国内首次!这家中国企业的语言AI实力被公认全球No.2!仅次于谷歌
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
AI成精,“逼疯”程序员;AI做高数,成绩超过博士;AI写代码,成功调教智能体……
看多了这种故事,你是不是也觉得,AI太卷了,要上天了。
今天回归本源,讲点不那么玄幻的。AI为什么会进化?底层其实没有秘密,无非是语言、视觉等几大基本功。
其中,语言能力对AI的智能水平有决定性影响。视觉研究怎么“看”,语言研究“听”、“说”和“理解”。
对人类来说,“听”、“说”、“理解”相加,基本等于思维能力,对AI,道理也差不多。
最近,咨询机构Gartner发布《云AI开发者服务关键能力报告》,对全球云服务商的AI能力做了排行。
语言AI这一项,第一名毫不意外是谷歌。
第二名比较惊喜,是阿里巴巴。这是榜单发布以来,中国公司在该领域第一次进入全球前三。
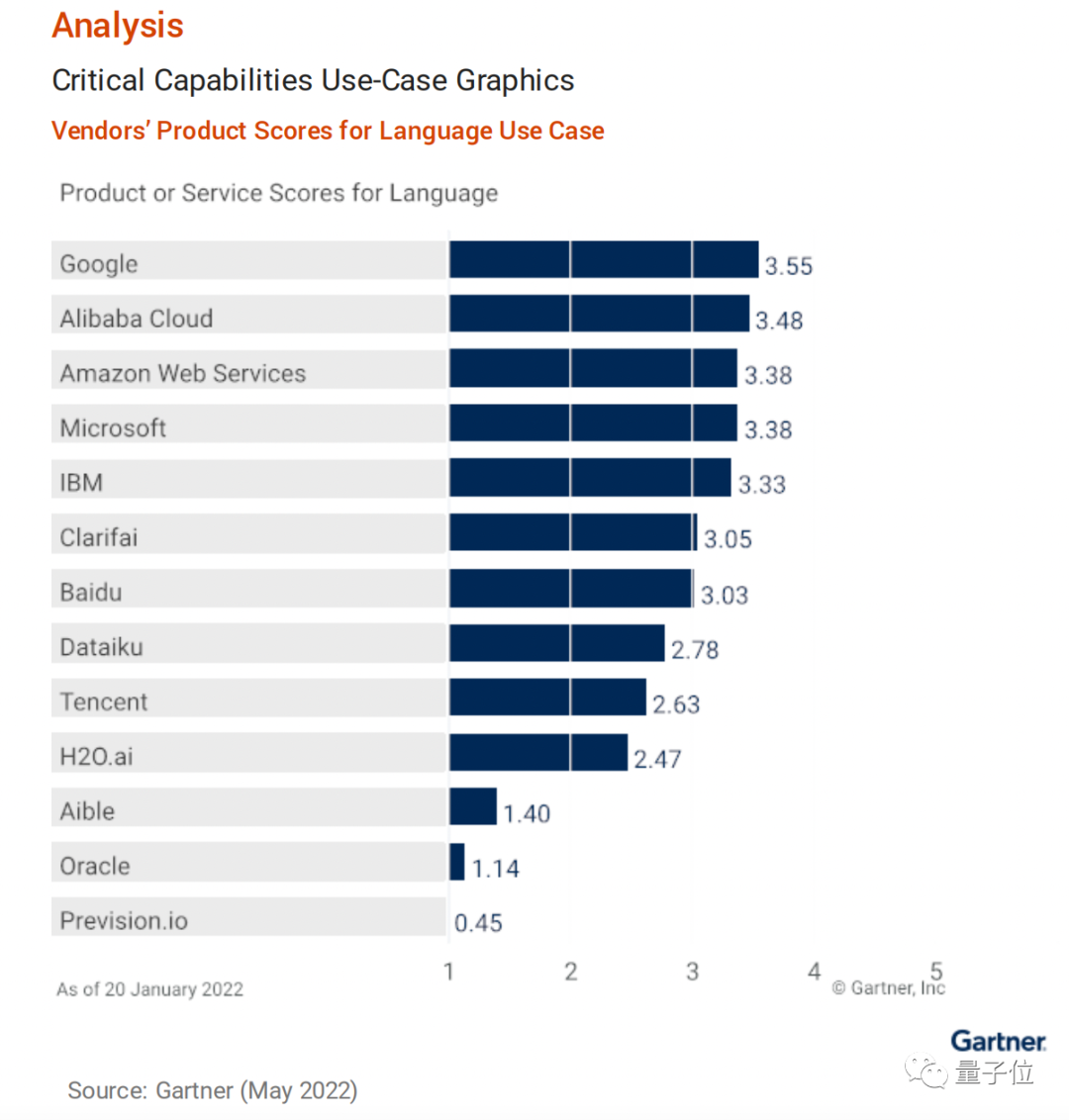
全球前十中,中国的BAT占了三席,成绩可谓是瞩目。
谷歌得分3.55,阿里得分3.48
语言AI,包含语音、语义两个大类。
语音负责让机器学会“听”和“说”;语义,也就是自然语言处理(NLP),负责让机器学会“理解”。
先来看看Gartner报告对语音语义的评判标准:
报告考察了云厂商语言AI的多个细分服务项,比如语音识别、语言理解等,并对每个服务项的功能实现程度进行评级。
Gartner将每种功能的程度分为5个等级,分别对应1-5分,分数越高则表明实力越强。

阿里云上的AI能力,主要包括:

阿里在语音识别、自然语言生成/语音合成、语言理解/处理、文本分析这几项关键能力都获得了最高分。
报告对每个细分项赋予权重,结合单项得分和项目权重计算总分,最终谷歌的语言AI以3.55的总分排名第一;阿里得分3.48,排名第二。
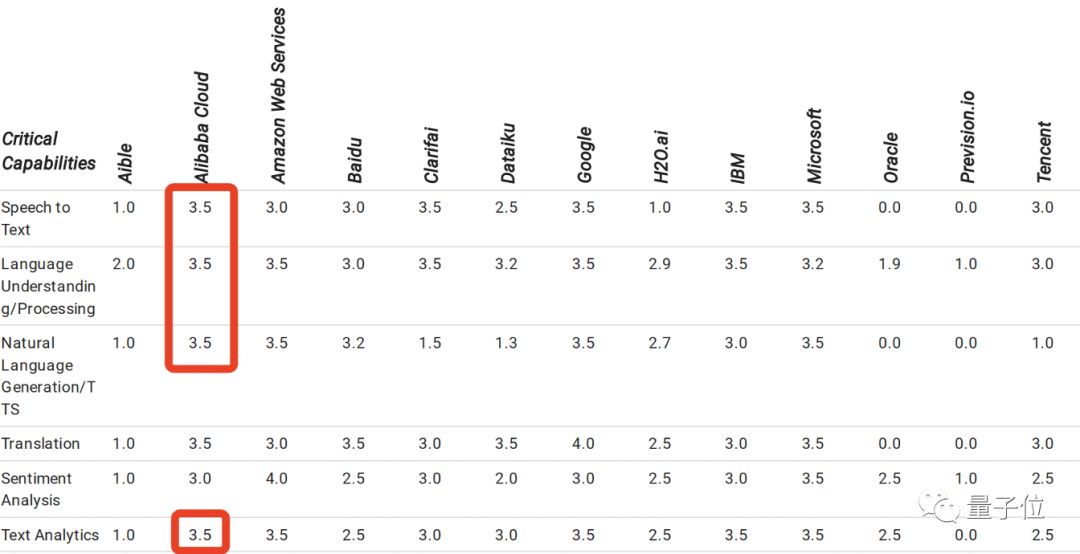
但除此之外更为细节的能力,Gartner的报告并未详细描述。
达摩院加持的云上AI
还是跟着Gartner报告,把“语言AI”一拆为二,看看什么是语音,什么是语义。
首先是语音层面的AI技术。

语音的应用,我们并不陌生,苹果Siri、微软小冰等AI助手,都是通过赋予机器语音能力,从而与人类产生交互。
每一个语音产品,背后都有一套语音技术软硬件作支撑。
阿里云所依托的,是达摩院在语音AI领域的深厚积累。
达摩院在语音AI领域最早以语音识别技术起家,技术能力涵盖语音识别声学模型和基础框架、说话人区分、语音合成声学模型和声码器、口语语言处理、联合优化的声学前端等。
2019年,阿里语音AI曾被MIT评选为当年度的“十大突破技术”,这背后的技术能力,就来自于达摩院。
以Gartner报告评估过的Speech to text、也就是我们常说的“语音识别”技术为例。
达摩院的语音AI,在常规的近场语音识别、远场语音场景、多人交谈“鸡尾酒会场景”语音识别技能之外,还有一些别致的长尾技能,比如“中英自由说”、“方言自由说”。

举个栗子
业界通行的端到端语音识别 (End-to-End ASR) 技术,在单语种任务上效果很好,但一切换到多语种混说 (Code-Switch)场景下,还是不太理想。
针对这类问题,达摩院语音实验室借鉴混合专家系统(Mixture of Experts)的思想。
在端到端语音识别模型中,对中文和英文分别设计了一个子网络,最后通过门控模块对每个子网络的输出进行加权。
为了减少模型参数量,中、英文子网络采用底层共享,高层独立的方式。最终使模型在中文、英文、中英文混说场景下都能取得比较好的效果。
在此基础上,达摩院融合了其自研的端到端语音识别技术SAN-M网络结构,打造出新一代的端到端中英自由说语音识别系统。

最后的效果就是:阿里的语音AI能在没有语种信息的前提下,大幅提升中英文混说场景下的识别性能。
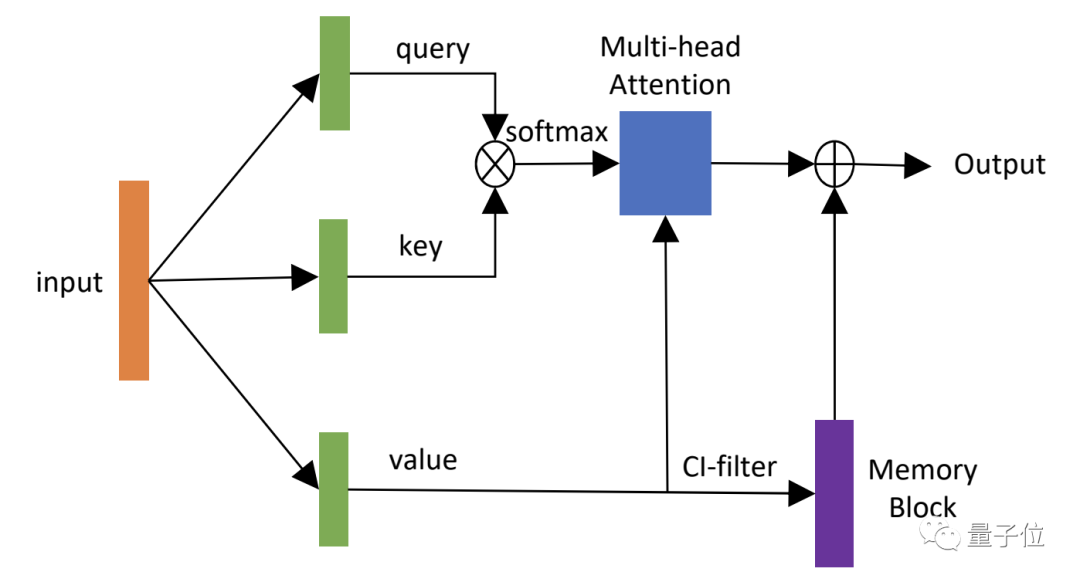
△ SAN-M网络结构框架
借鉴这套模型搭建思路,达摩院又解锁了“方言自由说”技能,打造了一套端到端方言自由说语音识别系统。
在不需要提供方言id的情况下,用一个模型就能识别14种常用方言,并且保证纯中文相对于单语模型的识别性能基本不降。
达摩院的AI技术主要通过阿里云对外提供服务,以“被集成”方式,广泛应用于运营商、电商、物流、电力等多个行业。
除了语音AI技术之外,阿里在语义层面同样形成了一套强大的技术体系。

语言本身就是“音”和“义”的结合体——“听到”诚可贵,“听懂”价更高。
人类语言并不难,几岁孩童便可轻松掌握一门语言。但计算机有自己的编程语言,要它理解人类语言难如登天。
NLP技术的进化,是AI从感知智能向认知智能演进的前提。而在过去十几年内,NLP技术进化最具标志性的事件,就是大规模预训练语言模型的出现。
阿里达摩院是业界最早开展大模型探索的团队之一,2019年就开始研发大规模预训练语言模型体系AliceMind,并以此作为技术底座,开展对内对外的技术服务。
“前大模型时代”,NLP技术解决问题的方法,是为每个任务单独设计模型。模型开发往往很复杂,缺乏算力、数据、技术力量的中小团队往往难以负担。
预训练语言模型出现后,AI的整体智能比过去大幅提升,NLP技术的赋能方式也逐渐变成“预训练+微调”范式。
也就是以通用的预训练模型为基础,加入简单的任务层、结合少量场景语料,以较低成本训练出优质的任务模型。
达摩院的大规模预训练语言模型体系,拥有阅读、写作、翻译、问答、搜索、摘要生成、对话等多种能力。
大模型通常并不直接用于解决应用问题,而是通过与具体任务、应用场景的结合,逐层孵化“中模型”、“小模型”。
在大模型体系基础上,达摩院语言技术实验室先后孵化了一系列“中模型”,包括:
通用预训练模型StructBERT
生成式预训练模型PALM
多语言预训练模型VECO
超大中文预训练模型PLUG
多模态预训练模型mPLUG
结构化预训练模型StructuralLM
预训练对话模型SPACE
表格预训练模型STAR等
这些模型各有专长,StructBERT、mPLUG和StructuralLM具备挖掘文本、图像、表格“结构”信息的能力,单语言生成模型PALM、多语言生成模型VECO、超大中文预训练模型PLUG都为语言生成任务(NLG)而生。
例如StructBERT,是达摩院在谷歌BERT模型基础之上所提出的优化模型,它可以让机器更好地掌握人类的语法、理解自然的语言。

StructBERT一经推出,便在当时GLUE基准上取得了SOTA(89.0分),并且还将SQuAD v1.1问题回答上的F1得分推至93.0的新高度。
再如多语言预训练模型VECO,曾拿下国际权威多语言榜单XTREME排名第一,成绩远超Meta和微软等国际巨头的模型。
多模态预训练模型mPLUG在视觉问答(VQA)任务上首次超过人类结果。对话预训练模型SPACE在10多个对话国际榜单和数据集上取得SOTA。
基于AliceMind技术,达摩院先后斩获了35个冠军,在某些领域的水平已经非常接近人类对语言理解的程度了。并且,该技术已面向全球开发者开源。
众所周知,大规模预训练模型开发成本极高,玩家通常集中于头部科技企业,但新的模型赋能范式,使得更多中小团队、个人开发者也能分享大模型的红利。
……
据了解,目前阿里达摩院语音语义领域的研究已有300百多篇论文被国际顶会收录,相关研究已应用于医疗、电力、电商等领域。
此前,在IDC发布的《2021H2中国AI云服务市场研究报告》中,阿里在语音和语义市场上的份额便取得了第一的成绩。
语音语义的前史和未来
在人工智能发展长河中,语音语义是最早起步的技术之一,也是人工智能的基石。
语音技术最早可以追溯到1952年,贝尔实验室的Davis等人研制出了世界上第一个能识别10个英文数字发音的实验系统Audry,从此拉开了语音识别发展的序幕。
语义技术更是可以追溯到1947年,当时英美科学家联手提出了利用计算机进行语言自动翻译的设想,机器翻译的诞生也正意味着打开了语义发展的大门。
于是,让机器“听到”、“听懂”人类语言这件事,便在那段时间起,成为了学界和产业界争相发展的技术高地。
各界的纷纷投入,也让工业界诞生了众多“史诗级”的产品,例如苹果在2011年发布的Siri,以及后来亚马逊、谷歌、微软等推出的Alexa、Google Assistant、Cortana等。
另一方面,这背后的技术也产生了革命性的迭代变迁,例如近几年Transformer、Bert等技术的爆发,极大地推动了语音语义技术的发展。

在这种大趋势的背后,更重要的意义在于语音语义已然是普通人“唾手可用”的技术。
以阿里为例,达摩院的机器翻译技术每天为国内200万中小商家翻译上亿文字,让不懂英语和小语种的商家也能把国货卖到全世界。
这样的技术还已应用到了“买票”场景。
去年年中,北京首都机场和大兴机场均开通了语音购票的服务,只需要乘客张张嘴说出目的地,便可以在1.6秒内快速完成选站。
事实上,未来任何硬件终端都可以集成语言AI技术,这样的应用空间是巨大的,这也正是国内外学者、科技巨头纷纷发力于此的原因。
就像中国计算机学会副理事长、澜舟科技创始人兼CEO周明所评价的那般:
自然语言技术是人工智能领域的核心技术,过去几年预训练模型的兴起已经让这一技术领域取得了质的飞跃,也加速了人工智能领域从感知智能走向认知智能的进程。
这一系列突破将给各行各业乃至个人生活带来巨大的价值,很高兴看到以阿里巴巴为代表的的中国科技公司在该领域进入了世界第一梯队。
也正如Gartner在此次报告中所述:
企业正在开发大规模语言模型,以提供更广泛的语言服务。主要云服务商正在利用其云基础设施开发专有语言模型。较小的供应商正在利用开源软件、数据和机器学习模型进行竞争。
但纵观语音语义的发展,有一点是始终未曾变化的,那就是它的理想目标——和机器对话,像在跟人类交流。
前不久谷歌研究员爆料“AI具备人格”的事件在科技圈引发了热议,虽然后来谷歌对其已经进行了辟谣,但其背后无法掩盖的事实是AI正在逐渐向人类逼近。
那么在未来,语音语义技术又将如何颠覆人们的生活,是值得期待了。
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



