浅谈湖仓一体化对上层机器学习业务的促进
最近湖仓一体化的概念在大数据圈子突然蹿红,知乎上很多大神已经分析了湖仓一体化主要的革新点,今天主要介绍下湖仓一体化对机器学习业务的影响。
还是简单讲下“湖”和“仓”的区别。
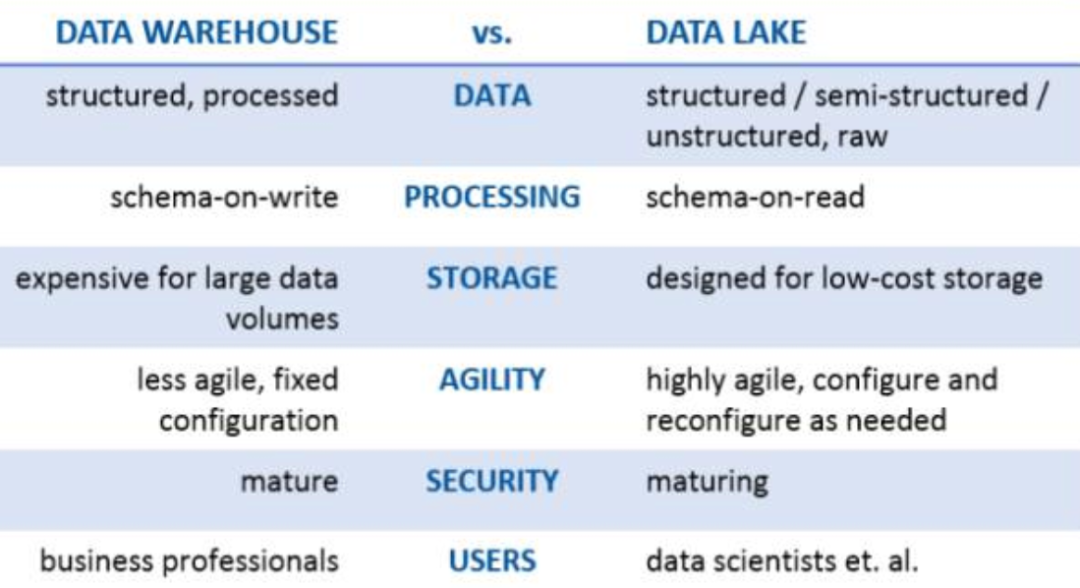
湖有点像一个开放的储物空间,可以存放结构化数据、非结构化数据、半结构化数据,存储成本很低,很灵活。仓更像是一个有无数小格子的储物间,所有数据需要按照要求放到小格子里。
湖的优势是很灵活,什么样的数据直接扔进去就好了,但是如果想查某个结构化数据,甚至做ETL工作,就会效果很差,因为所有数据都是随机摆放的。仓的优势是数据结构化做得很好,查数据很方便,但是构建一个个小格子,成本高,而且只能存放结构化数据。
在湖仓一体化之前,构建大数据体系需要在湖和仓直接二选一才行。Hadoop体系是标准的数据湖体系,Big query、MaxCompute都是数仓体系。
那么湖仓割裂的状态会带来什么问题呢?为什么今天大家开始讨论湖仓一体化了。以机器学习在推荐业务的应用为例说明。
以视频推荐的场景为例:
大家知道一个完整的推荐系统,需要做大量的用户行为日志分析以及待推荐对象的特征提取工作。行为日志分析是一个经典的数仓操作,需要对用户的历史数据做大量的结构化处理,并且通过ETL加工特征。
另外因为被推荐对象是视频,是典型的非结构化数据,需要做一些图像和语意相关的解析,这些操作是无法通过数仓完成的,需要借助数据湖来实现存储,再由算法脚本提取图像和文本特征。
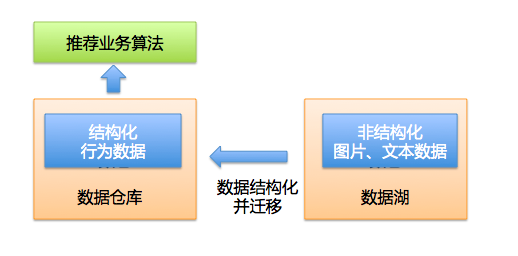
在仓和湖割裂的条件下,一个常见做法是将数据湖中的非结构化数据提取特征并结构化,然后将结构化的数据迁移到数仓体系内去做最终的特征向量拼接,并且训练推荐业务模型。在这种模式下,需要同时运维两种数据存储模式体系,并且需要做大量数据迁移工作,费时费力。
语音、文本、视觉相结合的解决方案在人工智能领域叫做多模态方案。在湖仓一体化的背景下,可以支持机器学习的数据以多种结构态存储并使用,所以我起了个名字,湖仓一体化可解决“数据多结构态”的问题。
在湖仓一体化的背景下,未来机器学习业务可以更多的去探索不同结构态数据间的建模打通工作。可以轻而易举的在一次模型训练中,即应用图像、语音、文本数据,也应用到数仓结果数据。这样无疑是对偏上层的机器学习业务的一种推动。
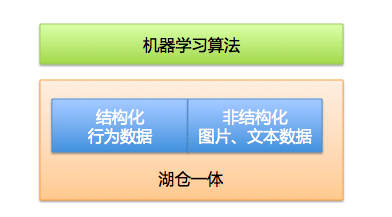
随着湖仓一体化的存储统一,K8S后续可能在调度层面的统一,可以预见的是机器学习业务后续会在整个计算存储的工程层面实现操作更简化。
具体关于湖仓一体化的发布会内容可以看以下链接,谢谢:
https://www.aliyun.com/activity/bigdata/2020yunqi


