: 348-360, 2017.
[5] Yi-Chao Wu, Fei Yin, Cheng-Lin Liu, Improving handwritten Chinese text recognition using neural network language models and convolutional neural network shape models, Pattern Recognition, 65: 251-264, 2017.
[6] Fei Yin, Yi-Chao Wu, Xu-Yao Zhang, Cheng-Lin Liu, Scene Text Recognition with Sliding Convolutional Character Models, arXiv:1709.01727, 2017.








