bilibili 实时计算平台架构与实践


文章作者:郑志升@bilibili
内容来源:Flink中文社区
1. 痛点
开发门槛高:基于底层实时引擎做开发,需要关注的东西较多。包括环境配置、语言基础,而编码过程中还需要考虑数据的可靠性、代码的质量等。其次,市场实时引擎种类多样,用户选择有一定困难。

运维成本高:运维成本主要体现在两方面。首先是作业稳定性差。早期团队有 Spark 集群、YARN 集群,导致作业稳定性差,容错等方面难以管理。其次,缺乏统一的监控告警体系,业务团队需要重复工作,如计算延时、断流、波动、故障切换等。

AI 实时工程难:bilibili 客户端首页推荐页面依靠 AI 体系的支撑,早期在 AI 机器学习方面遇到非常多问题。机器学习是一套算法与工程交叉的体系。工程注重的是效率与代码复用,而算法更注重特征提取以及模型产出。实际上 AI 团队要承担很多工程的工作,在一定程度上十分约束实验的展开。另外,AI 团队语言体系和框架体系差异较大,所以工程是基建体系,需要提高基建才能加快 AI 的流程,降低算法人员的工程投入。

3. 基于 Apache Flink 的流式计算平台
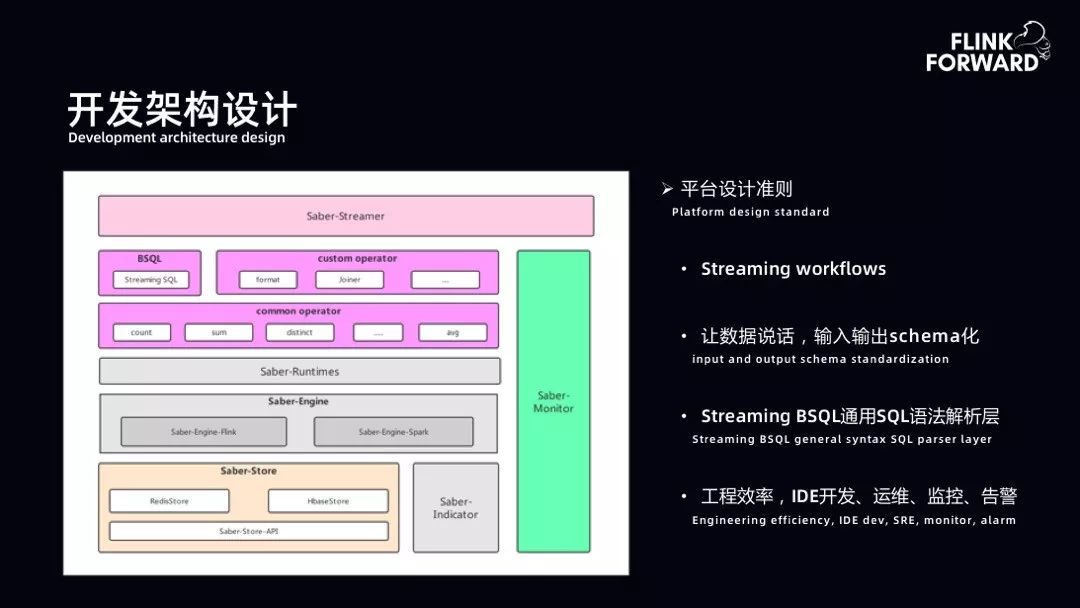
第一点,需要提供 SQL 化编程。bilibili 对 SQL 进行了扩展,称为 BSQL。BSQL 扩展了 Flink 底层 SQL 的上层,即 SQL 语法层。
第二点,DAG 拖拽编程,一方面用户可以通过画板来构建自己的 Pipeline,另一方面用户也可以使用原生 Jar 方式进行编码。
第三点,作业的一体化托管运维。

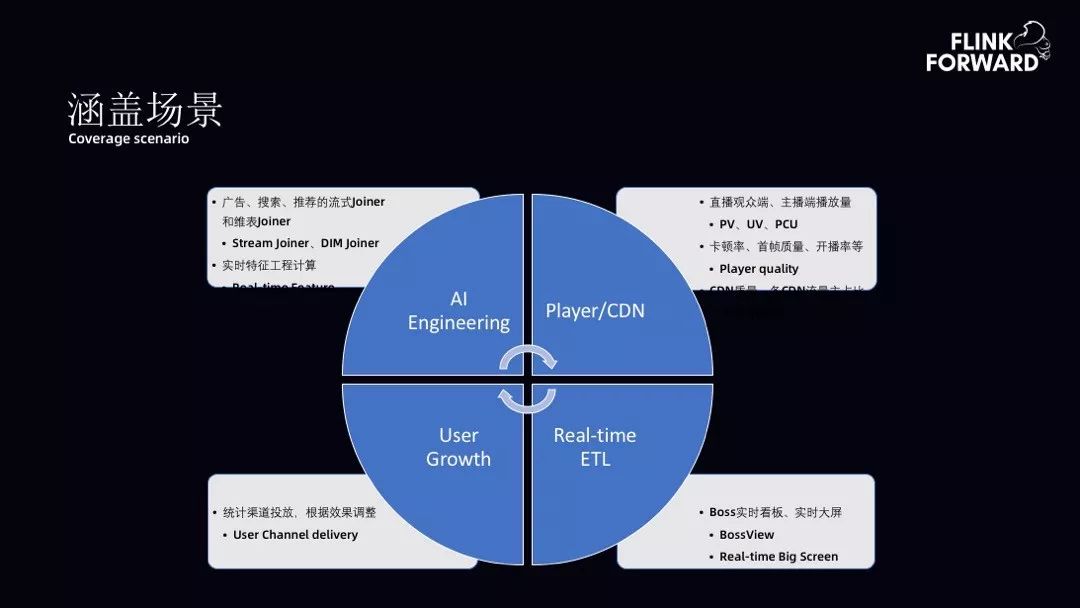
AI 工程方向,解决了广告、搜索、推荐的流式 Joiner 和维表 Joiner;
实时计算的特征支持,支持 Player 以及 CDN 的质量监控。包括直播、PCU、卡顿率、CDN 质量等;
用户增长,即如何借助实时计算进行渠道分析、调整渠道投放效果;
实时 ETL,包括 Boss 实时播报、实时大屏、看板等。
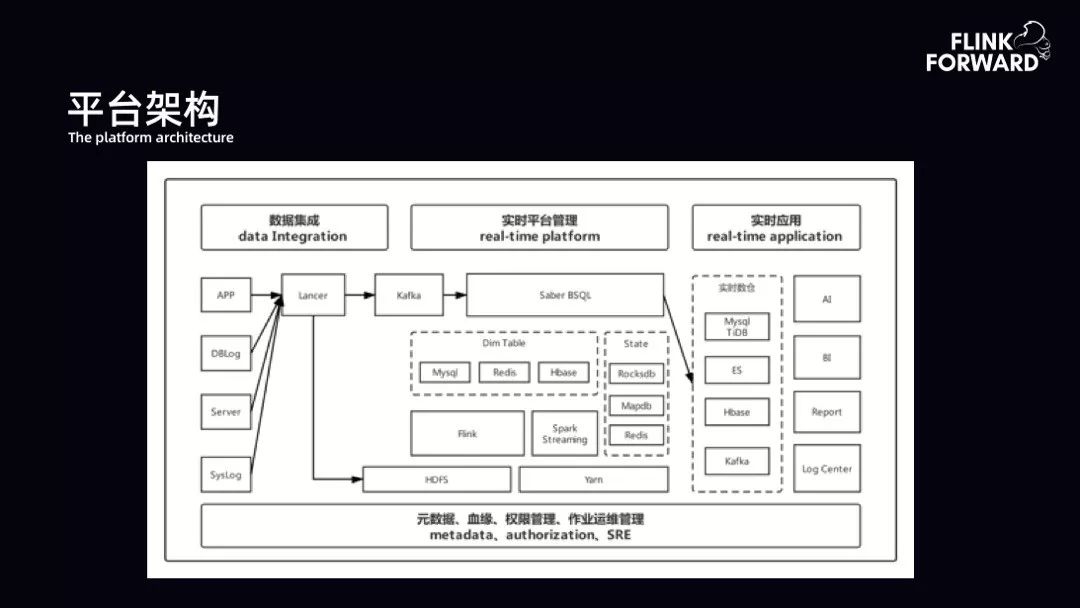
1. 平台架构
2. 开发架构设计
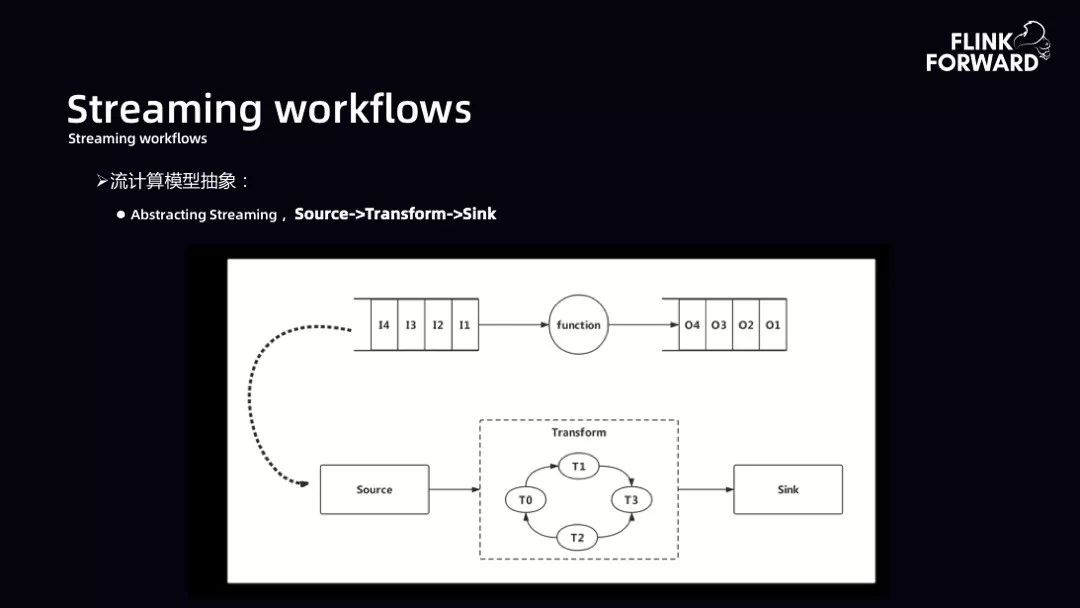
Streaming workflows:下图为流计算模型抽象。大数据计算引擎的本质是数据输入经过一个 function 得到输出,所以 function 本质是一个能够做 DAG 转换的 Transform。Saber 平台期望的流计算抽象形态是提供相应的 Source,计算过程中是一个 Transform 的 DAG,最后有一个 Sink 的输出。
让数据说话:数据抽象化。计算过程中的数据源于数据集成的上报。数据集成的上报有一套统一的平台入口。用户首先需要在平台上构建一个输入的数据源。用户选择了一个对应的数据源,平台可以将其分发到 Kafka、 HBase、 Hive 等,并且在分发过程中要求用户定义 Schema。所以在数据集成过程中,可以轻松地管理输入语言的 Schema。计算过程中,用户选择 Input Source,比如选择一个 HBase 的表或 Kafka 的表,此时 Schema 已是强约束的。用户通过平台提供的 BSQL 或者 DAG 的方式进行结果表或者指标的输出。
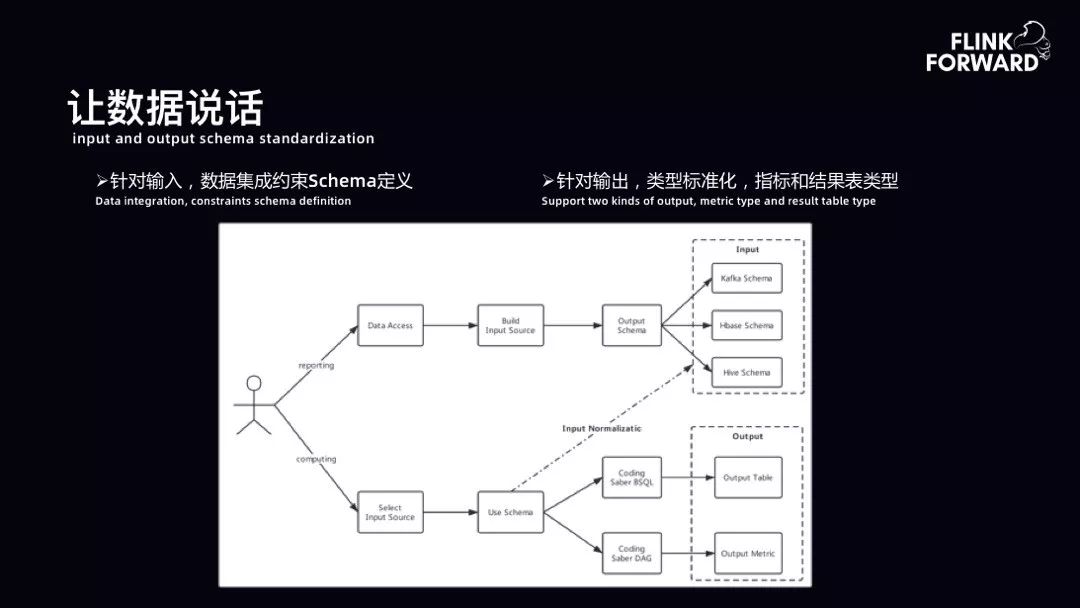
BSQL 通用设计:BSQL 是遵照 Streaming workflows 设计的思想,核心工作围绕 Source、Transform 以及 Sink。Transform 主要依托 Flink SQL,所以 BSQL 更多是在 Source 和 Sink 上进行分装,支持 DDL 的分装。此处 DDL 参照阿里云对外资料进行了扩展。另外,BSQL 针对计算过程进行了优化,如针对算子计算的数据倾斜问题采取分桶 + hash 策略进行打扫。针对 distinct 类 count,非精准计算采用 Redis 的 HyperLogLog。

BSQL 解析模型:BSQL 解析模型拓扑展开如下图。当用户提交了一个 SQL,目标是将 SQL 转化成树。之后可以获取 SqlNode 节点。SqlNode 节点中有很多元数据信息。在 SqlNode 树的情况下实现 Table 解析器,将不同的 SqlNode 节点转化成 Flink 相应的 Streamer 进行映射。
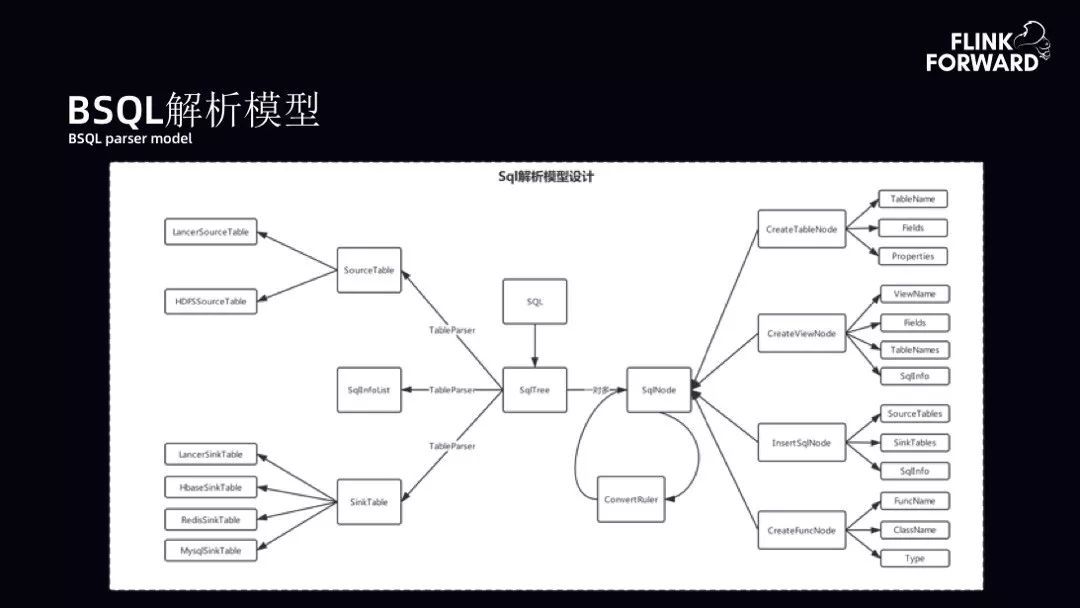
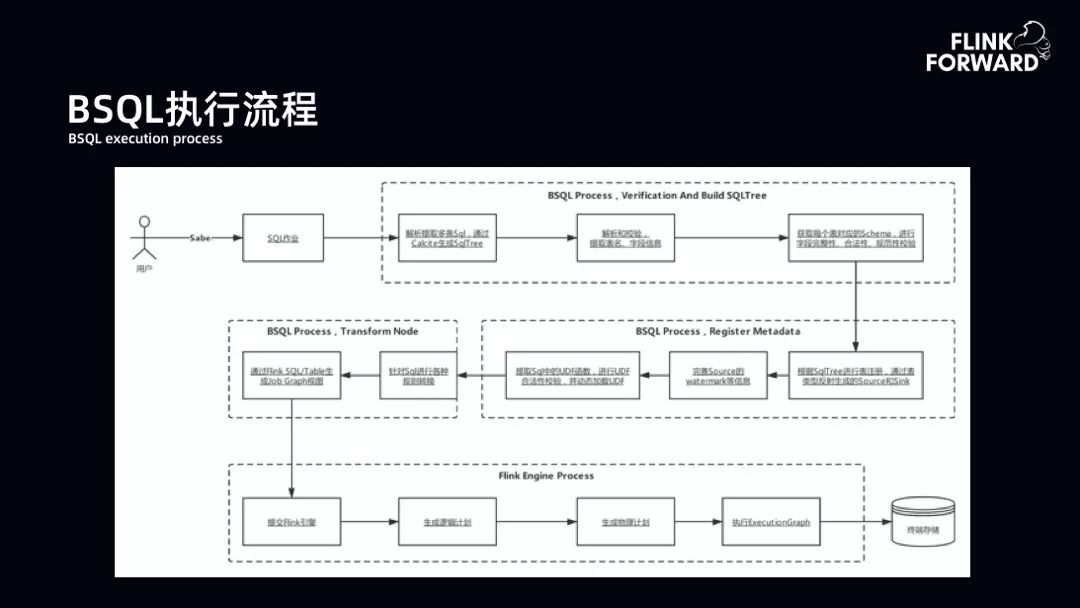
BSQL 执行流程:用户提交 SQL,BSQL 首先进行验证并构建 SQL 树。验证与构建主要是提取表名、字段信息,从元数据库中提取 schema 验证 SQL 的规范性、完整性和合法性。验证完成后,将输入表和结果表注册到 Flink 的运行时态,其中还包括 UDF 和 watermark 信息的完善。另外,平台对 SQL 有一些扩展。第三块是扩展的核心工作,将 SQL 树中扩展的子树转换为新的节点,然后将 SQL 的 DAG 提交到 Flink 上运行。
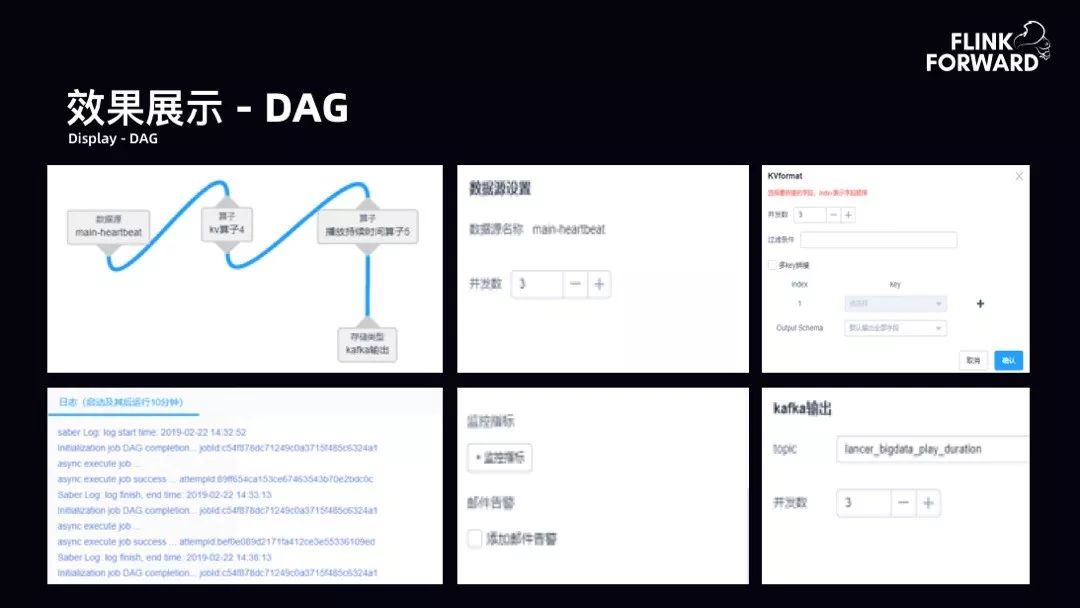
效果展示-DAG:如下图所示,DAG 产品展示,包括并行度的设计、日志、监控指标告警输出。
效果展示-BSQL:用户根据选择的表的输入源的 schema 编写相应的 SQL。最后选择相应 UDF 就可以提交到相应集群。
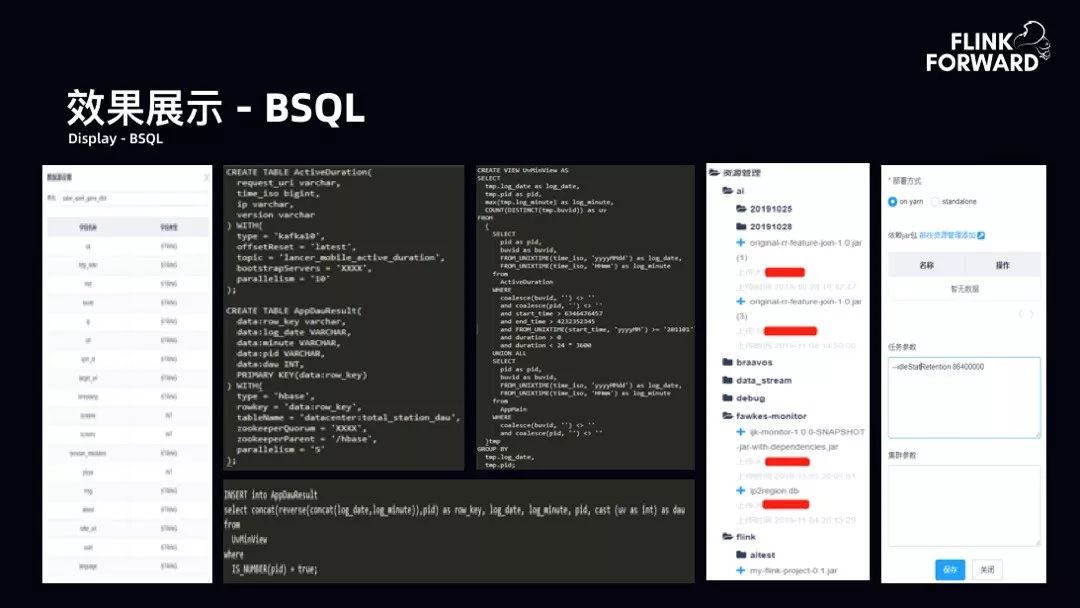
效果展示-作业调试:如下图所示为平台支持的作业调试。如果只有 SQL 开发却没有作业调试环节,是令用户痛苦的。故平台支持通过文件上传的方式以及线上采样的方式进行作业调试 SQL。
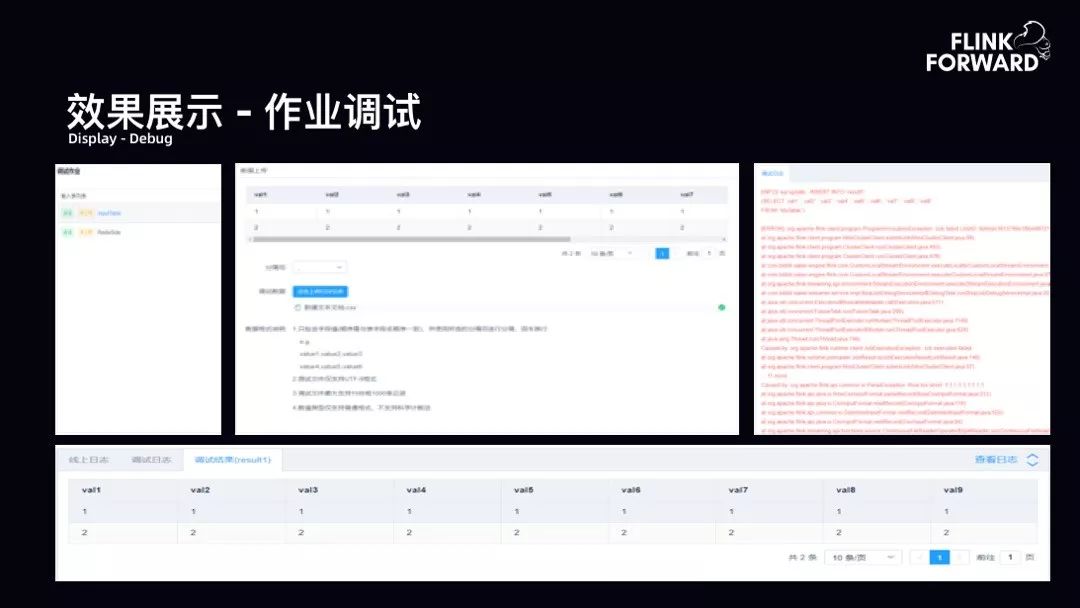
效果展示-作业运维:平台提供给用户一些监控指标、用户可自定义扩展的指标以及 bilibili 实现的一些特殊 SQL 的自定义指标。下图所示为部分队列的运行情况。
1. AI - 机器学习现状

2. 弊端与痛点
数据时效性:数据时效性无法得到保证。很多数据是通过离线方式进行计算,但很多特征的时效性要求非常高。
工程质量:单点工程不利于服务扩展以及稳定性保障。
工程效率:每一个实验都有较高门槛,需要做 Label 生产,Features 计算以及 Instance 拼接。在不同业务线,不同场景的推荐背后,算法同学做工程工作。他们掌握的语言不同,导致工程上语言非常乱。另外,流、批不一致,模型的训练在实时环境与离线批次环境的工程差异很大,其背后的逻辑相似,导致人员投入翻倍增长。
3. 模型训练的工程化

SJoin-工程背景:流量规模大,如 bilibili 首页推荐的流量,AI 的展现点击 Join,来自全站的点击量和展现。此外,不仅有双流 Join,还有三流及以上的 Join,如广告展现流、点击流、搜索查询流等。第三,不同 Join 对 ETL 的清洗不同。如果不能通过 SQL 的方式进行表达,则需要为用户提供通用的扩展,解决不同业务对 Join 之前的定制化 ETL 清洗。第四,非典型 A Left Join B On Time-based Window 模型。主流 A 在窗口时间内 Join 成功后,需要等待窗口时间结束再吐出数据,延长了主流 A 在窗口的停留时间。此场景较为关键,bilibili 内部不仅广告、AI、搜索,包括直播都需要类似的场景。因为 AI 机器学习需要正负样本均匀以保证训练效果,所以第四点问题属于强需求。
SJoin-工程规模:基于线上实时推荐 Joiner。原始 feed 流与 click 流,QPS 高峰分别在 15w 和 2w,Join 输出 QPS 高峰达到 10w,字节量高峰为 200 M/s。keyState 状态查询量维持在高峰值 60w,包括 read、write、exist 等状态。一小时 window 下,Timer 的 key 量 15w * 3600 = 54 亿条,RocksDBState 量达到 200M * 3600 = 700G。实际过程中,采用原生 Flink 在该规模下会遇到较多的性能问题,如在早期 Flink 1.3.* 版本,其稳定性会较差。
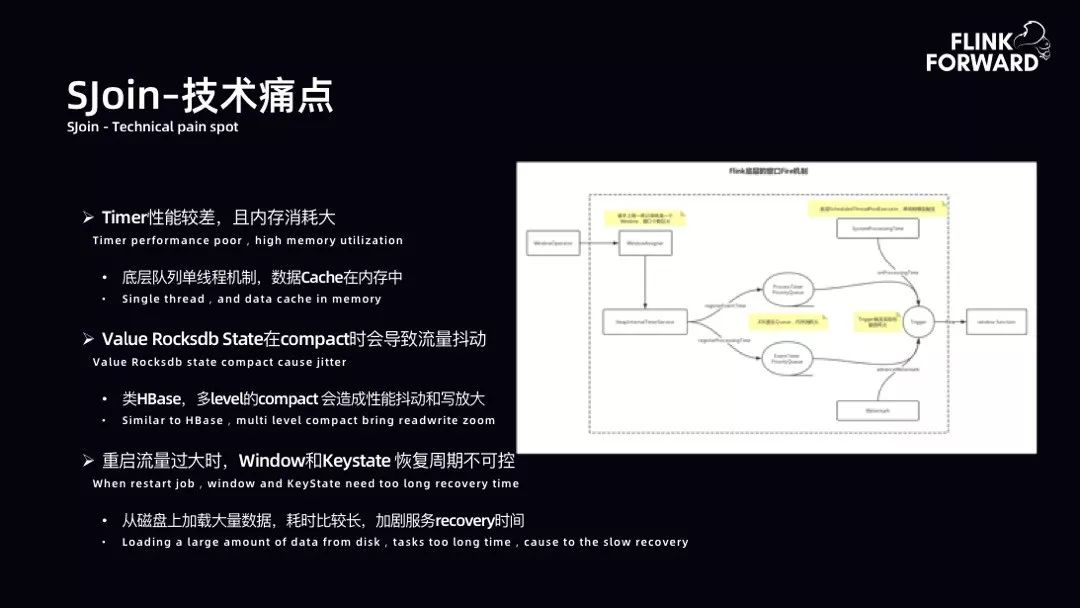
SJoin-技术痛点:下图是 Flink 使用 WindowOperator 时的内部拓扑图。用户打开窗口,每一条记录都是一个 Window 窗口。第一个问题是窗口分配量巨大,QPS 与窗口分配量基本持恒。第二个问题是 Timer Service 每一个记录都打开了一个窗口,在早期原生 Flink 中是一个内存队列,内存队列部分也存在许多问题。底层队列早期是单线程机制,数据 Cache 在内存中,存在许多问题。
SJoin-优化思路:首先是 Timer 优化升级。早期社区没有更好的解决方案时,bilibili 尝试自研 PersistentTimerManager,后期升级 Flink,采用基于 RocksDB 的 Timer。第二,启用 Redis 作为 ValueState,提高 State 稳定性。第三,扩展 SQL 语法,以支持非典型 A Left Join B On Time-based Window 场景下的 SQL 语义。
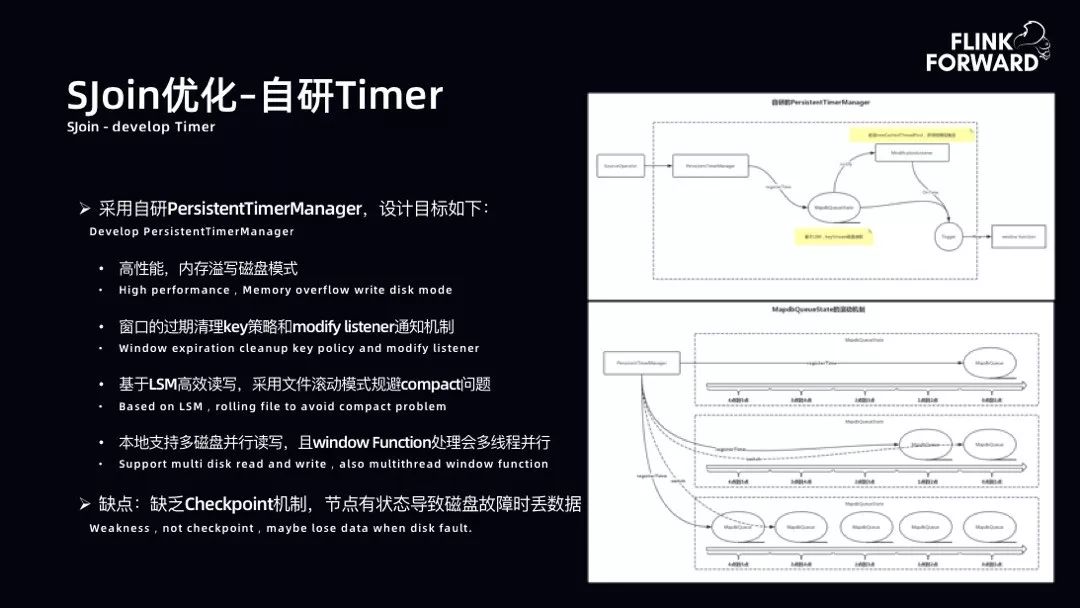
SJoin 优化-自研 Timer:实现将内存数据达到 Max 之后溢写到磁盘。底层用 MapDB 做磁盘溢写。磁盘溢写原理是 LSM 模型,同样存在数据抖动问题。由于窗口是 1 小时,相当于数据以 1 小时为单位进行 State 管理。如下图右侧所示,当 0 点到 1 点的 1 小时,由于记录在 1 小时后才会吐出,数据进来只有写的动作。在 1 点到 2 点,数据会写入到新的 State,0 点到 1 点的 State 已经到达窗口时间,进行数据吐出。自研 Timer 很好地解决了数据的读写问题和抖动问题。但是由于自研 Timer 缺乏 CheckPoint 机制,如果节点上的磁盘出现故障,会导致 State 数据丢失。
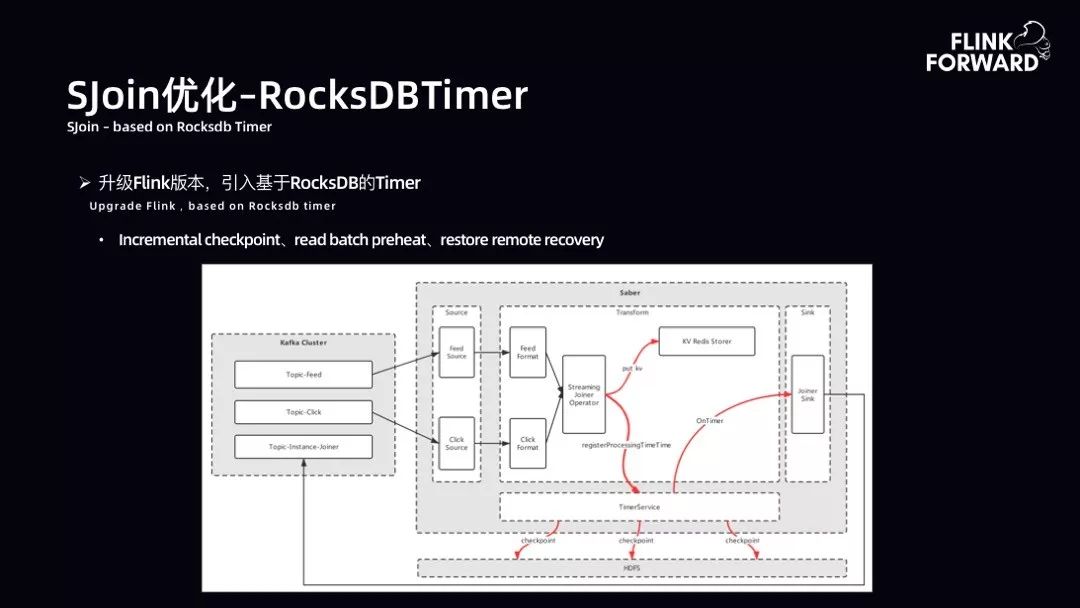
SJoin 优化-RocksDBTimer:升级 Flink 版本,引入基于 RocksDB 的 Timer。升级后架构如下图所示。数据从 Kafka 获取 Topic-Feed 和 Topic-Click,首先对其进行一层清洗,然后进入自定义的 Joiner Operator 算子。算子做两件事,将主流数据吐到 Redis 中,由 Redis 做 State,同时将需要开窗口的 Key 存储注册到 Timer Service 中。接下来利用 Timer Service 原生的 CheckPoint 开启增量 CheckPoint 过程。当 OnTimer 到达时间后,就可以吐出数据。非常此方案契合 SJoin 在高吞吐作业下的要求。
SJoin 优化-引入 KVStore:Flink 原生 State 无法满足要求,在对 Value、IO 要求高时抖动严重,RocksDBState 实际使用中会出现抖动问题。对此,bilibili 尝试过多种改进方案。开 1 小时窗口,数据量约 700G,双流 1 小时窗口总流量达到 TB 级别。采用分布式 KVStore 存储,后续进行压缩后数据量约 700G。

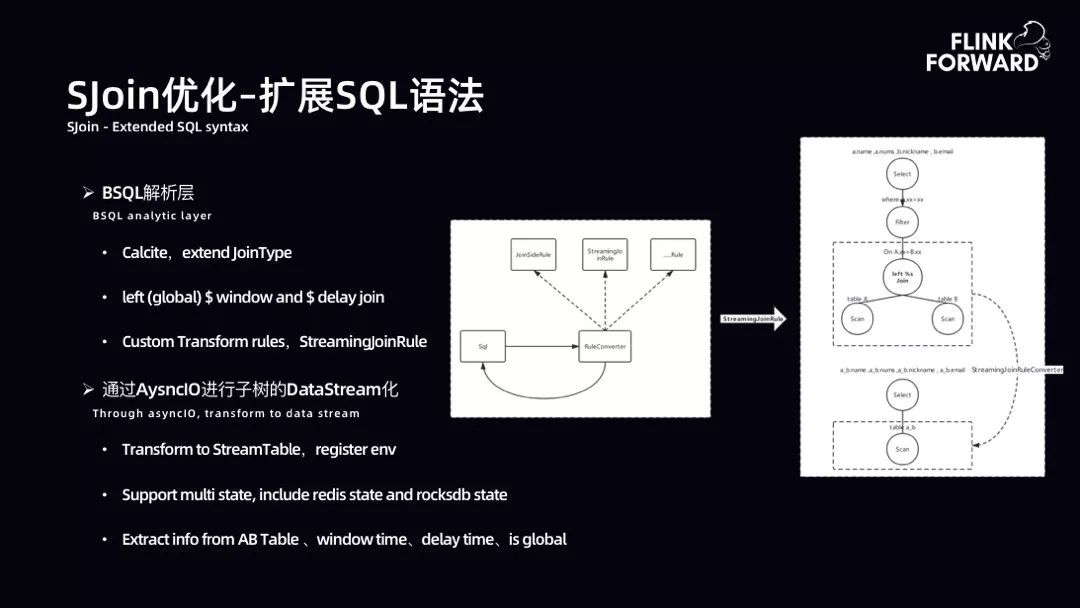
SJoin 优化-扩展 SQL 语法:扩展 SQL 的功能诉求是展现流等待 1 小时窗口,当点击流到达时,不立即吐出 Join 完成的数据,而等待窗口结束后再吐出。故扩展了 SQL 语法,虽然目前未达到通用,但是能满足诸多部门的 AI 需求。语法支持 Select * from A left(global)$time window and $time delay join B on A.xx=B.xx where A.xx=xx。给用户带来了很大收益。

DJoin-工程背景:bilibili 对于维表数据要求不同。比如一些维表数据很大,以 T 为单位,此时如果用 Redis 存储会造成浪费。而有一些维表数据很小,如实时特征。同时,维表数据更新粒度不同,可以按天更新、按小时更新、按分钟更新等。
另外,维表性能要求很高。因为 AI 场景会进行很多实验,例如某一个特征比较好,就会开很多模型、调整不同参数进行实验。单作业下实验组越多,QPS 越高,RT 要求越高。不同维表存储介质有差异,对稳定性有显著影响。调研中有两种场景。当量比较小,可以使用 Redis 存储,稳定性较好。当量很大,使用 Redis 成本高,但 HBase CP 架构无法保证稳定性。

DJoin-工程优化:需要针对维表 Join 的 SQL 进行语法支持。包括 Cache 优化,当用户写多条 SQL 的维表 Join 时,需要提取多条 SQL 维表的 Key,并通过请求合并查询维表,以提高 IO,以及流量均衡优化等。第二,KV 存储分场景支持,比如 JDBC、KV。KV 场景中,对百 G 级别使用 Redis 实时更新实时查询。T 级别使用 HBase 多集群,比如通过两套 HBase,Failover+LoadBalance 模式保证 99 线 RT 小于 20ms,以提高稳定性。

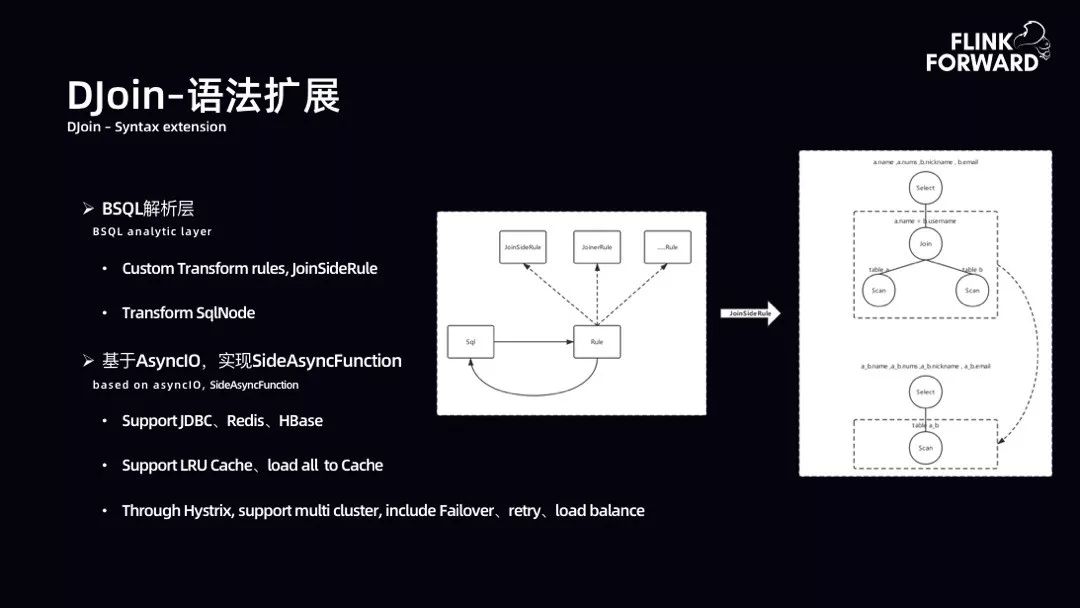
DJoin-语法扩展:DJoin 语法扩展与 SJoin 语法扩展类似,对 SQL 树子树进行转化,通过 AsyncIO 进行扩展,实现维表。
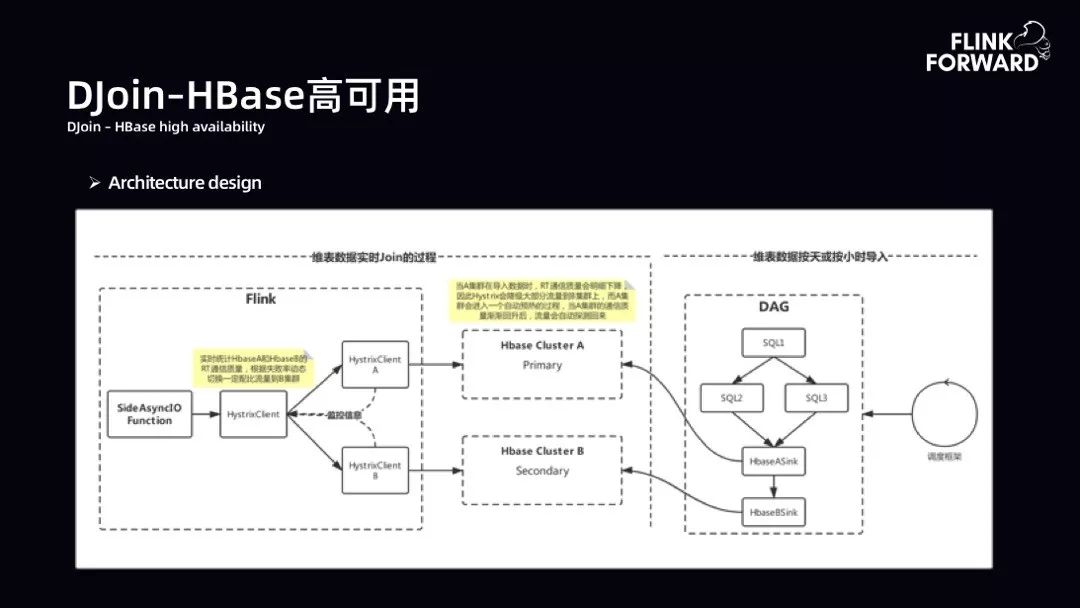
DJoin-HBase 高可用:维表数据达到T级别时使用 HBase 进行数据存储。HBase 高可用性采用双 HBase 集群,Failover AB 模式。这时需要考虑两个问题。第一是数据更新机制。数据更新可以是按小时或按天,采用 HFile BulkLoad 模式,串行+ Interval 间隔导入,导入后同步数据预热,以此保证两套HBase 集群的稳定性。第二是数据查询机制。引入 Hystrix 实现服务熔断、降级回退策略。当 A 集群可用性下降时,根据 AB 的 RT 质量,动态切换一定数据到B集群,以保证数据流量均衡。
下图为 HBase 双集群架构。右侧是离线,以天为单位,通过调度框架拉起一个 DAG 进行计算。DAG 的输出经过两层串行的 HBase 的 Sink,串行可以保证数据先写完 A 再写 B。运行时态中通过 Flink、AsyncIO 方式,通过两层 HystrixClient。第一层 HystrixClient 主要对第二层 HystrixClient HBase 的 RT 通信质量进行收集,根据 RT 通信质量将流量动态分发到两套 HBase 集群中。在 A 集群稳定性很好时,流量都在 A 集群跑。当 A 集群出现抖动,会根据失败率动态切换一定配比流量到 B 集群。
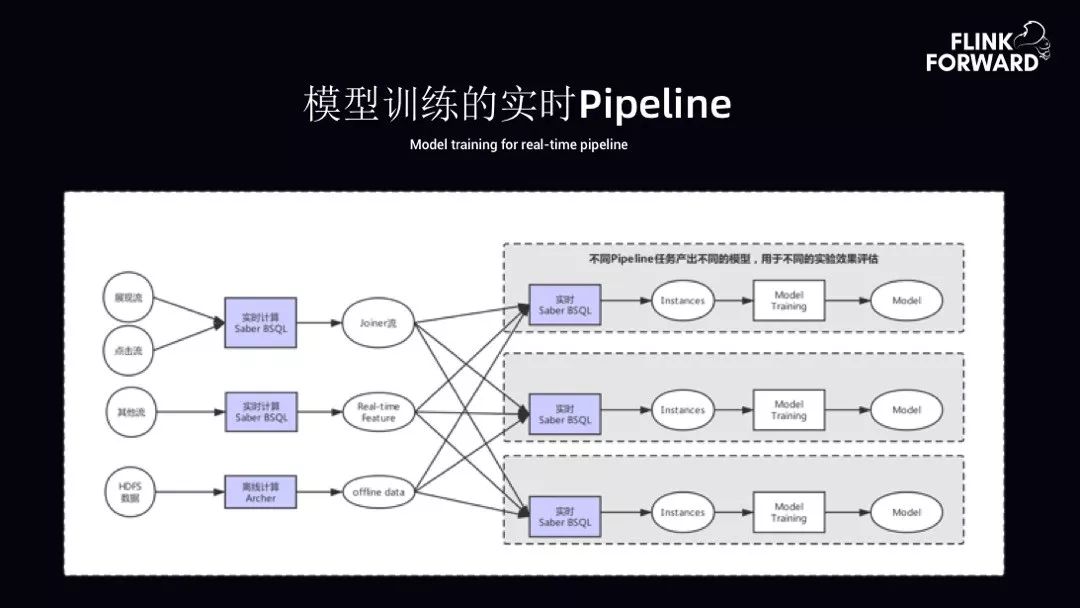
4. 模型训练的实时 Pipeline
1. Saber-基础功能完善
今天的分享就到这里,谢谢大家。
分享、收藏、点赞、在看,给个4连击呗~
会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、收藏、点赞、在看,给个4连击呗!👇





