我们为什么在 Databricks 和 Snowflake 间选型前者?

DeNexus 致力于解决威胁全球关键基础设施的网络安全风险,并为承保这些设施的保险公司提供服务。
关键基础设施并不仅限于机场、电力设施和能源供给等中心,还包括由复杂运营技术 (OT) 构成的生态,以及 IT 网络、工业控制系统(ICS)、企业软件和人员等。
需要关注的是,关键基础设施正面对着愈发严重的网络安全风险。在过去五年中,能源、可再生能源、制造、运输、供应链生态系统等都已成为不断增长的勒索软件和恶意软件攻击的受害者。仅在近两年中,针对 ICS 和 OT 的勒索软件攻击就增长了五倍以上。解决网络安全风险挑战的代价高昂,因为其呈现出的巨量数据将会吞噬所投入的大量资金。
针对此,DeNexus 推出了支撑数据的采集、存储和使用的专有数据湖“DeNexus 知识中心”(DeNexus Knowledge Center),为 DeNexus 自研风险量化算法的开发和训练提供数据服务,进而形成了供 DeRISK 使用的产品。DeRISK 是 DeNexus 推出的一款安全、高效、灵活并高度可扩展的风险量化 SaaS 平台
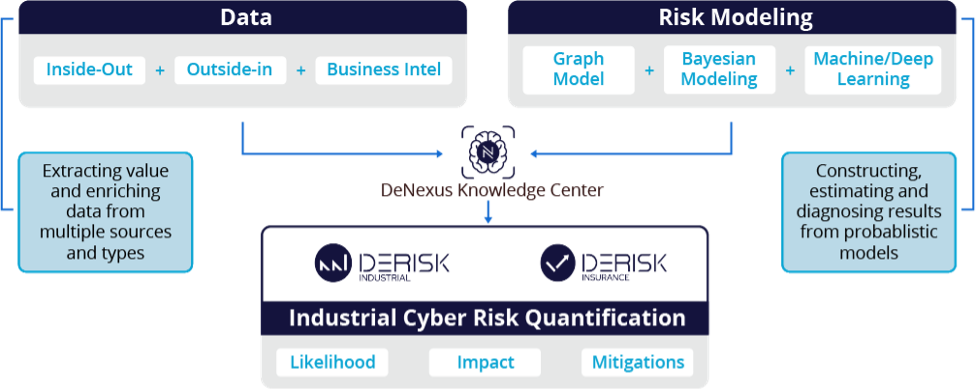
图 1 DeNexus 知识中心(DeNexus Knowledge Center)结构图
支持不同类型用户的数据访问需求:包括执行复杂数据转换的高级用户,以及仅是使用 SQL 的基础用户。
强大的数据版本控制功能:确保特定文件和表的版本不会在高级建模中发生更改,能记录数据湖中所有的历史交易,可轻松访问和使用历史版本数据。
支持异构数据:为 DeRISK 的输入输出和各种格式的商业智能数据提供支撑,包括结构化的、半结构化的和非结构化数据。
高可扩展性:考虑业务的快速增长,设计上需满足 PB 级数据存储。参见在线视频“面向无穷:够大并非总是够好”。
委托架构:为优化内部人力资源配置,解决方案应尽可能考虑采用 SaaS 或 PaaS。
机器学习模型运营化(MLOps):该数据湖的一个主要用例,是通过模型应用使用数据。数据平台的用户主要是企业中的数据科学家。为推进开发并加速上线部署,最佳实践需参考 MLOps 范例。
强安全性和合规性约束:数据存储需具备很好的灵活性和动态性。
DeNexus 在评估了市场上现有的解决方案后,摈弃了基于 数据仓库理念 的解决方案。因为面对以 Parquet 或 Avro 格式提供的数据,以及 Spark 或 Presto/Trino 等工具,是否依然需要去区分数据湖和数据仓库,这取决于具体的用例。对于 DeNexus 而言,是完全没有必要的。因为 DeNexus 的数据平台事实上是全新构建的,数据主要并非来自 SQL Server、PostgreSQL、MySQL 等 关系数据库管理系统,从一开始就不存在任何需要做迁移的数据源。
近数据仓库之父 Bill Inmon 最也阐述了类似的观点:
“一开始,我们会把所有的数据都扔到一个大坑中,称其为“数据湖”。但我们很快就会发现,仅仅将数据扔进坑里是毫无意义的操作。为使数据有用,即加以分析,数据需要相互关联,并为最终用户提供良好设计的数据分析基础设施。除非这两个条件得到满足,否则数据湖就会变成一片沼泽,并在一段时间后开始散发臭味。不符合分析标准的数据湖,就是浪费时间和金钱。”
-- Bill Inmon,“构建湖仓一体”
数据仓库的主要优点在于 ACID、版本管理和优化等,而数据湖的主要优点是存储代价低、支持异构数据格式等。DeNexus 的数据管理系统考虑结合二者的优点,因此需要的是 仓湖一体平台。DeNexus 选择了 Databricks 产品,一方面考虑其提供了仓湖一体的原生实现,其它方面考虑因素将在下面做展开介绍。
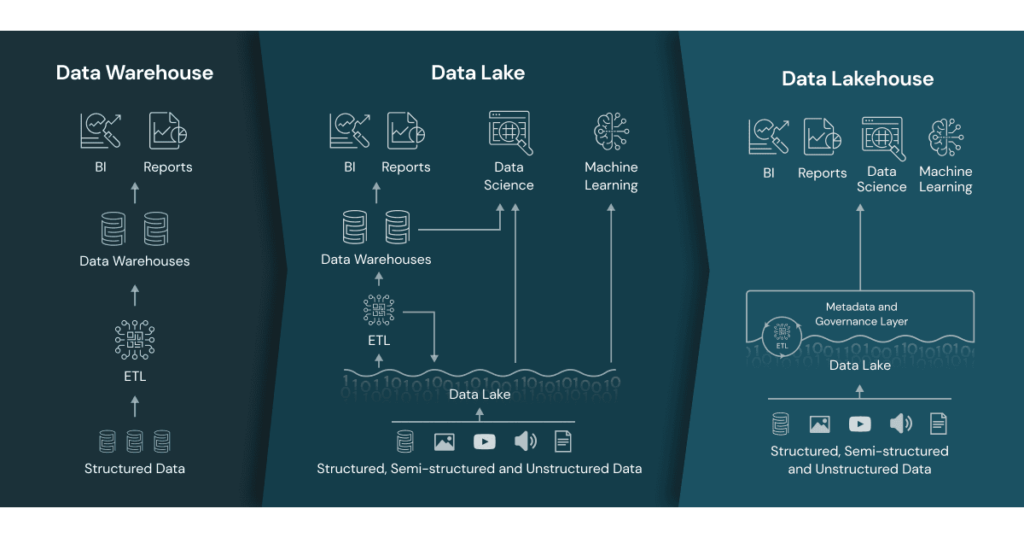
图 2 数据仓库、数据湖和仓湖一体的对比
机器学习算法并不能很好地适配数据仓库,因为 BI 查询通常仅抽取少量的数据,但 XGBoost, Pytorch, TensorFlow 等实现的机器学习算法需在不使用 SQL 的情况下处理大量数据集。此外,使用 JCBD/ODBC 连接器时会做多次数据类型转换,导致数据读取效率很低,而且一般不能直接兼容数据仓库所使用的内部专有数据格式。另一种做法是将数据以开放数据格式导出为文件,但这增加了额外的 ETL 步骤,增加了复杂性,也不合时宜。
尽管 Snowflake 这类“云原生”数据仓库支持以数据湖格式(开放数据格式)读取外部表,也实现了湖仓一体方法,但是:
Snowflake 数据的主要来源是自身的内部数据,存储成本更高。因此在一些情况下仍然需要 ETL 流水线,增加了额外的维护流程,并导致更多的可能故障点。
对数据湖中的数据,Snowflake 并未提供与其内部数据相同的管理功能,例如事务、索引等。
Snowflake 的 SQL 引擎的优化,主要针对其内部格式查询数据。
此外,正如前面提及的 Presto/Trino、AWS Athena 等数据湖查询工具,Snowflake 的单一用途工具并不能解决数据整体上的问题。这些工具缺乏正常数据仓库所具有的 ACID 交易、索引等基本数据管理特性。
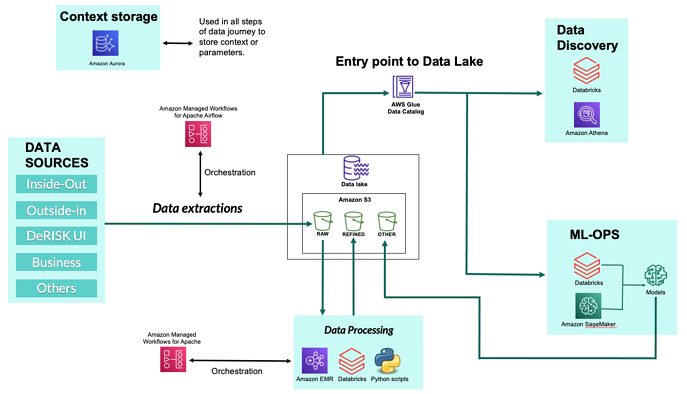
图 3 DeNexus 数据平台结构图
支持不同类型用户的数据访问:要使用 SQL 访问数据,必须有人去处理原始数据,并做结构化处理。那么是否能用基本的 SQL 语句完成数据转换?答案虽然是肯定的,但只能祝一切好运。
SQL 有其强大之处,但并非适用于一切。SQL 并非一种 通用编程语言,因此非常难以实现递归和循环,难以使用变量。鉴于我们无法整体把握实现 DeRISK 产品路线图所需执行的数据转换,因此多样性是一个重要的考虑因素。Databricks 产品支持执行 Spark、Python、Scala、Java 和 R 等语言,甚至支持 SQL,适用于不同类型的用户。完美!
强大的数据版本控制:Databricks 原生支持 DELTA 格式。Delta Lake 是完全兼容 ACID 的,这就解决了 Spark 的 不兼容 ACID 这一主要问题。此外,Delta Lake 支持在流水线出现错误时恢复系统,并易于对数据提供确保,例如确保开发模型中所使用的数据不变(参见 Delta Lake 文档:“数据版本管理”https://docs.delta.io/latest/quick-start.html#read-older-versions-of-data-using-time-travel)。此外,Delta Lake 是完全开源的。
Spark 等 Databricks 产品支持处理各种的类型数据,结构化的、半结构化的,以及非结构化的。
此外,Spark 并不使用特定的数据格式。鉴于 Spark 是完全开源的,我们可以手工开发连接器,或是使用 Python、Scala、R 和 Java 等语言的原生软件库。毕竟,Databricks 不仅托管了 Spark 一款产品。
卓越技术:除非看到类似 Google、Netflix、Uber 和 Facebook 这样的技术领导者从开源系统转向了专有系统,否则尽可放心地使用 Databricks 这些从技术角度看十分卓越的开源系统。开源系统更具多样性。(https://www.datagrom.com/data-science-machine-learning-ai-blog/snowflake-vs-databricks)
Databricks PaaS 本质上是可扩展的,数据平台可使用所有的云资源。例如,使用 S3 可满足更大的存储需求,以及一些新环境中的一次性存储需求;Databricks 可直接满足对更多处理能力的需求,极大节约了企业最具价值资源即软件工程人员的时间;一旦新的数据科学家加入团队,不再需要在本地配置个人计算机;用户可在任何时候细粒度控制在运行的机器数量,及各台机器所具备的功能,同时避免出现意外计费的情况!
此外,Spark DBR(即 Databricks 的商业版 Spark)比常规 Spark 的性能更快,但需要为 Databricks Runtimes 额外付费。这是物有所值的。
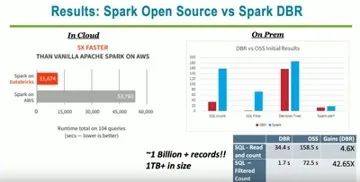
图 4 Spark 开源版与 DBR 版的性能对比(来自 YouTube)
基于 Databricks+ 托管 MLflow,实现 MLOps 完整解决方案。MLflow 提供了模型开发的环境,以及机器学习全生命周期的平台。MLflow 最初是由 Databricks 创建,之后捐献给 Linux 基金会。参见 GitHub:mlflow/mlflow:机器学习生命周期的开源平台
MLflow 支持数据科学家轻松追踪实验中使用的数据表版本,并在后期重现指定版本的数据。此外,MLflow 为数据科学家提供了协作环境,支持同事间相互共享模型和代码。MLflow 可与 Azure-ML 和 AWS SageMaker 等机器学习平台联合使用。在 Databricks 托管 MLflow 中注册的模型,可以轻松地用于 Azure ML 和 AWS SageMaker 中。
此外,使用 Databricks 托管的 MLflow,数据科学家可基于 Spark ML 和 Koalas(即 Spark 中实现的 Pandas)轻松实现算法并行化。
数据存储层和处理层的完全解耦。Databricks 实现了计算和存储的分离,可处理在任何位置、以任何格式存储的数据。不需要任何专用的格式或工具,因此数据迁移具有高度的灵活性。
图 5 显示了数据的三个阶段,以及每个阶段所使用的工具:
数据处理:Databricks、Python+AWS Lambda、EC2。
数据发现:Databricks、AWS Athena。
MLOps:Databricks、AWS SageMaker。
各阶段的共同点是,都使用了 Databricks 产品。
过程中不存在任何的供应商锁定,除了使用 AWS Glue 数据目录实现外部元数据存储。按使用付费的模式,支持用户根据特定场景选型替代服务。尽管这类场景目前我们尚未遇见,但不排除未来可能遇上。
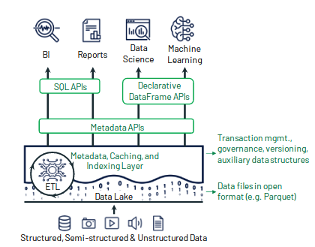
图 5 整合所有服务的数据平台(译者注:图片来自 CIDR 2021 论文“Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics” )
http://cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf。
如果希望良好的架构和数据模型能解决数据一致性、治理和架构实施上的大部分问题……并且希望能在这些数据上获得更多的功能和灵活性……那么请选型 Databricks 产品……几乎没有 Spark 和 Delta Lake 做不到的事情。
作者简介:
Iván Gómez Arnedo 是一位具有丰富经验的数据工程师,致力于解决架构和可扩展性等具有挑战性问题,以及构建数据密集型应用,取得了良好的业绩。在加入 DeNexus 之前,Iván 曾在 BASF 银行和 Santander 银行参与多项关键数据项目。
原文链接:
https://blog.denexus.io/databricks
Nginx之父突然离职,程序员巅峰一代落幕
微软壕掷 687 亿美元买动视暴“乱”:你激动个啥?
《中国卓越技术团队访谈录》是 InfoQ 打造的重磅内容产品,为了能进一步了解读者的实际需求和喜好,持续为大家生产有价值、具备启发性的内容,我们发起了本次调查,真诚邀请广大社区读者参与问卷。同时,如果你希望 InfoQ 关注并采访你所在的技术团队,也可以通过本问卷报名,报名选项在问卷底部。
点击【阅读原文】,即刻参与有奖问卷调查,还有机会获得精美礼品。
如对本次调研有任何疑问或建议,欢迎联系微信 13512772438。

点个在看少个 bug 👇


