【SCIRLab】ACL20 基于图注意力网络的多粒度机器阅读理解文档建模
论文名称:Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension
论文作者:郑博,文灏洋,梁耀波,段楠,车万翔,姜大昕,周明,刘挺
原创作者:郑博
论文链接:
https://www.aclweb.org/anthology/2020.acl-main.599.pdf
代码链接:
https://github.com/DancingSoul/NQ_BERT-DM
来自:工大SCIR实验室
任务介绍

目前解决NQ任务的两类方法主要可以分为两大类,如图2所示,第一类是Pipeline方法,模型首先在长答案候选集合中选出长答案,然后再在选中的长答案内部抽取短答案;第二类是基于BERT的方法,模型直接在文档抽取短答案,然后直接在长答案候选集中选出包含短答案的长答案。
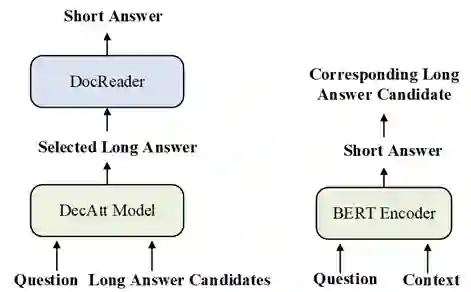
然而,以上两种方法都是将长短答案两个子任务独立考虑,而并没有想办法建模两个粒度答案之间的联系。由于长答案是文档中的段落,短答案是词片段,这里可以很自然将文档使用层次结构(文档级别->段落级别->句子级别->词级别)表示,并且用段落和词来建模两个粒度答案。由此,我们提出了基于图注意力网络和BERT的多粒度阅读理解框架,并且通过联合训练来建模两个粒度答案之间的联系。
数据处理
由于NQ中文档的长度很长,和其他基于BERT的阅读理解模型一样,我们首先将问题和文档都用Word Piece进行词切分,然后将文档切成多个片段进行处理。由于我们的做法基于BERT,所以忽略掉维基百科文章中的所有HTML标签,然后在每个长答案候选项之前添加特殊标识符,形式如“[Paragraph=N]”,“[Table=N]”以及“[List=N]”。通过判断文档片段中是否存在长答案和短答案,我们将训练数据的答案类别分为以下五类,分别是1)文档片段中包含所有短答案实体;2)文档片段中包含长答案,短答案为“yes”;3)文档片段中包含长答案,短答案为“no”;4)文档片段只包含长答案,没有短答案;5)文档不包含任何答案。
通过这种处理方式,我们得到的训练数据绝大部分都为第五种答案类型,为了平衡训练样本的类别,我们将这种不包含答案的样例随机筛选掉97%,最后得到大约660,000训练样例,其中有350,000条训练样例包含长答案,270,000条训练样例包含短答案。
模型框架
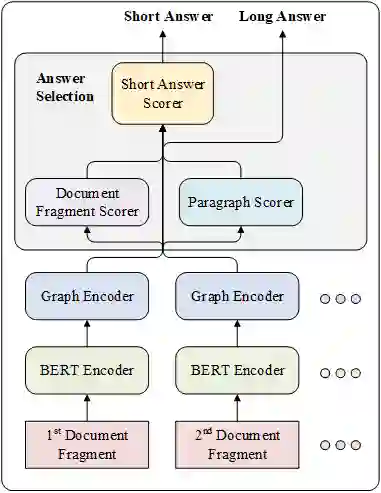
我们针对这种NQ数据集提出了一个新的框架,整体系统架构如图3所示,我们将问题以及文档的每个片段独立的输入到模型中,通过BERT编码器进行编码,得到问题和文档片段的初步表示,然后用我们提出的图编码器用得到的表示进一步建模,最终得到一系列结构化的表示,汇总到答案选择模块得到答案。
多粒度文档建模
将文档进行多粒度建模的思想主要来源于文档自身的层次结构特性,通常来讲,文档可以被分解成一系列段落,而段落可以进一步被分解成句子以及词,所以可以很自然的将文档先表示为树结构,分别有以上四种粒度的节点。由于长答案都是文档中的段落,短答案都是文档中的词片段,所以段落粒度节点的信息可以表示长答案,短答案的信息也可以从词粒度节点中获得。在以上得到的树结构基础上,我们进一步的加入了词粒度节点和段落粒度节点的边,词粒度节点和文档级别粒度的边,以及句子粒度节点到文档粒度节点的边,这些边在图中都是双向边。通过将树结构进一步建模成图结构,图中的每两个节点的距离都小于等于2,也就是说信息可以在两步之内进行传递。
图编码器
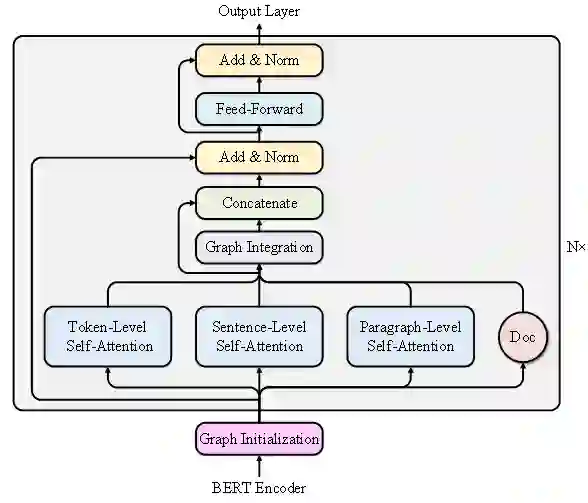
图4 图编码器内部结构
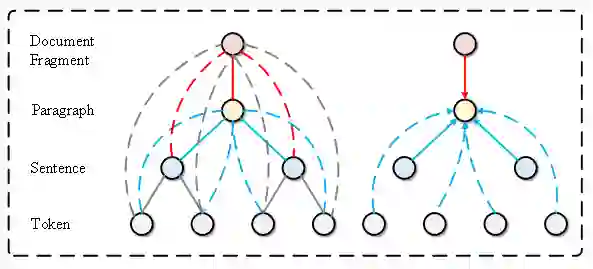
图5 Graph Integration层示例,左侧是文档建模生成的图,右侧为更新段落粒度节点的图例,信息由其他右边相连的节点输入
图4给出了我们图编码器的内部结构。每一层编码器都由三个自注意力(Selfattention)层,一个图信息整合(Graph Integration)层,以及一个前馈神经网络(Feed-forward)层组成。
图中的图初始化(Graph initialization)模块是一个在文档的树结构上自底向上的average-pooling的初始化,由于BERT编码器只能给出词粒度的表示信息,所以这一步主要是用来获得其他粒度的初始表示。
自注意力机制在原理上等价于图注意力网络的全连接版本,由于得到的图表示本质上是异构的,我们加入自注意力层的目的是使同粒度的节点之间进行充分的交互。
图信息整合层的目的是将经过上一步更新之后的节点信息传到与其相关但是粒度不同的节点上,使得节点可以整合不同粒度的信息,如图5所示。
除此之外,我们加入了关系向量(Relational Embedding),它可以将边的信息融入到图网络模型中。受前人工作启发,我们的关系向量主要加入了文档的结构信息,举例说明,段落节点在接受信息时会考虑另外的节点是这个段落的第几个句子或者词。通过这种方式,我们将文档的结构信息在模型的表示中进一步的加强。
在得到这些不同粒度的表示后,我们通过对这些表示进行打分,再进行模型预测。我们进行预测时使用Pipeline策略:先预测长答案,再预测短答案,与之前基于BERT的方法中预测短答案再从长答案候选项中选择不同,我们在实验部分将后者视为基线模型。
实验结果
我们使用了三个模型设置,分别是:1)Model-I:基线模型,首先预测短答案,根据短答案的位置在长答案候选项中进行选择;2)Model-II:只使用average-pooling初始化图,并进行Pipeline预测;3)Model-III:在Model-II的基础上加入了两层图神经网络编码器。
表1我们在NQ上的最佳模型的结果和前人工作中系统的比较,以及单人标注结果和多人标注集成结果的性能。
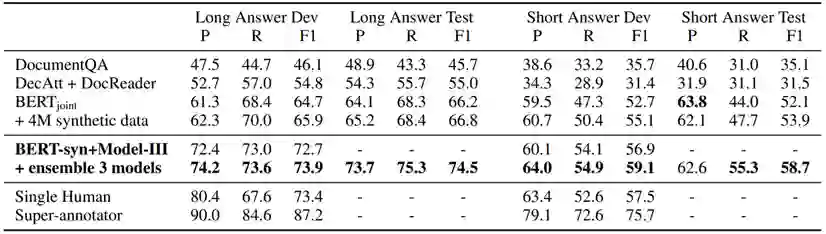
表2 不同的模型设置和使用不同BERT模型时在开发集上的性能比较
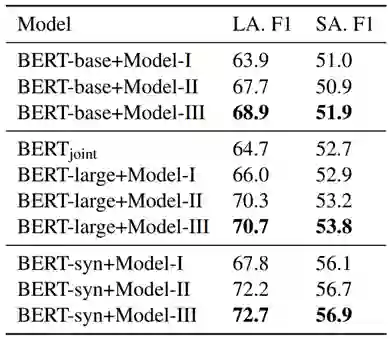
表2给出了使用不同BERT模型时,我们的三种模型设置在开发集上的性能比较。结果表明我们的方法在基线模型的基础上有着显著的提升。在BERT-base的设置下,我们使用Pipeline预测方法的Model-II相较于基线模型在长答案的指标下有3.8%的提升,而Model-III通过加入图神经网络,在两个指标进一步提升了1.2%和1.0%。在同样使用BERT-large的情况下,我们的Model-III和之前工作的BERT_joint相比在开发集的两个指标上有6.0%和1.1%的提升,并且表2和表3中的实验结果都是由三个不同的随机种子初始化模型后取平均得到,实际上提升要比平均结果稍大。
表3 在开发集上的对比实验
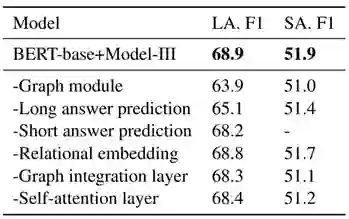
表3给出了在BERT-base的设置下,我们模型在开发集上的对比实验结果,首先将我们图相关模块全部移除,结果会大幅下降。然后我们尝试去掉两个子任务其中之一再进行训练,发现结果也会有一定程度的下降,这表明联合训练两个子任务是有效的,并且两个子任务不是完全互相独立的。最后我们分别去掉图编码器中的几个模块,结果都会有不同程度的下降,这些对比实验说明了我们模型每个组件的重要性。
结论
本文提出了一个新的多粒度阅读理解框架,并且在NQ数据集上验证了其有效性。我们利用文档自身的层次结构特性,以四个粒度建模文档,并且同时考虑NQ中两个粒度答案的依赖关系。实验结果表明我们提出的方法是非常有效的,并且相比现有方法有了大幅度的提升。
参考文献
[2] Chris Alberti, Kenton Lee, and Michael Collins. 2019b. A BERT baseline for the Natural Questions. arXiv preprint arXiv:1901.08634.
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proc. of NIPS.
[4] Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading wikipedia to answer opendomain questions. In Proc. of ACL.
[5] Jianpeng Cheng and Mirella Lapata. 2016. Neural summarization by extracting sentences and words. In Proc. of ACL.
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proc. of NAACL.
[7] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. ` 2018. Graph attention networks. In Proc. of ICLR.
[8] Chris Alberti, Daniel Andor, Emily Pitler, Jacob Devlin, and Michael Collins. 2019a. Synthetic QA corpora generation with roundtrip consistency. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers.




