KDD 2020 | 如何自动为淘宝买家秀视频起上欲罢不能的短标题


要说这两年最火的用户产品是什么,直播和短视频必须拥有姓名。抖音、快手火到飞起,而电商大佬阿里、社交大佬腾讯因为没有早布局,现在也得放下身段苦苦追赶。在神奇的2020年,小伙伴们一定发现了,微信大面积上了视频号,淘宝首页也开始有越来越多的视频。


在自身业务之上加入新的血液是件不简单的事情,这是两个基因的融合,有可能产生新物种,也有可能本身存在生殖隔离。直到现在,各家仍在摸索各自的融合之道。比如在抖音视频里加橱窗,和在淘宝商品中加视频,虽然都是视频+卖货的形式,但功能定位和引导设计是完全不同的思路和解法。

说到这,你以为本公众号要沦陷为一个画饼号了么?错!今天我们仍要看一篇技术文章,不过会更多从业务视角来看待这个问题——为买家秀视频生成短标题。这是阿里巴巴KDD 2020的一篇文章[1]。咦,这不是做了很多年的视频描述问题么?敲黑板,我们说的是买家秀,大家知道买家秀是什么概念么?
其实,我们并不缺少优质的买家视频,而且买家秀视频数量巨大、个性化强,如果能推荐给潜在感兴趣的消费者,对于推荐的业务是相当友好的。在淘宝的场景,买家秀视频往往需要一个引导性的、高质量的视频标题。这个标题要求精炼,让用户在观看视频前就能对视频有一个初步的把握,从而抓住主线,产生观看兴趣。
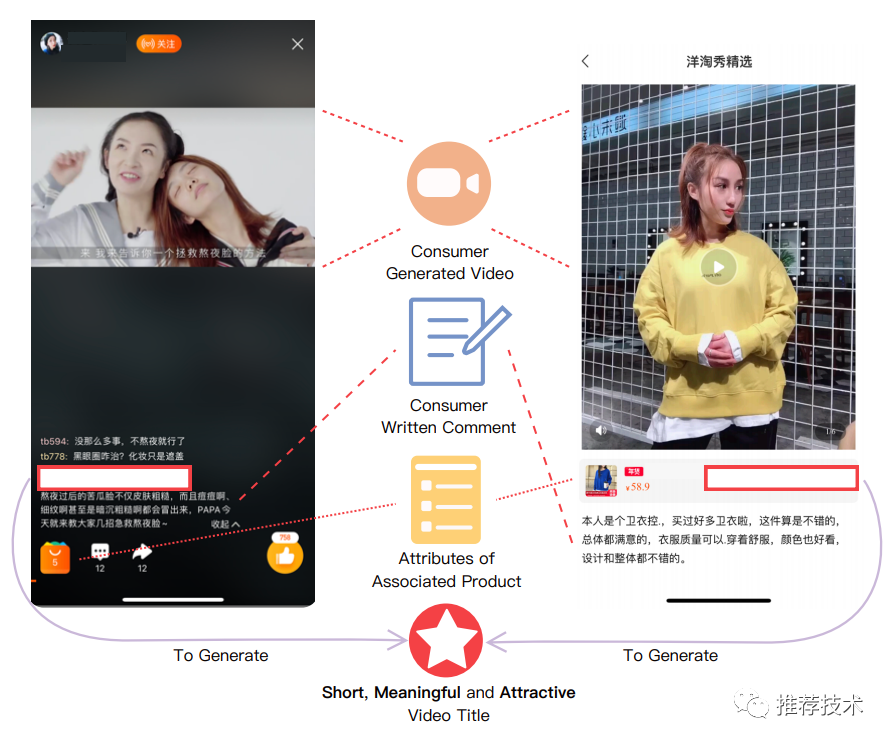
虽然买家在上传视频的过程中,也会提交描述性的评论,但这些评论往往会比较主观,且含有大量的物流、客服服务等和商品本身无关的购物体验,是不适合放在标题的。于是在本文中,作者会从三个渠道来抽取主要信息:视频、买家评论、商品属性。

每个买家秀视频都会与一个特定的商品关联,而每个商品也都有属性信息,属性信息一般都是准确的。文中从淘宝的日志中获取了9w的数据集,大公司的豪气又一次显露无疑。

和传统视频描述不同的是,买家秀视频标题生成需要更注重商品细节描述、外观识别描述、背景交互、故事线主题等等元素,其任务本身是和实际应用强关联的。传统视频描述通常会用RNN来建模视频帧序列和文本序列。但是在本文,如果要给商品不同部位之间建立关联、建模商品整体的特点、同时融合三种异构信息(视频、买家评论、商品属性),一个小小的RNN就捉襟见肘了。

好,扯了这么多,正文开启。本文提出了一个新的建模框架,名为基于图结构建模的视频标题生成器(Graph based Video Title Generator, Gavotte)。Gavotte由两个子过程构成,即细粒度交互建模和故事线摘要建模。细粒度交互建模将三种输入表示成图结构,并利用全局-局部聚合模块探索细粒度信息在图内和图间的交互作用。故事线摘要建模利用了帧级别信息,依然用RNN建模序列依赖,以识别故事线主题。
看到这你是否一头雾水?别说,小编也头秃了。然而,下面这张图才是真正的瑟瑟发抖大杀器,硬生生闪瞎了我的24K钛合金狗眼:
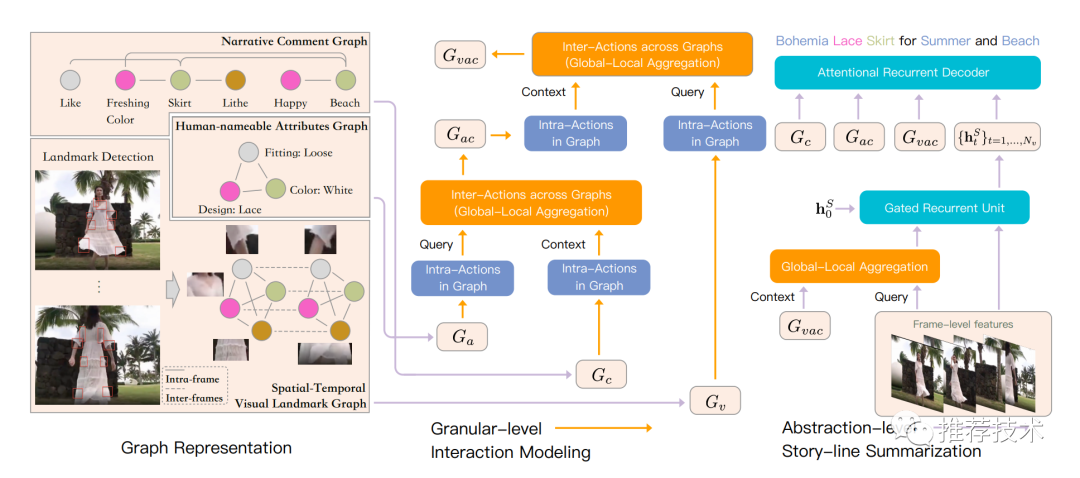
这张图的信息量也太大了吧!无奈基于我的职(hun)业(kou)操(fan)守(chi),还得硬着头皮看啊。神奇的是,当我怀着这样一份视死如归的心情,突然问题就迎刃而解了。我从中总结了一个诀窍,一般人我不告诉他:看这种框架图,你就当是搭积木,哦不,是玩乐高(高级)。


乐高一:图结构
这里有三个图结构,分别对应三种输入:视频、用户评论、商品属性。商品属性最简单,就是把每一个属性值作为图节点,对所有节点进行全连接。评论信息,是把每个词作为图节点,将有语法关系的节点进行连接,而不是根据词的时序关系,这样的好处是可以捕捉到评论中和商品有关的短语。重点说下视频。
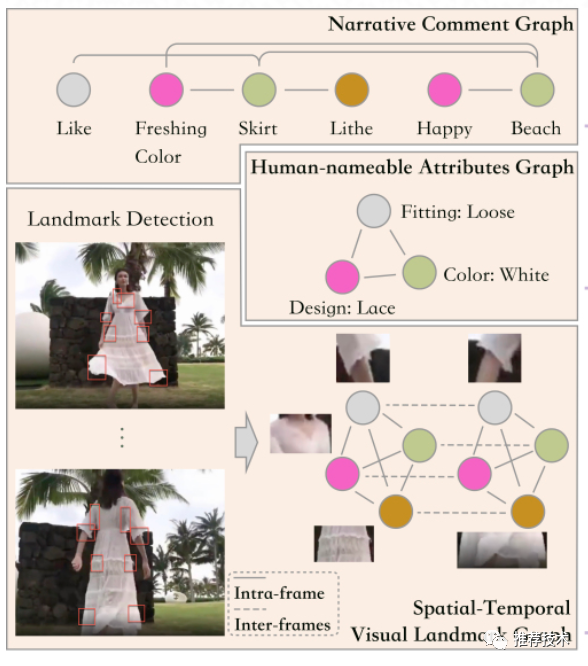
文中用了另一篇文章里检测衣服类商品部位特征的方法(Landmark Detection技术),每一帧的每一个部位都是图节点,在上图用红色框框标出。同帧的部位节点全连接,不同帧的相同部位节点全连接,前者有利于捕捉同一帧里商品部位间的交互,后者有利于捕捉同一个商品部位随着时间线的动态变化。
乐高二:细粒度交互
在上述三个图的基础上,建立图内关系和图间关系。
图内关系建模是为了对商品有关的细粒度特征进行识别,图间关系建模是为了对异构图之间的细粒度特征进行关联和聚合。具体地,图间关系建模使用了全局-局部聚合模块GLA,它包含全局门控访问和局部注意两个子模块。
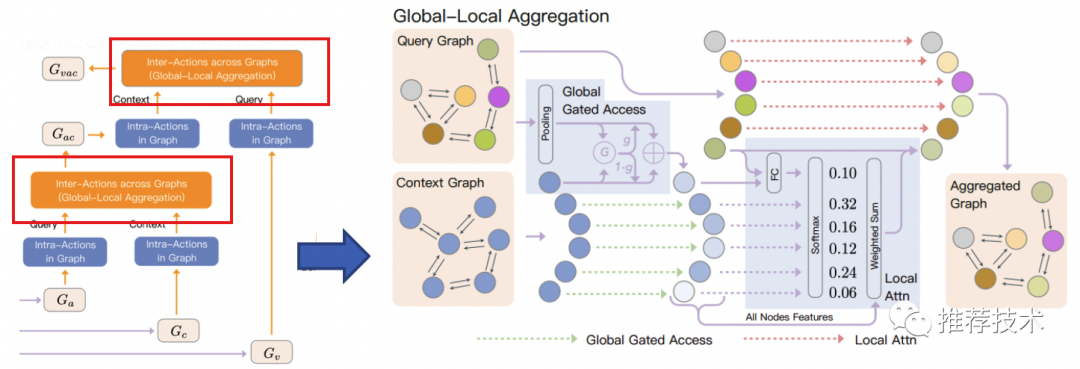
注意,GLA的输入包含两个图,Query Graph(查询图)和Context Graph(上下文图),最后的输出Aggregated Graph(聚合图)是和Query Graph一致的。
两个子模块分别干什么?全局门控是加强上下文图中与查询图相关的信息、抑制无关信息;局部注意力把上下文图中和查询图相关的内容进行聚合,最后输出是一个attention的加权。这部分说的很绕口,小编认为,核心还是在做注意力机制,利用其它图的信息(上下文信息)聚焦到自身的关键信息。
在细粒度交互中,GLA模块是用了两次的,对于三种输入,每次融合一种。注意看查询图和上下文图的构造,还是比较符合直觉的。
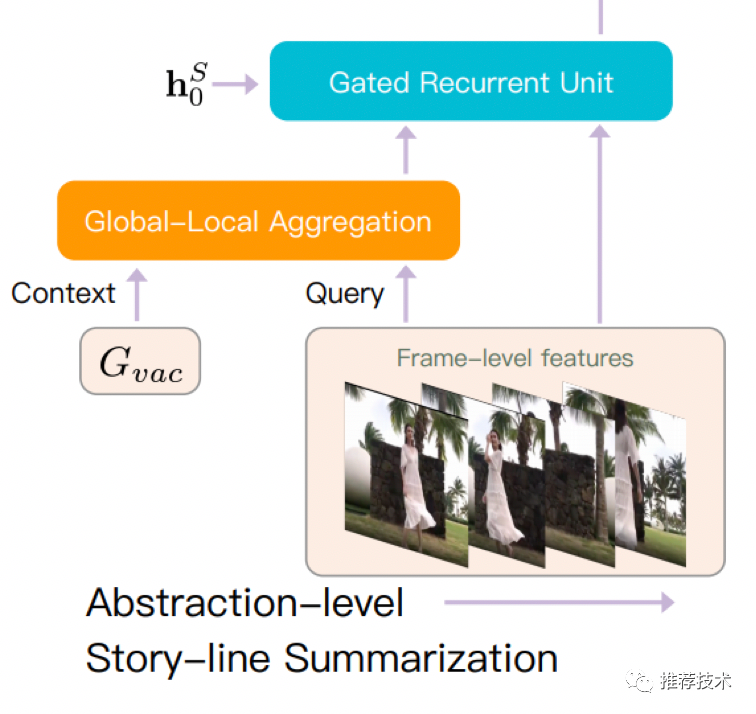
乐高三:故事线摘要模块
故事线是用RNN来串接的,不过这里除了帧信息外,还融合了上面步骤产出的GLA输出(细粒度信息),作为上下文信息。
乐高四:解码器
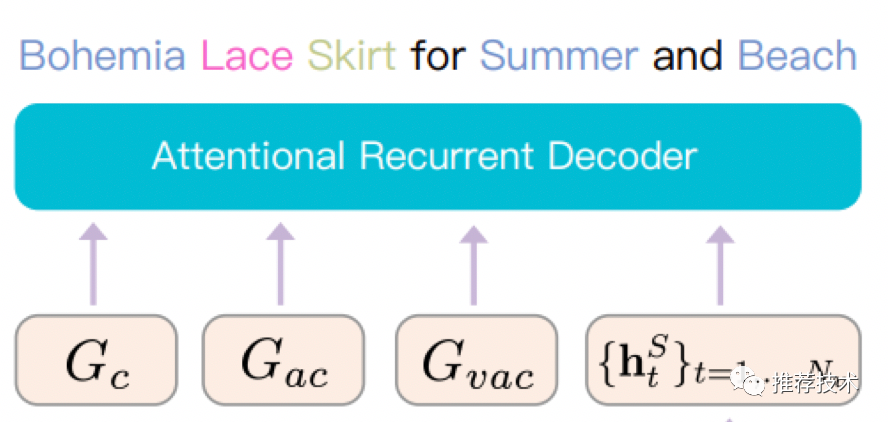
很简单,就是一个RNN结构。
我们用玩乐高的方式,把一张大的模块图拆成了四小块,每块各司其职,中途没有一个公式,完全看模块连接的原理,这样是否清晰?

最后简单放一下该模型的案例,大家看看效果如何:

这是一篇强业务相关的技术文章,融合了多种模态的处理方式,问题明确,解决方式直观。但由于其复杂性,不可避免地会让后来者难以复现。随着各项技术的发展,或许我们会看到越来越多这种工业界的文章,为了解决一个综合性的问题不得不搭积木,各个模块就如格子间的我们一样,是庞大系统中的小小螺丝钉。它们不同于CNN或者Transformer这样天才的想法,不是各自领域一块地基,能够养育众多的业务,但在自己的业务场景,也可以独自美丽。
参考文献
1. Comprehensive Information Integration Modeling Framework for Video Titling,https://arxiv.org/abs/2006.13608
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



