现在的 AI 到底有没有意识?如何定义意识?AI 的前进方向是通过更好的数据标签来改善监督学习,还是大力发展自监督 / 无监督学习?在 IEEE Spectrum 的最近的一次访谈中,图灵奖得主、Meta 首席 AI 科学家 Yann LeCun 表达了自己的看法。
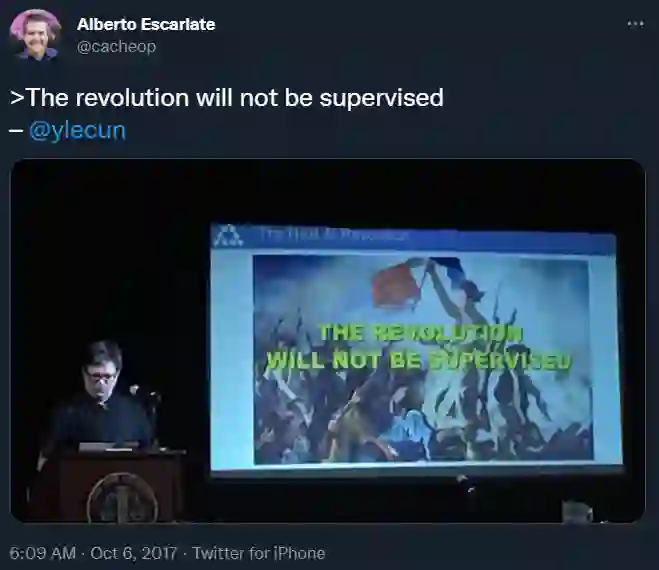
Yann LeCun 在演讲时曾经放过一张法国大革命时期的著名画作《自由引导人民》,并配文:「这场革命将是无监督的(THE REVOLUTION WILL NOT BE SUPERVISED)」。
LeCun 相信,当 AI 系统不再需要监督学习时,下一次 AI 革命就会到来。届时,这些系统将不再依赖于精心标注的数据集。他表示,AI 系统需要在学习时尽可能少得从人类这里获取帮助。
在最近接受 IEEE Spectrum 的访谈时,他谈到了自监督学习如何能够创造具备常识的强大人工智能系统。同时,他也对最近的一些社区言论发表了自己的看法,比如吴恩达对「以数据为中心的 AI」的拥护、 OpenAI 首席科学家 Ilya Sutskever 对于当前 AI 可能具备意识的推测等。
Q:您曾经说过,监督学习的限制有时会被误以为是深度学习自身的局限性所致,那么哪些限制可以通过自监督学习来克服
A:监督学习非常适用于边界清晰的领域,在这类领域中,你可以收集大量标记数据,而且模型在部署期间看到的输入类型和训练时使用的输入类型差别不大。收集大量不带偏见的标记数据是非常困难的。这里的偏见不一定是指社会偏见,可以理解为系统不该使用的数据之间的相关性。举个例子,当你在训练一个识别牛的系统时,所有的样本都是草地上的牛,那么系统就会将草作为识别牛的上下文线索。如此一来,如果你给它一张沙滩上的牛的照片,它可能就认不出来了。
自监督学习(SSL)可以让系统以独立于任务的方式学习输入的良好表示。因为 SSL 训练使用的是未标注的数据,所以我们可以使用非常大的训练集,并让系统学习更加稳健、完整的输入表示。然后,再利用少量的标注数据,它就可以在监督任务上达到良好的性能。这大大减少了纯监督学习所需的标记数据量,并使系统更加稳健、更能够处理与标注训练样本不同的输入。有时,它还会降低系统对数据偏见的敏感性。
在实用 AI 系统这一方向,我们正朝着更大的架构迈进,即用 SSL 在大量未标注数据上进行预训练。这些系统可以用于各种各样的任务,比如用一个神经网络处理数百种语言的翻译,构造多语言语音识别系统等。这些系统可以处理数据难以获取的语言。
Q:其他领军人物表示,AI 的前进方向是通过更好的数据标签来改善监督学习。吴恩达最近谈到了以数据为中心的 AI,英伟达的 Rev Lebaredian 谈到了带有所有标签的合成数据。在 AI 的发展路径方面,业界是否存在分歧?
A:我不认为存在思想上的分歧。在 NLP 中,SSL 预训练是非常标准的实践。它在语音识别方面表现出了卓越的性能提升,在视觉方面也变得越来越有用。然而,「经典的」监督学习仍有许多未经探索的应用,因此只要有可能,人们当然应该在监督学习中使用合成数据。即便如此,英伟达也在积极开发 SSL。
早在零几年的时候,Geoff Hinton、Yoshua Bengio 和我就确信,训练更大、更深的神经网络的唯一方法就是通过自监督(或无监督)学习。也是从这时起,吴恩达开始对深度学习感兴趣。他当时的工作也集中在我们现在称之为自监督的方法上。
Q:如何基于自监督学习构建具有常识的人工智能系统?常识能让我们在构造人类智能水平的智能上走多远?
A:我认为,一旦我们弄清楚如何让机器像人类和动物一样学习世界是如何运作的,人工智能必将会取得重大进展。因此人工智能要学会观察世界,并在其中采取行动。人类了解世界是如何运作的,是因为人类已经了解了世界的内部模型,使得我们能够填补缺失的信息,预测将要发生的事情,并预测我们行动的影响。我们的世界模型使我们能够感知、解释、推理、提前规划和行动。
对于第一个问题,我的答案是自监督学习(SSL)。举个例子,让机器观看视频并暂停视频,然后让机器学习视频中接下来发生事情的表征。在这个过程中,机器可以学习大量关于世界如何运作的背景知识,这可能类似于婴儿和动物在生命最初的几周或几个月内的学习方式。
对于第二个问题,我的答案是一种新型的深度宏架构(macro-architecture),我称之为分层联合嵌入预测架构(H-JEPA)。这里很难详细解释,以上述预测视频为例,JEPA 不是预测视频 clip 的未来帧,而是学习视频 clip 的抽象表征和未来,以便能很容易地基于对前者的理解预测后者。这可以通过使用非对比 SSL 方法的一些最新进展来实现,特别是我们最近提出的一种称为 VICReg 的方法。
Q:几周前,您回复了 OpenAI 首席科学家 Ilya Sutskever 的一条推文。他推测当今的大型神经网络可能存在一些意识,随后您直接否定了这种观点。那么在您看来,构建一个有意识的神经网络需要什么?有意识的系统会是什么样子?
A:首先,意识是一个非常模糊的概念。一些哲学家、神经科学家和认知科学家认为这只是一种错觉(illusion),我非常认同这种观点。
我有一个关于意识错觉的猜想。我的假设是:我们的脑前额叶皮质中有一个世界模型「引擎」。该世界模型可根据实际面对的情况进行配置。例如帆船的舵手用世界模型模拟了船周围的空气和水流;再比如我们要建一张木桌,世界模型就会想象切割木头和组装它们的结果...... 我们的大脑中需要一个模块,我称之为配置器(configurator),它为我们设定目标和子目标,配置我们的世界模型以模拟当下实际的情况,并启动我们的感知系统以提取相关信息并丢弃其余信息。监督配置器的存在可能是让我们产生意识错觉的原因。但有趣的是:我们需要这个配置器,因为我们只有一个世界模型引擎。如果我们的大脑足够大,可以容纳许多世界模型,我们就不需要意识。所以,从这个意义上说,意识是我们大脑存在局限的结果!
Q:在元宇宙中,自监督学习将扮演一个什么样的角色?
A:元宇宙中有很多深度学习的具体应用,例如用于 VR 和 AR 的运动跟踪、捕捉和合成身体运动及面部表情等。
人工智能驱动的新型创新工具提供了广阔的创造空间,让每个人都能在元宇宙和现实世界中创造新事物。但元宇宙也有一个「AI-complete」应用程序:虚拟 AI 助手。我们应该拥有虚拟 AI 助手,他们可以在日常生活中为我们提供帮助,回答我们的任何问题,并帮助我们处理日常的海量信息。为此,人工智能系统需要对世界(包括物理世界和元宇宙的虚拟世界)如何运作有一定的了解,有一定的推理和规划能力,并掌握一定程度的常识。简而言之,我们需要弄清楚如何构建可以像人类一样学习的自主人工智能系统。这需要时间,而 Meta 已为此准备良久。
原文链接:https://spectrum.ieee.org/yann-lecun-ai
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com