3种方法,教你设计一个语音技能
关注并将「人人都是产品经理」设为星标
每天早 07 : 45 按时送达

在我们的日常生活中,语音技能其实无处不在。科技的不断发展使我们的生活变得越来越方便,很多时候通过说话便能让机器代替我们去做一些事情,这是语音技能给我们的生活带来的便捷之处。那么,如此便利的语音技能是如何设计出来呢?
全文共 3466 字,阅读需要 7 分钟
—————— BEGIN ——————
2016年,“互联网女皇”、KPCB合伙人玛丽·米克尔有过一个预判:“语音拐点已经到来,在2015年智能手机销量下滑之后,Echo销量或将腾飞。”而接下来的事实也验证女皇寓言的正确性。
在之后不久,国内智能音箱也迎来了爆发式增长,2018年国内智能音箱出货量突破2000万台,2019年国内出货量达到4589万台之多。
作为智能音箱,其核心就是语音能力,也就是要能和用户进行语音交互,而语音交互的核心是音箱能听到、听懂、理解、执行并反馈,而这其中到底能做哪些事就涉及到音箱上有多少个技能,此处的技能可以约等于APP上所说的功能。
接下来,我们一起探索下如何设计一个语音技能。

从发散到收敛
有时候要想说明白一件事情,最好的方式就是对比。
为了方便理解语音技能的特点,我们就拿APP的功能来对比,也就是语音交互和触控交互的对比。
首先我们先来看触屏操作,大家可以稍微回想下自己平时在APP上的触屏操作,几乎都是通过点击某些按键进行跳转,依次选择进入下一级或者原路返回,对吧?
所以概括来说,触屏操作是:
在有形状、有颜色、有文字、有震动等引导下的触觉交互;
触控交互是一个选择题,在多个可控区域中选择自己想要的,并点击;
触控交互无法选择开发者没有提供的选项;
大部分触控是怎么通过点击选择过来的,依然可以通过点击回去。
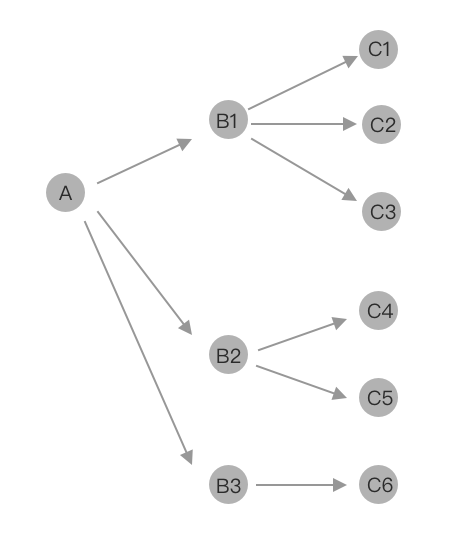
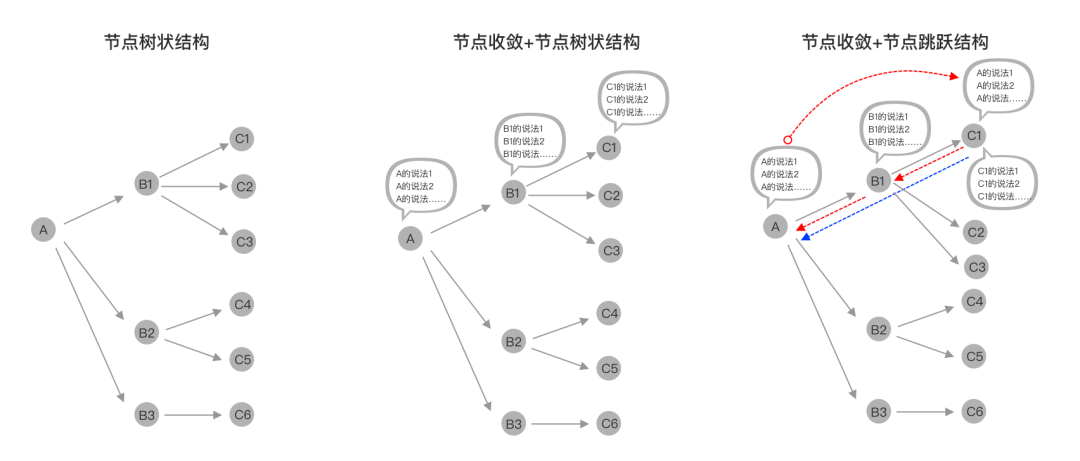
所以我们可以概括为触控交互是一个树状结构,从一个节点到另一个节点的可视化交互,如下图所示:
而语音交互却很不同。
首先,初期的智能音箱没有屏幕,甚至很多设备仅仅有一个很简单的闭麦指示灯,我们就拿查天气来举例子吧:
用户通过唤醒词来让设备处于聆听状态,准备接收用户的语音指令;
用户要查询当前位置的天气,可以怎么说?说天气行不行?当前的天气哪?现在的天气、最近的天气、今天天气怎么样、会下雨吗、有雾霾吗、出门需要带伞吗等等,就普通话而言就有很多种问法;
用户如果需要查询非当前位置天气哪?比如差旅目的地、家人所在地,需要怎么说?是时间+地点+天气,还是天气+时间+地点都可以?
我们看屏幕一次可以看7或者14天天气,语音要怎么实现?我继续询问说“下一天”吗?
在此种情况下,我们唤醒智能音箱后,用户的疑惑可概括为:
我什么时候可以说了?说早了,它有半句没听到,说晚了,它又闭麦了;
我们要说什么?每次只问个天气吗?是不是要说具体某天某地的天气;
怎么说是它能懂的?我用倒装句是否能行?我加个语气词哪?
这些都需要用户去摸索和学习,夸张点说的话,用户是闭着眼睛在操作设备。
此时我们再看语音交互时:
在没有形状、没有颜色、没有文字(会有部分上下文提示)、没有震动等引导下的交互;
语音交互可能是一个简答题,也可能是一个选择题,但是简答题占大多数;
语音交互可以选择开发者没有提供的选项,当然选择以后也是大概率是无法执行的。
所以我们可以概括为语音交互是一个单点呈收敛,多点成树状的结构,从很多发散的说法、话术收敛到某个意图、动作的节点,然后进入后续流程,如下图所示:
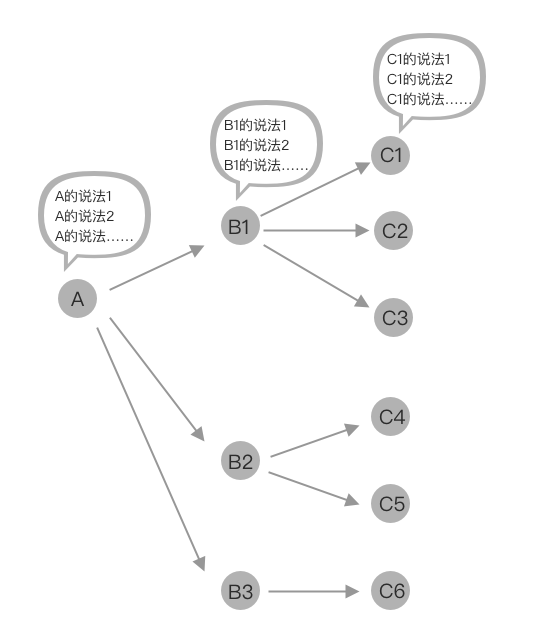
所以当我们做一个语音技能时,要先判断有哪些支持的能力,然后还要同时判断哪些不支持,而支持的能力有哪些种说法,这个部分如何收敛到有限个节点,而至于其他不能支持的,现在大部分都是走default状态回复:不好意思,没听懂。

从树状到圆环
在上面的分析中,我们说到过语音交互是一个单点要收敛、多点成树状的结构,但是语音技能中还存在网状、跳跃结构的可能性。
我们先来看APP上触控购物的例子:
筛选商品
加入购物车
收银台确认支付
支付成功
在其中任何一步,都可以点击返回去向上一步,比如当你准备支付时,女朋友说要再加个东西,你关闭收银台、反馈购物车,然后可以继续挑选商品,这是一个路径往复的轨迹。
但是当我们把购物做成一个语音技能,那么:
当语音询问用户是否要付钱时,用户是否可以说我还要买点别的?
如果用户可以说,那么是否直接去寻找商品,还是需要询问用户当前订单该如何处理?
如果用户说把已经在购物车的商品删掉,或者修改数量,或者修改收货地址,又该如何处理?
所以我们会发现,上述例子是不同节点间的跳跃、环形交互,也就是说一个节点的多种说法,在另一个节点是否允许生效的问题,而如果允许生效,则会出现环形。
但是语音中的环形流程并不友好,会有增加用户记忆负担、整个流程因为对话频次过多而显得冗长等问题,所以我们设计时还是尽量规避又长、又多的环形结构。
如下图所示,假设A为挑选商品,B1为购物车,C1为APP的收银台支付页面。灰色为APP的主线正向流程,红色弧线表示A的话术在C1生效,而当C1允许A的话术生效时,便会涉及到走两条红色的虚直线方案,还是走蓝色的虚直线方案。
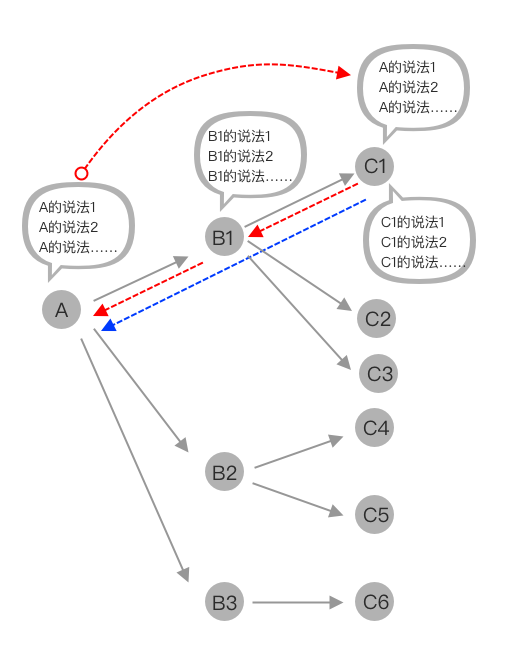
当然,我们可以限制某些节点的说法只能在某些意图范围内,比如如上截图,A的说法对C1生效,但是在C2~6全部不生效;如果用户在C2~6说了A的话术,我们可以统一回复并告知用户当前仅支持某些说法即可。
当然了,此时是可以退出整个流程,类似我们在APP中某个流程中,通过系统杀掉进程一样。

从独立到共生
刚才我们通过将触控与语音对比来阐述语音技能的从发散到收敛、从树形到圆环,那么下一个问题是:语音交互和触屏交互除了对比之外,是否可以融合?
答案是肯定的,现在市面上有很多带屏音箱(市场份额如下图),其中语音交互和触屏交互就已经开始融合,比如用户说我要看周星驰的电影,那么多部周星驰的经典电影,不能一个一个播报加询问啊。
所以需要让用户看电影海报后可以用语音来选择,这个不赘述(很多智能电视也已经支持)。
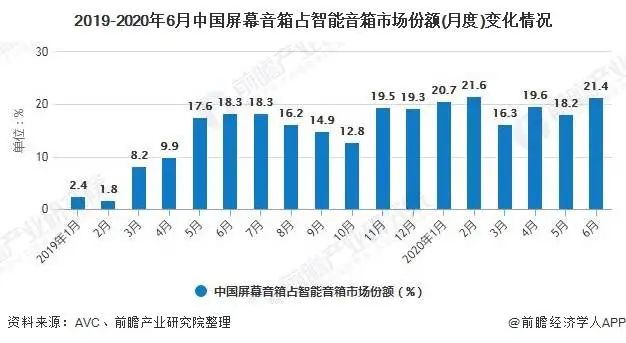
(图片来源:https://www.sohu.com/a/423616757_120868906)
那我们看上图会发现还是有很多无屏音箱,此时怎么和触控融合哪?那就是涉及到触控的不一定是音箱,可以是我们的手机APP。
首先,音箱的激活还是需要手机APP的,毕竟连接你家WiFi时用语音输入密码不是很方便。BD部分、四十部分的大有人在。所以我们可以考虑在手机APP上做一些更加符合触控交互的事情,比如刚说配网这类的设置。
这类在手机APP上的操作有共性可循:一些低频但是关键信息的输入,比如购物例子中涉及收货地址、电话号码、绑定支付信息,媒体娱乐的账号资产、会员充值等,这些的修改的频率都很低,同时还可让用户自己设定一些快捷指令。

脑洞示例
说了这么多,我们可以开下脑洞:
最近看到盲盒卖菜的新闻,感觉特别适合做一个语音技能。
我们先看如果在APP上做的主线步骤:
用户要先选择某个盲盒(可能有不同价位、荤素配比的差异)
选择后加入购物车
确认数量等属性信息(比如份数)
确认是否加购
拉起APP收银台选择支付方式
确定支付及支付结果展示
首先我们先看哪些步骤在语音交互中是可以被优化、调整的,例如(为阐述简单,示例会忽略很多实际数据和现实因素,比如运费):
我们将蔬菜盲盒减少为两种:纯素和荤素结合(当然也可以按照大小包不同量来分),一次来减少语音介绍及用户的记忆成本;
下单后不支持添加商品和修改数量,毕竟是买菜,配的盲盒就是一天一家三口的均码(请勿ETC自动抬杠);
收获地址需要用户在手机APP上提前设置;
支付方式需要用户在手机APP上提前设置,比如免密支付、声纹支付;
允许用户在APP上设置快捷指令,比如:“唤醒词+盲盒买菜大份”来对应荤素搭配的蔬菜盲盒、“唤醒词+我要吃盲盒”来对应蔬菜盲盒的纯素版。
通过以上调整,我们的用户可以通过一句话来完成盲盒买菜的主链路,其中标号和2主要是修改节点数量(减少)和节点间的关系(一层且线性),标号3、4、5主要是用手机APP来对低频关键信息设置,也是对节点数量的优化,同时也让节点关系更加简单。

总结
通过以上分析,当我们在做一个语音技能时:
可以先考虑如果它是个触屏技能,此时要有什么能力和节点链路;
哪些节点和链路是语音交互需要支持的、哪些不需要;
哪些最好是通过手机屏幕、音箱屏幕来完成的;
需要语音支持的节点中,每个节点的泛化说法有哪些;
哪些节点间是可以任意跳转并继续流程的,哪些节点是跳转需要询问的(因为此时跳转就是从新开始了),哪些节点是不能跳转的。
—————— / END / ——————

▼ 喜欢请分享&收藏,满意点个赞,最后点「在看」 ▼





