线下沙龙 × 北京 | 最in强化学习 + NLP技术分享会,你来不来?
在过去一年里
PaperWeekly陆续走过了一些城市
我们在这些线下沙龙中受益良多
见到了许多可爱的读者
收集了许多有意义的反馈
我们非常珍惜这些机会
也希望未来能将触觉
延伸到更多城市和人群
就在本周日
2018年第一场线下学术沙龙
即将抢先登陆北京
这次,我们决定来点重量级的
等待你的不仅有
“强化学习在NLP中的应用”技术干货
还有你最想见到的嘉宾

帝都的NLPer们,准备好了吗?
▼


1 黄民烈

清华大学计算机系副教授,博士生导师。研究兴趣主要集中在人工智能、深度学习、强化学习,自然语言处理如自动问答、人机对话系统、情感与情绪智能等。
已超过 50 篇 CCF A/B 类论文发表在 ACL、IJCAI、AAAI、EMNLP、KDD、ICDM、ACM TOIS、Bioinformatics、JAMIA 等国际顶级和主流会议及期刊上。曾担任多个国际顶级会议的领域主席或高级程序委员,如 IJCAI 2018、IJCAI 2017、ACL 2016、EMNLP 2014/2011,IJCNLP 2017 等,担任 ACM TOIS、TKDE、TPAMI、CL 等顶级期刊的审稿人。作为负责人或学术骨干,负责或参与多项国家 973、863 子课题、多项国家自然科学基金,并与国内外知名企业如谷歌、微软、三星、惠普、美孚石油、斯伦贝谢、阿里巴巴、腾讯、百度、搜狗、美团等建立了广泛的合作。获得专利授权近 10 项,其中 2 项专利技术授权给企业应用。
自然语言处理中的深度强化学习应用
以 Alpha GO/Zero 为代表的深度强化学习在许多应用中取得了前所未有的成功。演讲者将重点介绍深度强化学习在自然语言处理中如何处理非直接信号的弱监督学习问题,介绍如何利用有限的、弱的、非直接的监督信号实现学习目标。
包括几个方面的工作:仅依赖类别标记的监督信号,从无结构文本中的探索任务相关的文本结构(structure discovery);噪声文本数据中进行样本去噪(data denoising)以获得更好的关系抽取性能;在大型的在线系统中,如何利用用户的隐式反馈实现多场景的联合优化。
这些工作具有的共性是:在无直接监督信息、弱信号场景中,利用强化学习的试错和概率探索能力,通过编码先验或领域知识,达到学习目标。演讲者也将分享强化学习应用中的一些经验和教训。
2 李纪为

博士,香侬科技创始人 & CEO。本科毕业于北京大学生命科学学院,博士毕业于斯坦福大学计算机学院,研究领域为自然语言处理、深度学习。他是斯坦福大学计算机系历史上第一个三年取得博士学位的研究生。博士期间曾经在顶级会议 ACL、EMNLP、ICLR 等发表文章 20 余篇。2017 年创立 AI+Fintech 初创公司香侬科技,获得红杉资本数千万天使轮融资
生成对话中的强化学习
在这个 Talk 中,嘉宾将讨论两个生成对话中强化学习的应用:
1. 通过模拟两个 Agent 的聊天获得更持久的、稳定的对话策略;
2. 将对抗学习引入到对话生成模型中:因为对抗学习判别器的反馈对于生成模型来说是不可求导的,所以只能通过强化学习的手段将判别器的反馈传递给生成模型,这里将重点讨论如何训练一个稳定的基于强化学习的对抗网络对话模型。

4月22日(周日)14:00-17:00

北京理工大学(中关村校区)
研究生院101报告厅
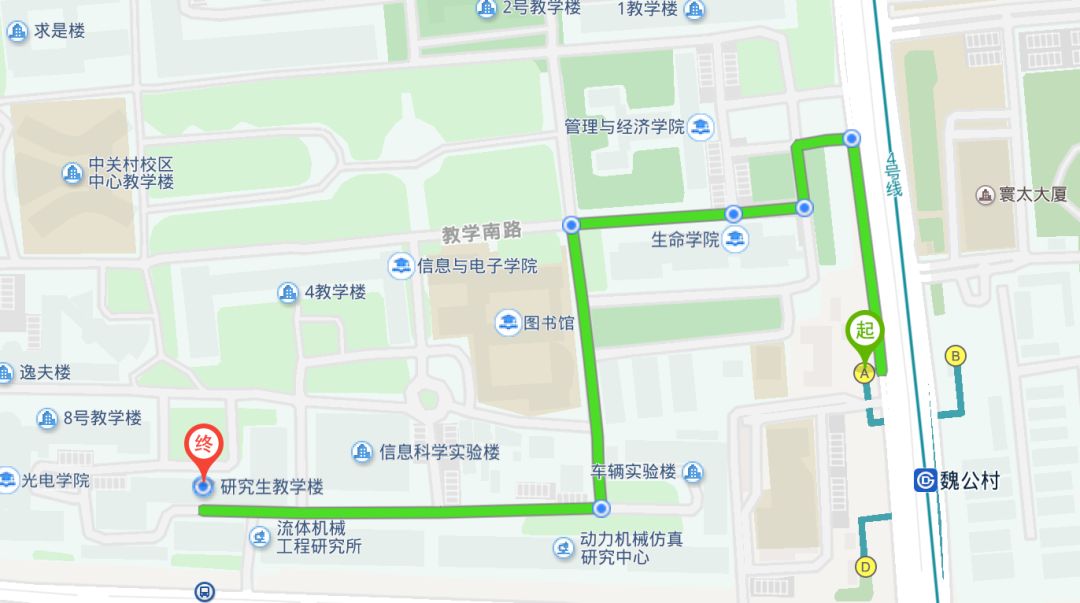
交通路线
1. 乘坐地铁 4 号线,在魏公村站下车,由 A 口出,从北京理工大学东门进入校园;
2. 乘坐 563、645、运通 103 路在魏公村路东口站下车,从北理工小南门(或称东南门,附近有很多快递)进入校区;
3. 乘坐 26、355、365 路等路线在三义庙站下车,从北理工北门进入校区。
进入校园以后,大家可以直接问可爱的同学或者导航到达,导航目的地为北京理工大学-研究生教学楼。

1 点击文末「阅读原文」填写报名表;
2 本次活动名额为 200 人,请认真填写报名信息,方便工作人员进行筛选;
3 活动报名截止时间为 4 月 20 日 20:00;
4 我们将在 4 月 21 日 12:00 前通知报名入选情况,逾期没收到通知即为落选,敬请期待 PaperWeekly 的下次活动:)


关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 立刻报名





