![]()
本文约4015字,建议阅读8分钟
本文介绍
了围绕不同机器学习任务的AI数据集相关研究结
论。
数据集构成了机器学习研究的支柱。作为训练和测试机器学习模型的资源,它们深深融入机器学习研究人员的工作实践中。
其中,
基准数据集协助围绕共同研究问题的研究学者,并为他们提供稳定的衡量标准
。基准测试的改进表现被认为是集体进步的关键信号。因此,这种表现受到个别研究人员的追捧,并用来对他们的贡献进行评估和排名。
此外,基准数据集与“现实世界”任务的紧密结合,对于其是否能够准确衡量集体科学进步,以及关注其是否合乎法律、合乎道德安全和能否有效部署模型等方面的研究具有重要意义。
鉴于基准数据集在社会和 MLR 科学组织中的核心作用,近年来它们也成为批判性调查的核心对象。尽管对基准数据集的关注越来越多,但令人惊讶的是,很少有人关注整个领域的数据集的使用和重用模式。
由加州大学洛杉矶分校和谷歌研究院联合发表的最新论文 Reduced, Reused and Recycled: The Life of aDataset in Machine Learning Research,则深入研究了这些动态,在 Papers With Code(PWC)语料库中研究数据集使用模式在机器学习子社区和时间(2015-2020 年)之间有何不同
(“数据实战派”后台回复“3R”获取论文下载地址)
。
更具体地说,本文研究围绕不同机器学习任务(例如,情感分析和面部识别)从以下三个研究问题进行分析:
研究问题 1(RQ1)
:机器学习任务社区在特定数据集上的集中程度如何?随着时间的推移,这种情况是否发生了变化?
研究问题 2(RQ2)
:机器学习研究人员从其他任务借用数据集,而不是使用为该任务明确创建的数据集的频率如何?
研究问题 3(RQ3)
:哪些机构负责“流通”中的主要 ML 基准?
本文主要数据来源是 Papers With Code (PWC),这是一个由 Facebook AI Research 的研究人员创建的机器学习论文、数据集和评估表的开源存储库。
该研究主要关注“数据集”档案,以及使用这些数据集的论文。档案中的每个数据集都与元数据相关联。本文在网站上找到了 4,384 个数据集,找到与这些数据集相关联的 60,647 篇论文。
因为本文对数据集在任务社区内和跨任务社区内使用的动态感兴趣,所以对前两个研究问题(RQ1 和 RQ2)的分析任务,仅限于发表在带有任务注释的论文中的数据集用法。本文将最初设计数据集的任务称为“原始任务”。将使用数据集的论文任务称为“目标任务”。例如,ImageNet 最初被引入作为对象识别和对象定位(原始任务)的基准,现在也经常用作图像生成(目标任务)等的基准。
分析 RQ1 和 RQ2 和数据集:为了最大限度地减少跨父任务和子任务的数据集使用的重复计算,本文选择专门关注 PWC 中的父任务。在这些分析中使用的结果度量(基尼系数、采用比例和创作比例)在小样本中会存在偏差,因此本文仅使用超过 34 篇论文的中位数大小的父任务。因为父任务通常更大且更广泛,所以往往被认为是连贯的任务社区。表 1 显示了每个分析中使用的数据的描述性统计。
分析 RQ1 探索了任务中数据集的使用,它包括论文中引入的数据集以及未引入的数据集(例如,在网站或竞赛中引入的数据集)。分析RQ2探讨了源任务和目标任务之间的数据集传输。因为本文只能确定在论文中引入的数据集的原始任务(表 1),因此该数据集通常较小。
分析 RQ3 的数据集:为了研究广泛使用的数据集在机构间的分布,本文将所有介绍数据集的论文链接到 Microsoft Academic Graph (MAG)中。对数据集的使用情况进行了分析,其中最后一个作者将数据集的隶属关系在 MAG 中进行了注释(见表 1)。
与此同时,该研究再次施加限制,即用法必须与数据集共享标记任务,再次发现它对结果的影响最小。
为了衡量任务社区在某些数据集上的集中程度,本文计算每个任务中观察到的数据集使用分布的基尼系数(Gini)。Gini 是频率分布离散度的连续度量。社会科学中经常使用它来研究不平等。Gini 的分值通常在 0 和 1 之间变化,0 表示任务中的论文以相等的比例使用所有数据集,1 表示在所有使用数据集的论文中仅使用单个数据集。Gini 计算如公式(1)所示。
其中,xi 表示任务中所有 n 个数据集中数据集i被使用的次数。
因为 Gini 在小样本中可能存在偏差,本文使用样本校正的 Gini:,以及排除少于 10 篇论文的任务。
回归模型 1:除了描述性统计之外,本文还建立了一个回归模型,用来评估观察到的 Gini 逐年趋势在多大程度上可归因于混杂变量,例如任务大小、任务年龄或其他特定于当年(2015-2020 年)的任务特征。
1)年份(Year),因为本文对集中程度随时间变化的趋势十分感兴趣;
2)计算机视觉、自然语言处理、方法学(CV,NLP,Methods),三个虚拟变量,指示任务是否属于PWC中的计算机视觉、自然语言处理或方法学类别。
为了吸引额外的变化,本文还设置了以下几个
控制协变量
:
1)当年该任务使用数据集/介绍论文数量的任务大小(Task size);
2)任务年龄(Task age),因为较年轻的任务可能具有较高的Gini;
3)每个任务的随机截距(Random intercepts for each task),因为本文对时间进行了重复观察。
本文使用 beta 回归对 Gini 进行建模,因为 beta 分布非常灵活,且介于 0-1 之间,和 Cini 分布比较相似。对于 Gini 为 0 的偶然任务年,本文使用平滑变换来处理。本文使用具有以下交互作用的模型:
该模型是从一组具有双向和三向交互作用的嵌套模型中选择的,因为它具有最低的赤池信息准则(AIC)和贝叶斯信息准则(BIC)。
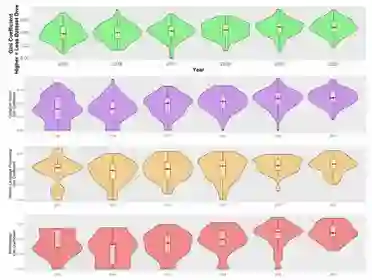
模型 1 发现随着时间的推移,完整数据集的任务社区集中度在不断增加。2015 年到 2020 年,预测 Gini 略微增加了 0.113。(见图 2 顶部绿色,表 2)。
这一趋势在这一时期的基尼系数总体分布中也很明显(图 2 底部)。到 2020 年,一项任务的基尼系数中位数为 0.60。与完整样本相比,CV 和 Methods 任务之间没有统计学上的显着差异(图 2 顶部,图 3),但模型 1 表明 NLP 任务社区的浓度增加减弱(图 2 顶部橙色)。这是唯一与本文的模型规格有所不同的结果;虽然 NLP 任务的集中度增加率始终显着低于数据集的其余部分,但这种变化的符号和斜率在不同模型之间确实有所不同。
本文创建了两个比例来更好地理解结果,分别是数据集使用模式的比例(Adoption Proportion)和任务中的创建的比例(Creation Proportion):
聚合描述性分析:首先计算 133 个父任务中的每一个任务聚合在所有年份的比例,并按“计算机视觉”、“自然语言处理”和“方法论”这三个类别将任务进行子集化。
回归模型2A&2B:因为本文选择将结果表述为离散事件的分数,所以逻辑回归是这些数据在理论上最合适的模型。本文使用混合效应逻辑回归对这些结果进行建模,并使用与回归模型 1 相同的预测变量。
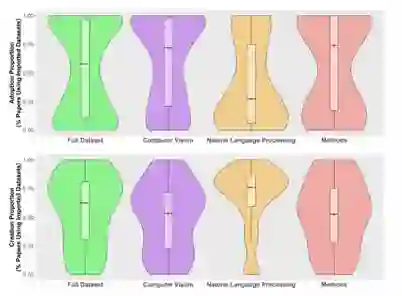
结果发现,图 4 的第一行显示完整样本和子类别的采用比例差异较大。在完整样本中,超过一半的任务社区至少有 57.8% 的时间在使用采用的数据集。然而,这个数字在 PWC 的三个子类别中差异很大。在超过一半的计算机视觉社区中,研究学者采用了至少 71.9% 的来自不同任务的数据集。在方法论社区任务中的等效统计数据为 74.1%。但是一半的自然语言处理社区采用数据集的时间不到 27.4%。
在图 4 的底行显示了一个大体反转的趋势。在超过一半的任务社区中,62.5% 的数据集是专门为该任务创建的。在计算机视觉和方法任务中,其中位数分别为 53.3% 和 52.6%。在超过一半的 NLP 社区中,76.0% 的数据集是专门为该任务创建的。
由于缺乏数据(结果未显示),本文无法以任何一种方式(回归模型 2A 和 2B)恢复采用或创建比例趋势的令人信服的证据。
为了研究使用更大的数据集的论文,随着时间的推移跨机构和数据集的基尼系数不均的趋势,本文计算了每年数据集和机构数据集使用情况的基尼系数 Gs。
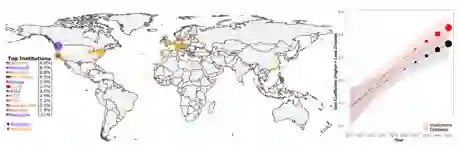
总的来说,本文发现只有少数精英机构引入的数据集被广泛使用(图 5 左)。事实上,截至 2021 年 6 月,PWC 中被使用的数据集中超过 50%,均来源于 12 家机构。此外,通过基尼系数衡量的精英机构引入的数据集,其集中度近年来已增加到 0.80 以上(图 5 右红色)。这种趋势在 PWC 中数据集的基尼浓度中也更普遍地观察到(图 5 右黑色)。
1)任务社区高度集中在数量有限的数据集上,并且这种集中度随着时间的推移而增加
2)这些社区内用于基准测试的数据集的很大一部分最初是为不同的任务开发的。
3)全球数据集使用的不平等越来越严重,50% 以上正在被使用数据集来源于由十二个精英机构(主要是西方机构)引入的数据集。
4)在 NLP 社区中,集中在少数数据集上的更广泛趋势有所缓和,新数据集以更高的速度创建,而外部数据集的使用率更低。
可能的解释是:NLP 任务社区往往比其他任务社区更大,较大的 NLP 社区可能更加连贯,因此比其他任务社区以更高的速率生成和使用自己的数据集;另一种可能性是 NLP 数据集更容易管理,因为数据更容易访问、更容易标记或更小。这个难题的解决超出了此次研究的范围,但 NLP 数据集的独特性质为未来的工作提供了一个有趣的方向。
首先对特定基准进行一定程度的研究,对于建立基准的有效性和作为基准获得社区一致性是必要且有益的进步。
其次,大规模数据集的管理不仅在资源方面成本高昂,而且一些独特或特权数据可能只有少数精英学术和企业机构才能访问(例如,匿名医疗记录、自动驾驶汽车日志)。
——END——