Pre-training到底有没有用?何恺明等人新作:Rethinking ImageNet Pre-training
【导读】使用基于ImageNet预训练(Pre-training)的网络已成为计算机视觉任务中一种常规的操作。何恺明等人在新作Rethinking ImageNet Pre-training中使用详细的对比实验和分析提出了对基于ImageNet预训练的新的思考。研究发现,对于在COCO数据集上的目标检测和实例分割任务,使用随机初始化的参数会收敛的更慢,但最终所达到的结果不比使用在ImageNet上预训练的参数差。
预训练
预训练模型一般指在大规模数据集上对特定任务训练的深度模型。对大多数人来说,预训练模型的训练一般很难进行,因为它需要消耗大量的计算资源。在ImageNet预训练的卷积网络是最常见的预训练模型之一,它包含1400万张图像(大约1000类,每一类约120万张图像),大约100万张图像包含Bounding Box标注信息。
当特定任务训练完成后,学习到的参数即为预训练模型。很多预训练模型都可以从Github中找到,当然最简单的方法还是直接使用各个深度学习框架(如TensorFlow、Keras)内置的库来调用预训练模型。
消去实验
论文《Rethinking ImageNet Pre-training》建立在基于COCO数据集的消去实验上。在基于COCO数据集的目标检测和实例分割任务上,对比使用基于ImageNet预训练参数和随机初始化参数(即消去ImageNet预训练)的结果,对基于ImageNet的预训练所能带来的影响进行了分析。
有趣的统计
在论文中有一项有趣的统计,如下图所示。统计包含了在训练过程中,模型见到图像、示例和像素的次数。其中淡蓝色表示在ImageNet预训练时的统计数据,深蓝色代表在COCO上进行微调(Fine-Tuning)时的统计数据,紫色代表如果使用随机初始化从头训练的统计数据。
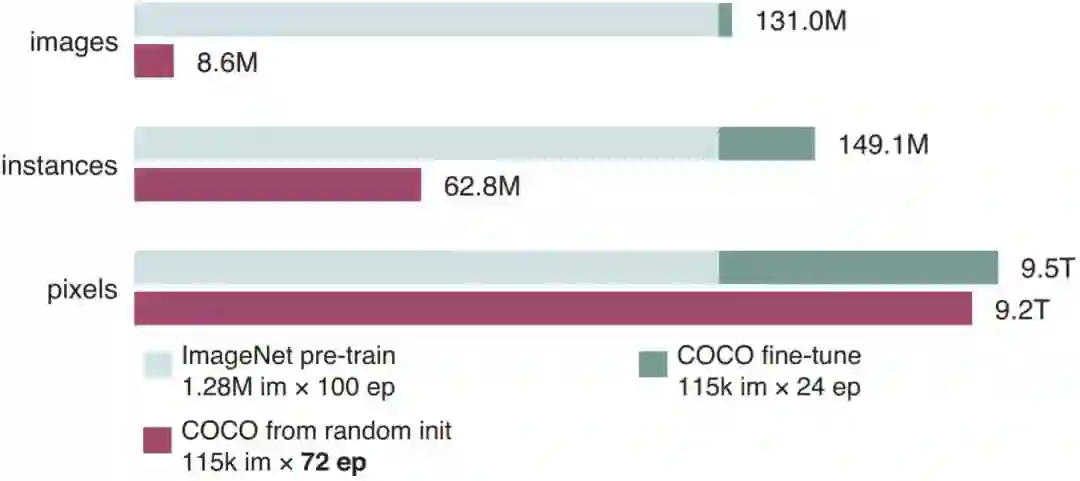
归一化
在目标检测任务中,由于输入的分辨率大且网络对显存消耗大,batch size只能被设置为比较小的值,这会损伤模型中Batch Normalization的效果。使用预训练模型可以绕过这个问题,因为我们可以在微调时将Batch Normalizaiton的参数固定。但是,如果使用随机初始化的参数从头训练则不能使用这个技巧。
在论文中,使用了两种较新的归一化方法来减轻小batch问题:
Group Normalization (GN): https://arxiv.org/abs/1803.08494
Synchronized Batch Normalization (SyncBN): https://arxiv.org/abs/1711.07240 https://arxiv.org/abs/1803.01534
引入Group Normalization或Synchronized Batch Normalization使得我们可以用随机初始化的参数从头开始训练模型。另外,利用appropriately normalized initialization(https://arxiv.org/abs/1502.01852),我们可以从头训练一个基于VGG的目标检测模型,且不需要使用Batch Normalization或者Group Normalization。
主要实验结果
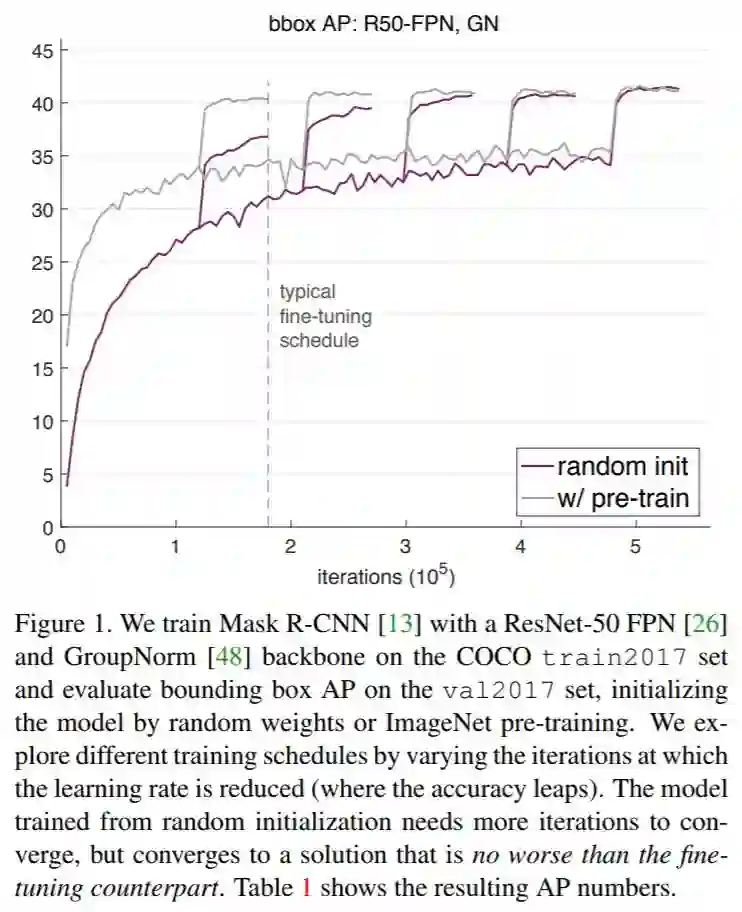
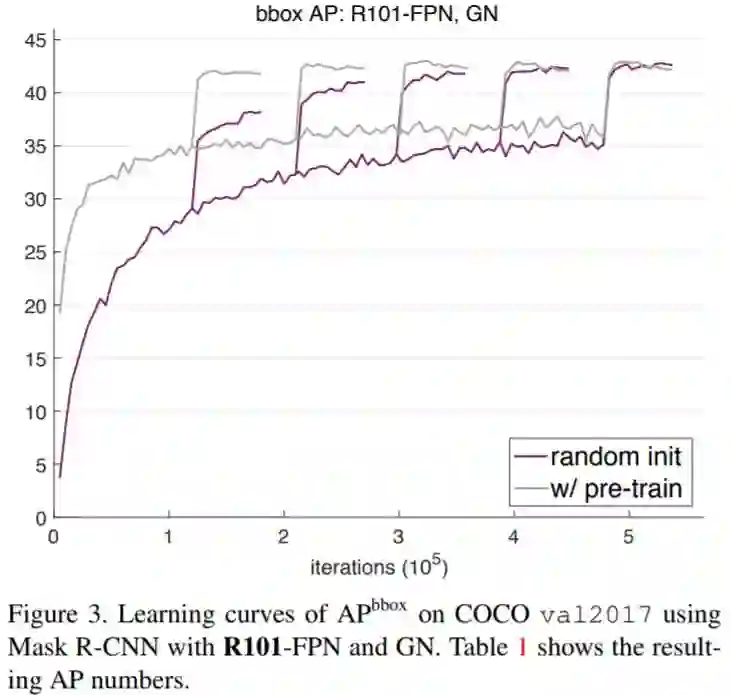
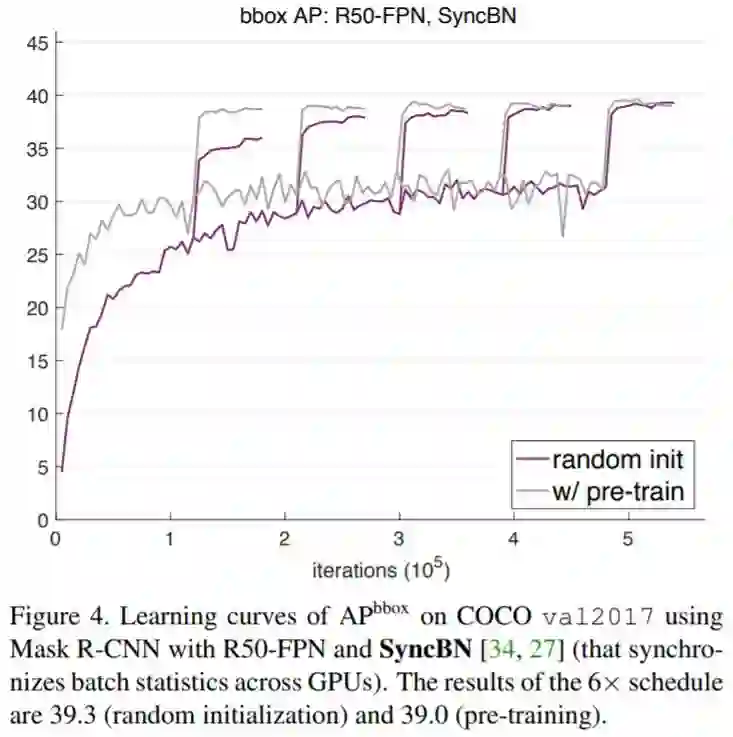
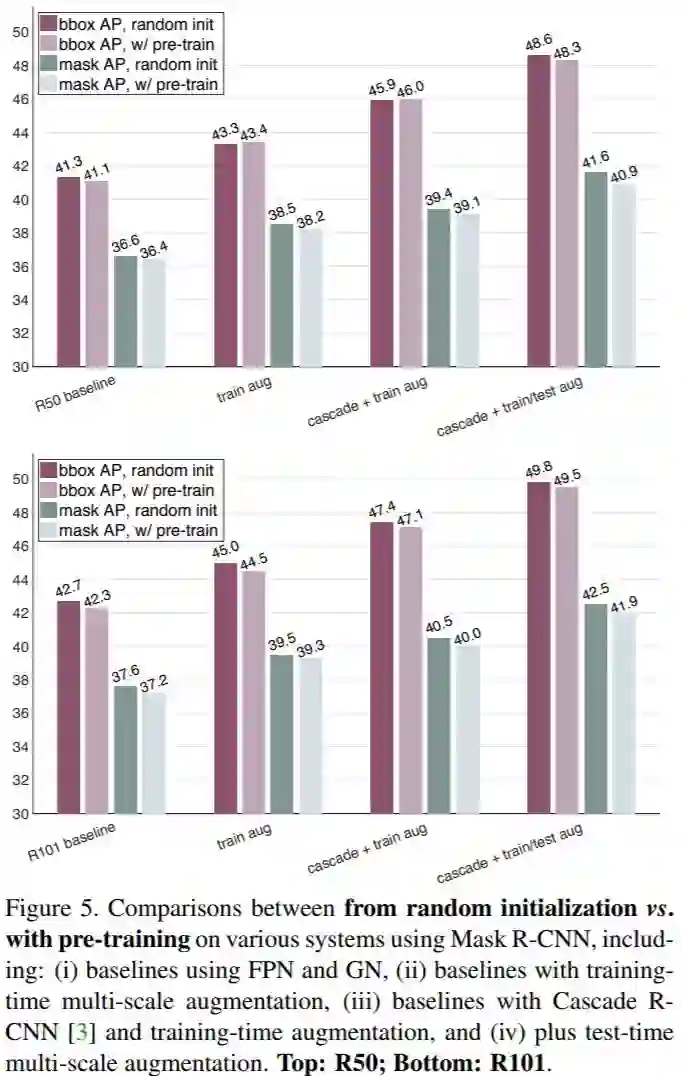
结论
使用ImageNet预训练模型可以加速收敛,尤其在训练的早期。但是基于随机初始化参数的模型会在一段时间后达到同样的效果,这个时间大约是ImageNet预训练和微调时间的总和。它需要去学低/中等级的特征(例如边缘、材质等),这些特征在预训练中已经学到。由于ImageNet预训练的时间往往在目标任务中被忽略,只考虑短时间的微调训练过程,基于随机初始化的训练的真正的表现往往被遮盖。
ImageNet预训练并不能自动提供更好的正则化。当用更少的图片训练时(COCO数据集的10%),我们发现必须从预训练参数中选择新的超参来防止过拟合。如果用随机初始化参数来进行训练,模型可以在不添加额外正则的情况下来达到同样的效果,甚至只用10%的COCO数据集。
如果目标任务/指标对局部空间信息比较敏感,ImageNet预训练并没有什么优势。当从头开始训练时,高重叠阈值部分的AP有显著的提升,另外,需要优质空间定位的keypoint AP会收敛的相对快一些。直观地说,基于分类的类ImageNet预训练和局部信息敏感的任务之间的鸿沟,会限制预训练的效果。
参考资料:
https://arxiv.org/abs/1811.08883
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




