统计挖掘那些事(四)-9个相关R先生的故事(理论+动手案例)


浩彬老撕,R语言中文社区特邀作者,好玩的IBM数据工程师,立志做数据科学界的段子手。
个人公众号:探数寻理
往期回顾:

上一期咱们在多元回归分析中提到(上期传送门:统计挖掘那些事-超详尽回归分析指南(理论+动手案例)),决定系数R^2是我们判断回归方程拟合效果的一个重要标准,但其实关于R的内容实在是太多了,所在咱们这期单独聊聊R先生的故事。
没错,这里有9个不同的R先生~
某天,一个骚年郎找到老师老师说,感觉对回归的奥妙还是参悟不深~
于是骚年为了得到R同志的认可,就开始了慢慢征程~
但是,当他看到这一群R先生后......
相信骚年郎的内心是崩溃的~
好了,虽然关于R的概念很多,但是其实都属于相关分析以及回归分析的范畴,接下来就让我们逐个击破吧。
一、理论部分
在正式进入讲解推导之前,这里先解释一下相关分析与回归分析的差别(均在线性范畴探讨)。
相关分析:研究两个随机变量之间的线性相关关系;
回归分析:研究自变量与因变量之间的的线性依联关系;
虽然相关分析与回归分析都是研究变量之间的联系,但是具体下来有如下差别:
(1)相关分析研究的是两个随机变量的关系,这两个变量之间是平等的,并没有主次,因果之分;而回归分析研究是研究自变量与因变量之间的关系,对因变量的解释相对是处于一个比较重要的位置;
(2)相关分析研究的是两个变量,回归分析研究的是两类型变量(自变量与因变量),虽然因变量只有一个,但是回归分析的自变量往往不止一个;
(3)相关分析研究随机变量间的线性相关程度,而回归分析不仅仅只是揭示自变量与因变量的密切程度,还进一步研究它们之间的定量关系式,借助于关系式,我们可以进一步应用于预测与控制;
当然,我们并不需要拘泥与概念的范围,因为在实际应用当中,两者还是密不可分的。
那么接下来,我们将介绍如下概念:
1.简单相关系数与样本相关矩阵
2.决定系数与复相关系数
3.调整的决定系数
4.偏决定系数与偏相关系数
5.部分决定系数与部分相关系数
1.简单相关系数与样本相关矩阵
相关系数:相关系数是研究两个随机变量之间的线性相关程度指标,计算公式如下:

虽说相关系数研究的是两个变量之间的关系,但是假如分析过程中,我们存在多个自变量的话,那我们就需要分别计算这些变量之间的相关系数,为方便研究,我们写成矩阵形式,称之为样本相关矩阵
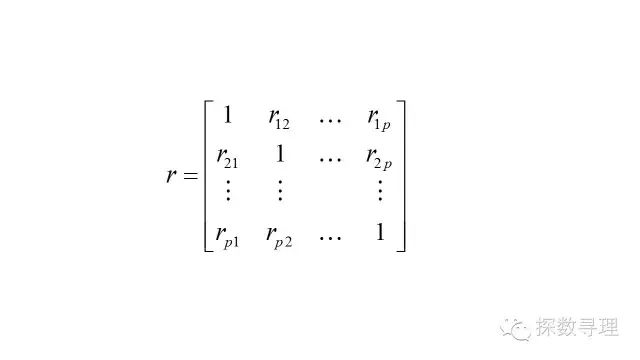
根据相关系数的特性,可以知道上述的样本相关矩阵是一个对称矩阵
2.决定系数与复相关系数
正如我们所指出的,相关系数r研究的是两个随机变量之间的关系。但在回归分析中,更重要的一点是评价出整体自变量x,即所有的自变量能否很好地解释出y的变化,因此我们需要一个对整体自变量x的评价指标,这个就是R方,我们称之为决定系数:
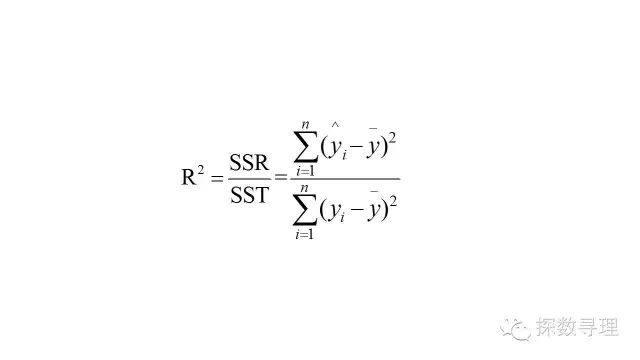
如我们在F检验中所讨论的,在整个分解式中,回归平方和(SSR)反映的是能够通过自变量x解释的部分,因此非常直观地,我们可以认定回归平方和所占的比重越大,则残差平方和越小,就越能证明回归的效果越好。
决定系数的范围同样在[0,1]区间内,决定系数越大,说明回归效果越好;
进一步地,我们对决定系数开平方根,将得到复相关系数。值得注意的是,复相关系数的含义是,因变量y与全体自变量x之间的关系,而简单相关系数只是两个变量之间的关系。同时,复相关系数的范围是[0,1],而简单相关系数的范围是[-1,1];

3.调整的决定系数
但值得注意的是,R方虽然经常被用作与评估线性回归模型的拟合好坏,但是却也存在着明显的不足:例如自变量越多,R方总是不减(事实上,随着自变量数目的增加,R方一般都是会增加)的,而不管这个自变量本身是否真的有效。

证明:

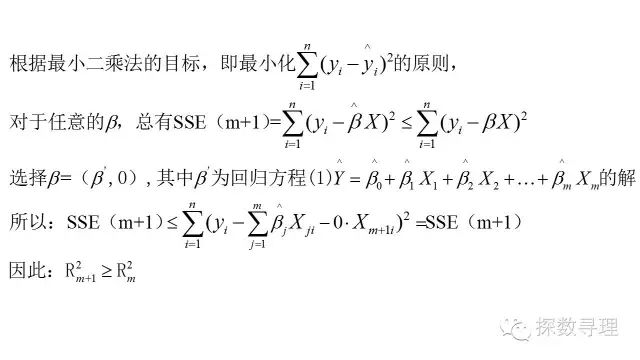
正如上述所证明的,随着自变量个数的增加,决定系数也随之增大,当自变量足够多的情况下,决定系数也将表现得足够的“好”,极端情况下,当需要估计参数的数量与样本数量一致时,决定系数将能够达到1.
实际上,这种“好”是通过增加模型复杂度(也意味着牺牲了了残差自由度)所得到的,而随着模型复杂度越高,我们模型过拟合的情况可能就越严重,泛化能力就越差。关于模型过拟合的问题,浩彬老撕会在后面单独写一篇文章详细介绍。
因此为了避免这种无用的假象,我们需要在决定系数公式当中引入惩罚项,对于这个增加惩罚项的决定系数,我们一般称之为调整决定系数:

从公式可以看到,调整的R^2可以是一个负数,它总是小于/等于R方。另外不同于原有的R方,它只有在引入真正有助于分析的变量时,它才会得到增加。
4.偏决定系数与偏相关系数
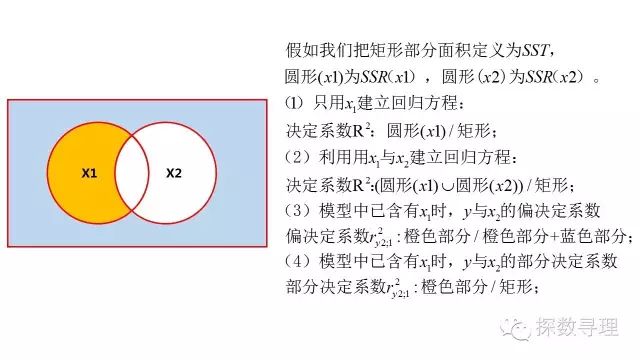
我们在前面介绍简单相关系数与复相关系数,但问题又来了,简单相关系数只能探究两个变量之间的关系,而复相关系数探究得则是整体自变量与因变量之间的关系,那我们能不能在一个多元回归方程中,在排除其他自变量影响的情况下,研究某一自变量x(i)与因变量的相关关系?这个指标就是偏决定系数与偏相关系数;
举例来说,假如我们需要研究价格(x1),收入(x2)与需求(y)的关系。
按照我们的理解,价格越高(x1),需求就越低(y),因此它们应该是负相关关系;但由于我们还有收入(x2)这一变量,从日常生活的角度来看,一般收入(x2)增加的情况下,商品价格(x1)也会随之提高,但收入(x2)增加同时也会带来需求的增加(y),因此如果从这一角度来看,单纯研究价格(x1)与需求(y)的关系的话,很可能就会得出正相关关系,正因为与此,我们提出了偏决定系数与偏相关系数。

5.部分决定系数与部分相关系数
在二元回归分析中,从偏决定系数的公式我们可以知道它是等于新加入变量(x2)后所带来残差平方和减少量(SSE(x1)-SSE(x1,x2))与原有残差平方和SSE(x1)的比值,那么进一步拓展,我们也能够求得加入这个新变量(x2)后所带来的残差平和减少量与总平方和的比值,这个比值我们定义为部分决定系数。

为了方便对比关系,一个不严谨的说明示意图如下:
二、动手案例

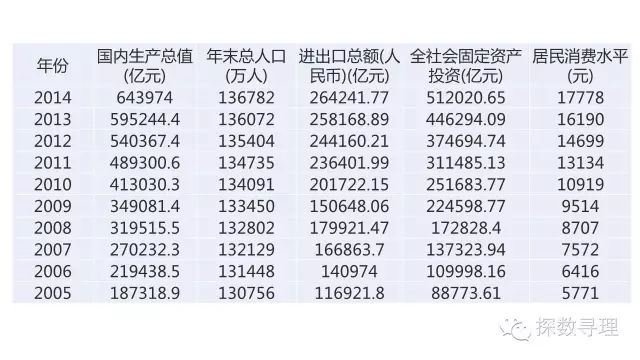
该数据样例是我国1995年-2014年国内生产总值相关数据,具体字段见下图
链接: https://pan.baidu.com/s/1nvauRaT
密码: e9kk
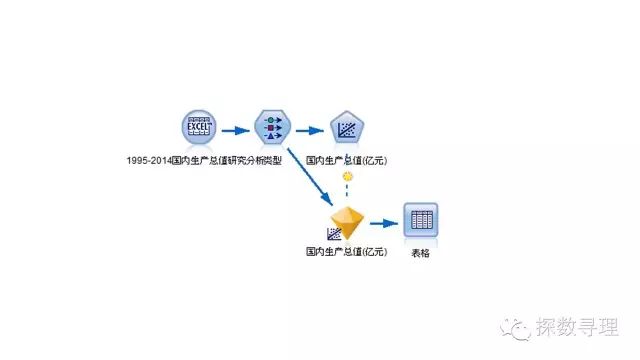
模型流如下所示:
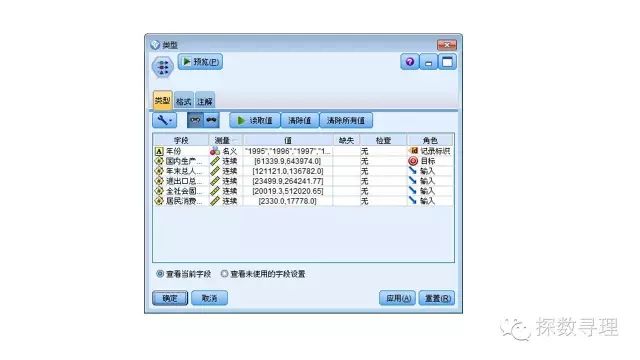
类型节点中:
(1)把年份设为记录表示,表示该属性只作为标识用而不参与建模;
(2)把国内生产总值设为目标;
(3)剩下的年末总人口,进出口总额,全社会固定投资总额,居民消费水平设为输入;
上述介绍的内容在Modeler中主要都在回归节点实现,因此我们在下方建模选项板中,选中回归节点,并把回归节点添加到流。
在回归节点中,模型选项卡下,我们选择步进法建立回归模型
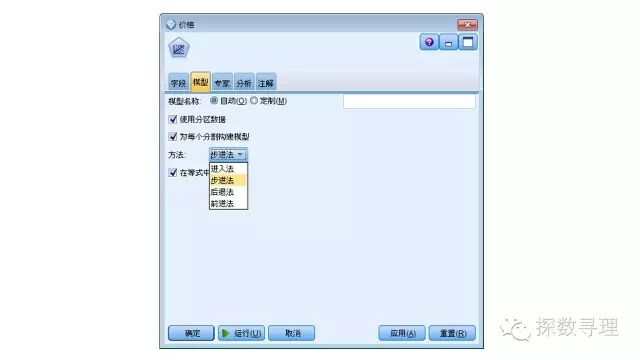
在‘专家’选项卡下,模式选择‘专家’。点击‘输出’,在弹出的‘输出’面板中,分别勾选:模型拟合度,回归系数,描述性,部分相关和偏相关性。确认后,选择运行模型。
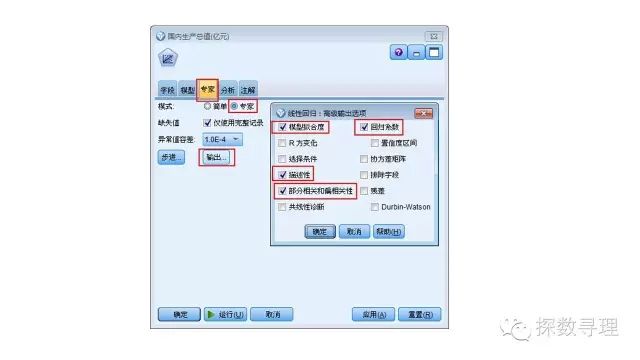
模型运行后,点开模型结果,选择‘高级’选项卡
高级选项卡第一部分内容就描述性统计分析:
(1)第一部分输出的是:简单统计,包括各变量均值,标准差,数量;
(2)第二部分输出的是:相关性分析结果,相关性分析结果分为三层。主要以相关矩阵的形式展示,第一层就是各个变量之间的相关系数,例如我们看到第一行第二列数字为0.944,表示年末总人口与进出口总额的相关系数为0.944;第二层则是对应每个相关系数的显著性检验结果,从显著性检验来看,所有的相关系数都十分的显著;最后第三层则是对应的数量;
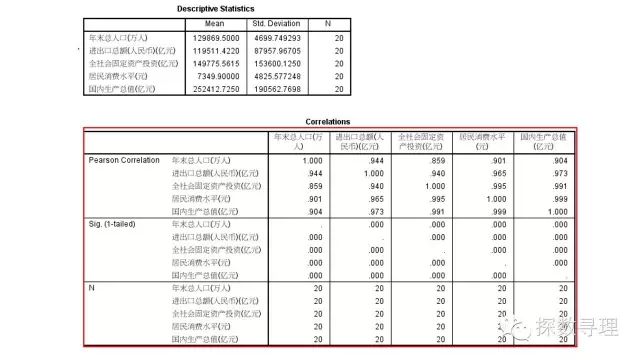
接下来时是模型构建过程及模型总结
(1)模型构建过程告诉我们,一共经历了2步构建出最终模型,按顺序分别引入了居民消费水平,以及进出口总额(年末总人口,全社会固定投资总额则未被引入模型);
(2)模型总结主要提供了复相关系数,决定系数,调整决定系数。直接看到最终模型结果,模型复相关系数为0.999,模型决定系数为0.999,模型调整决定系数为0.998,因此可以看到国内生产总值和我们的自变量间存在着很强的线性相关关系;
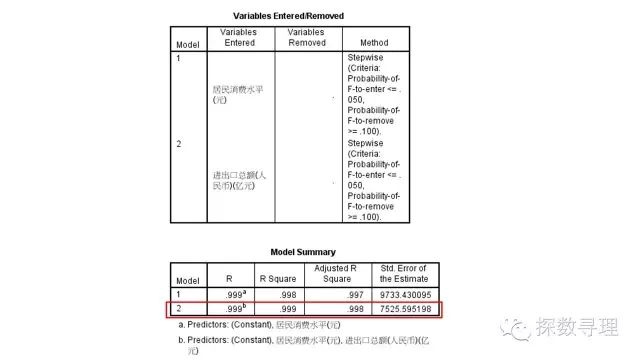
在接下来时F检验结果,可以看到最终模型的F统计量为6082.913,对应P值<0.05,因此,我们认为回归方程整体显著。
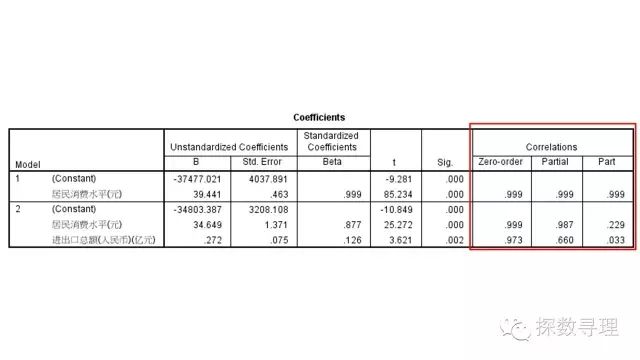
最后则是系数检验结果。
首先根据结果,我们可以写出最终的回归方程:
国内生产总值=-34803.387+34.649*居民消费水平+0.272*进出口总额
同时,我们可以看到各个系数都通过了显著性检验。
最后相关性结果,依次分别是相关系数,偏相关系数,部分相关系数;
因此我们知道居民消费水平与国内生产总值的相关系数为0.999,在剔除进出口总额变量影响的情况下,居民消费水平的偏相关系数为0.987,部分相关系数为0.229(对应的偏决定系数以及部分相关系数只需要求平方即可)


公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享