为什么深度学习泛化性好?Google发布82页《深度学习泛化性揭秘》论文提出相干性梯度理论来解释

来源:专知
本文为约2040字,建议阅读4分钟
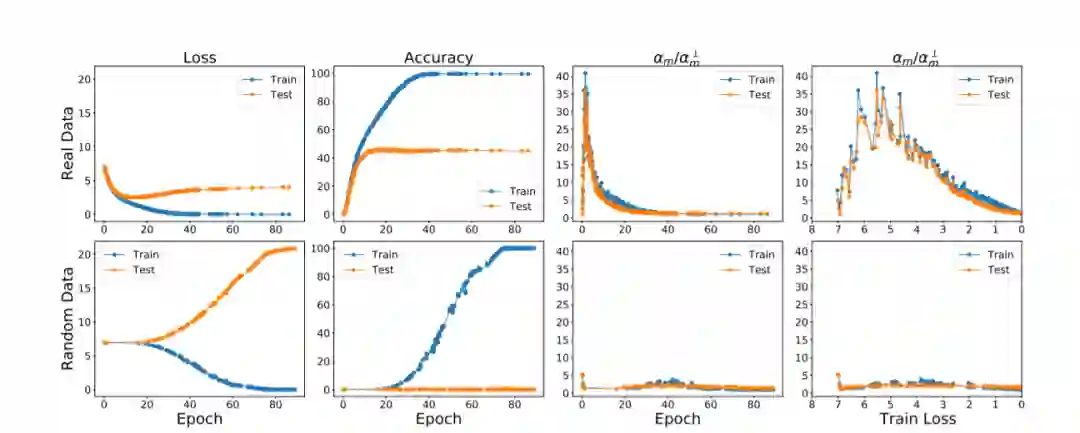
本文介绍了Google两位学者提出的在于训练过程中不同样例的梯度之间的交互作用以解释的深度学习为什么具有很好的泛化性。


便捷下载,请关注专知公众号
后台回复“DLG82” 就可以获取《为什么深度学习泛化性好?Google发布82页《深度学习泛化性揭秘》论文提出相干性梯度理论来解释》专知下载链接

登录查看更多
相关内容
专知会员服务
61+阅读 · 2022年3月22日
Arxiv
17+阅读 · 2021年6月18日


相关VIP内容
专知会员服务
61+阅读 · 2022年3月22日
相关资讯