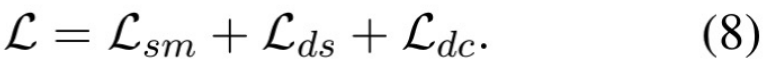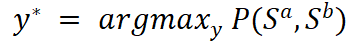这篇ACL 2022研究提出了一个简单而有效的文本语义匹配的训练策略,通过分治的方式将关键词从意图中分离出来。
作为国际最受关注的自然语言处理顶级会议,每年的 ACL 都吸引了大量华人学者投稿、参会。今年的 ACL 大会已是第 60 届,于 5 月 22-5 月 27 举办。受到疫情影响,国内 NLP 从业者参与大会受到很多限制。
为了给国内 NLP 社区的从业人员搭建一个自由轻松的学术交流平台,机器之心在 5 月 21 日组织了「ACL 2022 线上论文分享会」。
腾讯 QQ 浏览器搜索技术部高级工程师唐萌为我们带来了论文《Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents》分享。该论文已被 ACL 2022 接收。
以下是唐萌论文分享的回顾视频。本文也对该论文核心内容进行了介绍。
论文地址:https://arxiv.org/abs/2203.02898
文本语义匹配是一项被广泛应用到各种场景的基本任务,如社区问答、信息检索和推荐等。最新的匹配模型,例如 BERT,通过统一处理每个词来直接进行文本的比较。然而,查询语句通常需要在不同的粒度上与内容进行匹配。具体的,关键词代表了应该严格匹配的事实信息,如动作、实体、事件。而意图词则表达了抽象的概念和想法,通常有多种表达方式。在这项工作中,我们提出了一个
简单而有效的文本语义匹配的训练策略,通过分治的方式将关键词从意图中分离出来
。我们的方法可以很容易的与预训练语言模型(PLM)相结合,不影响其推理效率。在三个基准集上,实现了在广泛 PLM 模型上的稳定效果提升。
DC-Match 匹配,可以很容易的与文本匹配分类模型相结合。它包括三个训练目标,即: 全局匹配模型的分类损失;基于远程监督的分类损失,用于区分出关键词和意图;遵循分治思想的特殊训练目标,使用 KL-divergence 来确保全局匹配分布 (原始问题) 与分离开关键词和意图 (子问题) 后所得出的组合分布是相似的。
首先, 我们定义文本语义匹配任务,即给定两个文本序列
![]() 和
和
![]() ,文本语义匹配的目标是学习一个分类器
,文本语义匹配的目标是学习一个分类器
![]() 来预测序列
来预测序列
![]() 是否是语义等价的。
这里
是否是语义等价的。
这里
![]() 代表两个序列中第 i 个和 j 个词,
代表两个序列中第 i 个和 j 个词,
![]() 代表两个序列的长度,
y 可以是二分类的目标来预测两个序列是否等价,也可以是多分类目标来反映文本序列的匹配程度。
最近,预训练语言模型 (PLM) 在文本理解和表征学习方面取得了显著的成功。它们在具有启发式自监督学习目标的大规模文本语料库上被预训练,然后被作为强有力的序列分类器在下游分类任务中被 fine-tuning。对于文本语义匹配任务,通常通过增加
代表两个序列的长度,
y 可以是二分类的目标来预测两个序列是否等价,也可以是多分类目标来反映文本序列的匹配程度。
最近,预训练语言模型 (PLM) 在文本理解和表征学习方面取得了显著的成功。它们在具有启发式自监督学习目标的大规模文本语料库上被预训练,然后被作为强有力的序列分类器在下游分类任务中被 fine-tuning。对于文本语义匹配任务,通常通过增加
![]() 来连接
来连接
![]() ,
并作为 PLM 编码器的输入序列。
,
并作为 PLM 编码器的输入序列。
![]() 是每个序列前面的一个特殊标记,这个标记对应的最终隐藏状态作为整个序列的表示。
在 fine-tuning 阶段,仅引入分类层来进行最终的预测。
这里
是每个序列前面的一个特殊标记,这个标记对应的最终隐藏状态作为整个序列的表示。
在 fine-tuning 阶段,仅引入分类层来进行最终的预测。
这里
![]() 代表可训练的权重,K 代表分类的类别数:
代表可训练的权重,K 代表分类的类别数:
![]()
![]()
我们假设每个句子都可以分解为关键词和意图。直观地说,关键词代表事实信息,例如应该严格匹配的动作和实体,而意图传达可以用不同方式表达的抽象概念或想法。通过将关键字从意图中分离出来,匹配过程可以分成两个更容易的子问题,这两个子问题需要不同级别的匹配粒度。
在缺乏人工标注数据的前提下,为了自动的分离开关键词和意图, 我们借鉴了远程监督方法。我们通过引入外部知识库中的实体, 来提取原始文本中的实体提及来自动生成关键词标签。所有提取的实体被标记为关键词,句子中的剩余单词被标记为意图。在获得弱标签信息后,我们添加一个辅助训练目标,迫使模型学习分离出关键字和意图。
给定 PLM 的输出,我们把输出分为两组, 分别对应关键词分类和意图词分类两个目标,分类目标的损失函数如下, 其目标是推动 PLM 学习关键字和意图的表示, 使得它们彼此远离, 使得模型可以在不同的粒度上对句子内容进行建模:
![]()
我们将原匹配问题分成两个更容易的子问题: 关键词匹配和意图匹配,并假设它们相互独立,然后将子问题的解组合起来,给出原问题的解。
我们假设每个子问题遵循与原问题相同的目标,组合得到的概率分布 Q(y)可以从两个子问题的联合概率分布 P(yk, yi) 导出, 如下:
![]()
其中,
![]() 表示匹配度的目标类别,
表示匹配度的目标类别,
![]() 意味着
意味着
![]() 具有比
具有比
![]() 更高的匹配分数。
例如,在三类场景中,y ∈ {2,1,0}分别表示完全匹配、部分匹配和不匹配,Q(y = 0)即至少有一个子问题被推断为不匹配的概率。
为了对子问题建模,我们重新使用 PLM 模型来分别对关键词和意图进行匹配,并且获得条件概率
更高的匹配分数。
例如,在三类场景中,y ∈ {2,1,0}分别表示完全匹配、部分匹配和不匹配,Q(y = 0)即至少有一个子问题被推断为不匹配的概率。
为了对子问题建模,我们重新使用 PLM 模型来分别对关键词和意图进行匹配,并且获得条件概率
![]() 代表 mask 掉意图的文本序列,
代表 mask 掉意图的文本序列,
![]() 代表 mask 掉关键词的文本序列。那么,在独立子问题的假设
下,
代表 mask 掉关键词的文本序列。那么,在独立子问题的假设
下,
![]() 的条
件联合分布为:
的条
件联合分布为:
![]()
最后,为了确保全局匹配分布 (原始问题) 与子问题的组合解分布相似,我们使用双向 KL - 散度来最小化两个分布之间的距离,通过这种方式,我们期望全局匹配模型学会更好地做出最终预测:
![]()
在训练阶段,我们结合三个损失函数
![]() 来联合训练模型:
来联合训练模型:
![]()
在推理时,我们根据原问题的条件概率直接推断句子对的匹配类别,
即:
这意味着我们的推理过程与 PLM 基线完全相同,没有额外的计算。虽然我们使用外部语料库来自动获得远程监督的标签,但它可能会导致信号不完整或有噪声,从而给子问题引入偏差。因此,,我们只在训练阶段使用其标签作为全局匹配模型的辅助信息来进行增强。
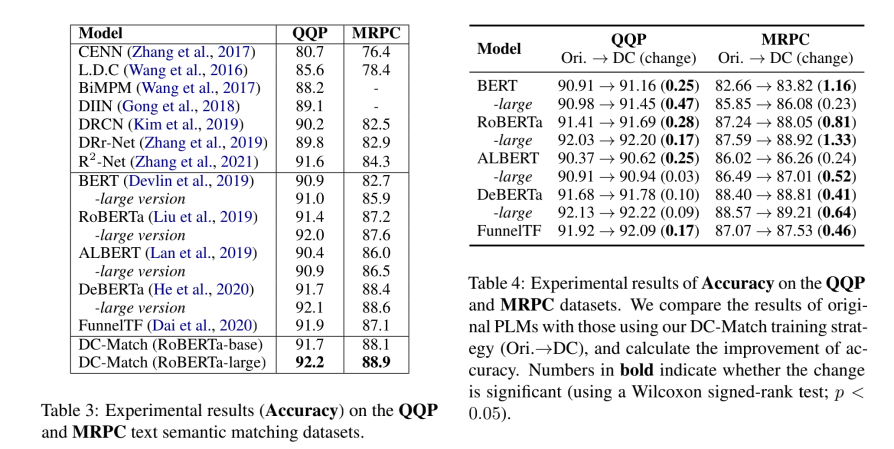
在实验阶段, 我们在三个文本语义匹配基准上评估了我们的方法和所有基线:两个英文数据集 MRPC 和 QQP,以及一个中文数据集 Medical-SM。为了公平比较,我们使用相同的超参数来微调每个 PLM 的原始版本及其 DC-Match 变体。
实验中,模型分为两组。第一组是传统的神经网络方法,第二组是受益于大规模预训练的 PLMs。我们可以看到,PLMs 的表现优于传统的神经匹配模型。
我们对不同的 PLMs 进行了实验。数据可见,所有 PLMs 的匹配精度在两个数据集上都稳定增加。这表明,通过将匹配问题分解成更容易的子问题,这种分治策略可以有效地给出原问题更好的解决方案。尤其我们可以看到,DC-Match 策略为小数据集 MRPC 带来了更显著的效果提升。这表明关键词和意图的信息是文本语义匹配的重要特征。尤其是当训练数据有限而无法找到有用的潜在模式时。
![]()
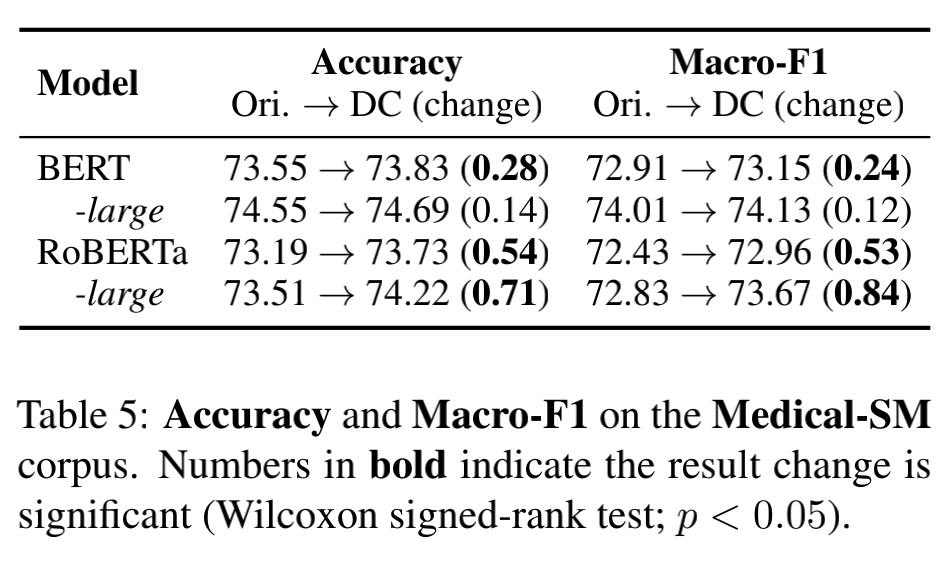
此外,我们在中文文本匹配数据集 Medical-SM 上评估了我们的方法。Medical-SM 是一个三级分类数据集,也即完全匹配、部分匹配、不匹配。除了 acc 之外,我们还使用 MacroF1 来作为评估指标。从表中看到 DC-Match 仍然提高了 PLMs 的匹配效果,表明我们的策略在多分类场景和不同语言中都是非常有效的。
![]()
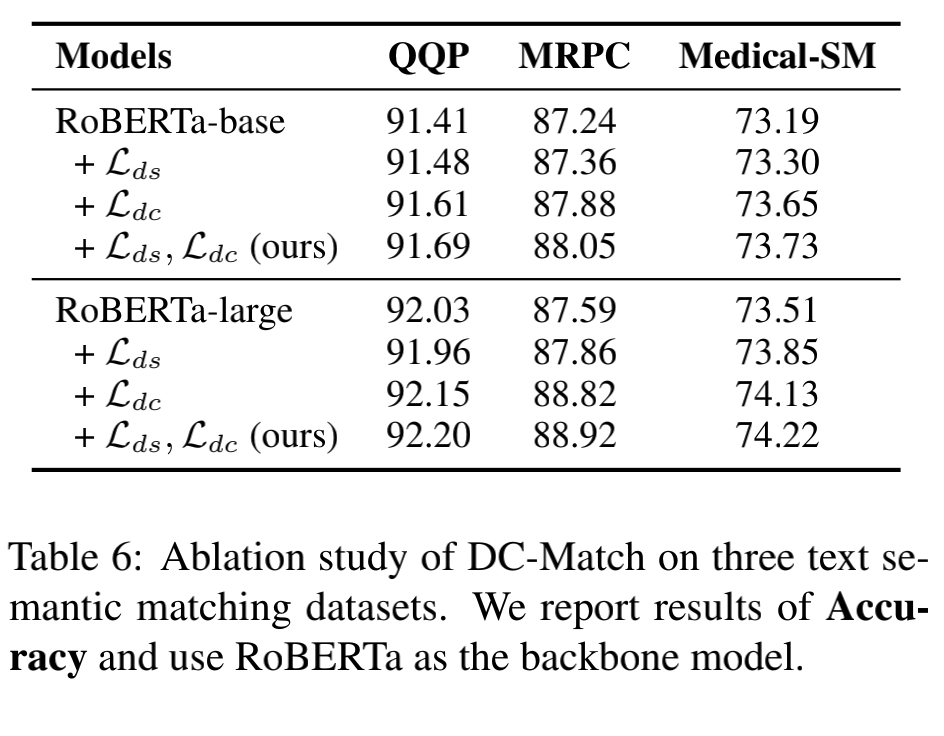
我们通过消融实验来论证每个子模块的有效性。以 roberta 模型为主模型,从图中数据可以得出,在仅添加了关键词和意图识别的远程监督损失 (+Lds) 之后,结果与原始 PLMs 没有显著不同。这反映了该辅助训练目标不能与原始文本匹配问题直接关联,因此 Lds 本身可能对最终目标没有帮助。然而,我们任务中移除 Lds,仅保持分治的训练目标(+Ldc),我们观察到与完整的 DC-Match 版本相比,效果有所下降。
这说明,远程监督目标确实有助于模型学会将关键字从意图中分离出来,并获得不同匹配粒度级别的有区别的内容表示,这有助于子问题的解决。
![]()
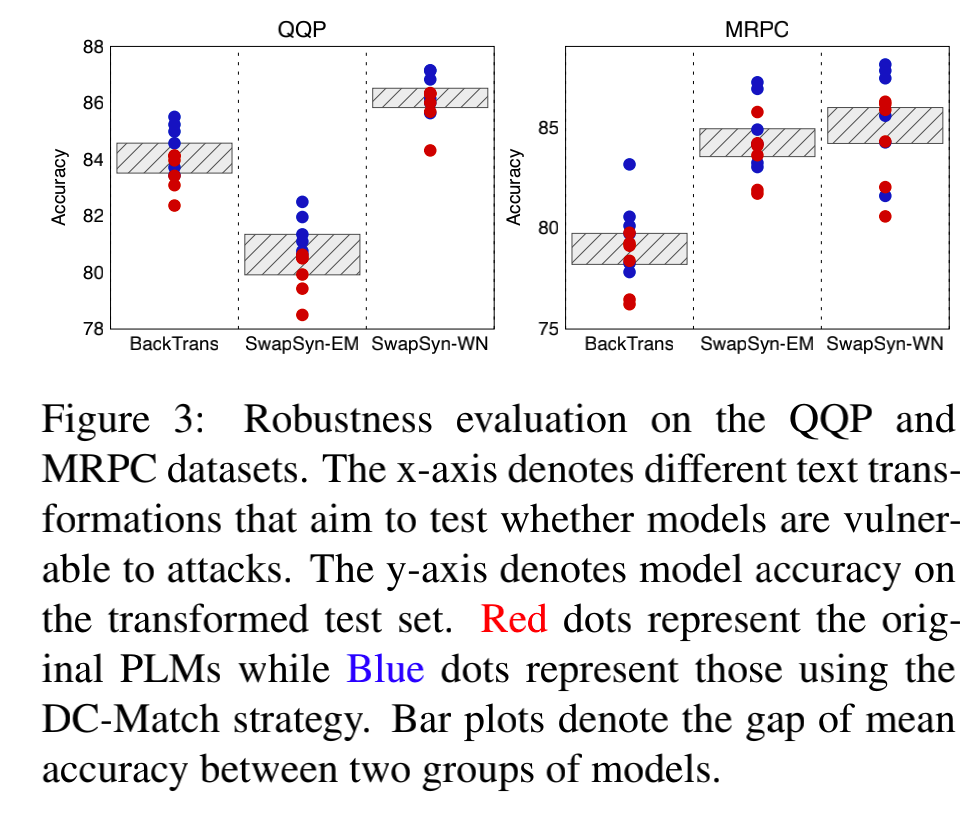
分治策略将关键字从意图中分离出来,为最终的匹配判断提供了额外的可解释性。我们通过进行多中文变化来评估 DC-Match 鲁棒性。我们观察到原始 PLM 和它们的 DC-Match 变体的效果都有所下降。然而,与原始 PLMs 相比,DC-Match 增强后的 PLMs 可以保持更稳定的效果,这表明 DC-Match 可以在一定程度上提高 PLMs 对于文本语义匹配任务的鲁棒性。
![]()
QQ 浏览器实验室成立于 2021 年,致力于探索下一代信息与服务获取和交互方式。未来将依靠 AI、搜索、大数据、推荐算法的技术研究,提升信息与服务的获取效率,革新用户与世界的交互方式,成为探索下一代信息与服务获取方式和交互方式的研究平台。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
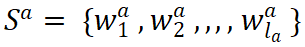 和
和
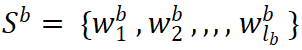 ,文本语义匹配的目标是学习一个分类器
,文本语义匹配的目标是学习一个分类器
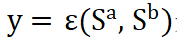 来预测序列
来预测序列
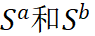 是否是语义等价的。
这里
是否是语义等价的。
这里
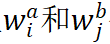 代表两个序列中第 i 个和 j 个词,
代表两个序列中第 i 个和 j 个词,
 代表两个序列的长度,
y 可以是二分类的目标来预测两个序列是否等价,也可以是多分类目标来反映文本序列的匹配程度。
代表两个序列的长度,
y 可以是二分类的目标来预测两个序列是否等价,也可以是多分类目标来反映文本序列的匹配程度。
 来连接
来连接
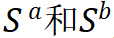 ,
并作为 PLM 编码器的输入序列。
,
并作为 PLM 编码器的输入序列。
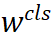 是每个序列前面的一个特殊标记,这个标记对应的最终隐藏状态作为整个序列的表示。
在 fine-tuning 阶段,仅引入分类层来进行最终的预测。
这里
是每个序列前面的一个特殊标记,这个标记对应的最终隐藏状态作为整个序列的表示。
在 fine-tuning 阶段,仅引入分类层来进行最终的预测。
这里
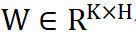 代表可训练的权重,K 代表分类的类别数:
代表可训练的权重,K 代表分类的类别数:
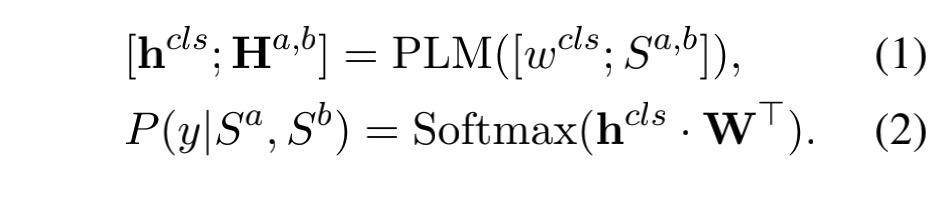
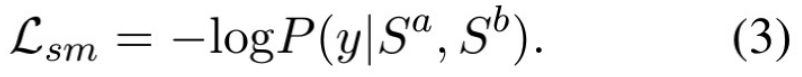
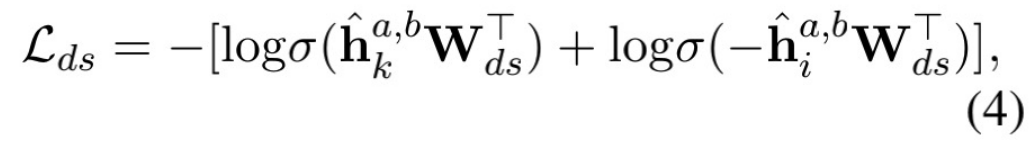
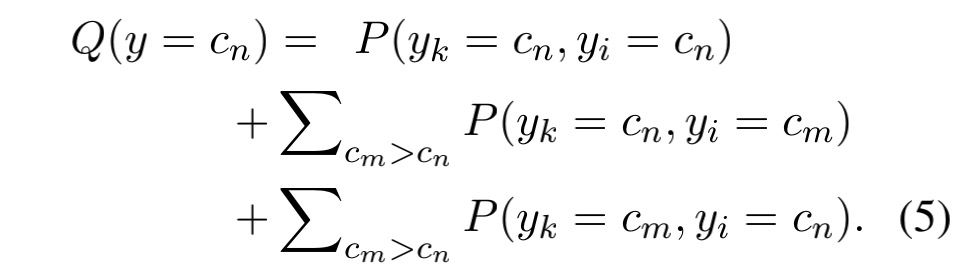
 表示匹配度的目标类别,
表示匹配度的目标类别,
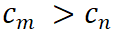 意味着
意味着
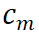 具有比
具有比
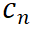 更高的匹配分数。
例如,在三类场景中,y ∈ {2,1,0}分别表示完全匹配、部分匹配和不匹配,Q(y = 0)即至少有一个子问题被推断为不匹配的概率。
更高的匹配分数。
例如,在三类场景中,y ∈ {2,1,0}分别表示完全匹配、部分匹配和不匹配,Q(y = 0)即至少有一个子问题被推断为不匹配的概率。
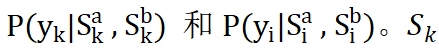 代表 mask 掉意图的文本序列,
代表 mask 掉意图的文本序列,
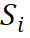 代表 mask 掉关键词的文本序列。那么,在独立子问题的假设
下,
代表 mask 掉关键词的文本序列。那么,在独立子问题的假设
下,
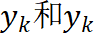 的条
件联合分布为:
的条
件联合分布为:
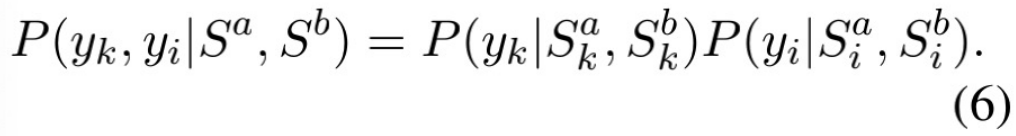
 来联合训练模型:
来联合训练模型: