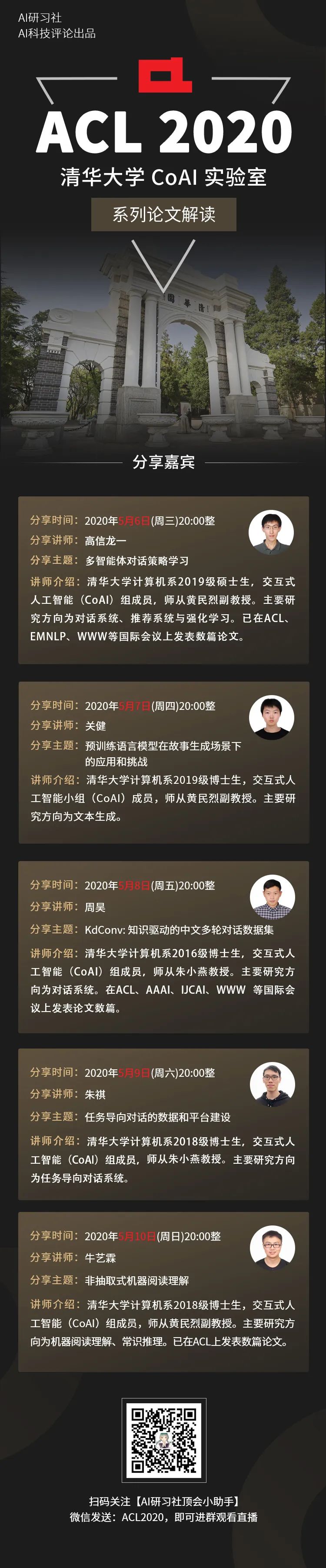
【直播】如何在故事生成中加入常识?

五一结束,直播继续!
故事生成(从一个主要背景中生成一个合理的故事)是一项重要而又具有挑战性的任务。
近来,GPT-2在建模流畅性和局部的连贯性上取得了极大的成功,然而仍然存在一系列问题,例如重复、逻辑冲突、生成故事缺乏长期连贯性等。
原因为何?
一个猜测是,这些问题来自于关联常识、理解因果关系以及实体和事件的时间排序等方面的困难。
在清华大学CoAI课题组发表于TACL 2020 的文章(将在ACL 2020 中展示)《A Knowledge-Enhanced Pretraining Model for Commonsense Story Generation》中,作者针对这一问题,设计了一个常识性故事生成的知识增强预训练模型。
文章建议,利用外部知识库中的常识来生成更为合理的故事。
为了进一步捕捉合理故事中句子之间的因果和时间依赖关系,作者使用了多任务学习,在微调过程中可以区分真实/虚假故事。
这项工作在故事生成的逻辑性和全局一致性上,具有非常好的性能。

1、故事生成的任务背景和相关工作
2、预训练语言模型在故事生成场景下的表现和分析
3、如何在预训练模型中引入常识知识
4、利用多任务学习生成更加合理的故事


登录查看更多
相关内容
专知会员服务
52+阅读 · 2020年1月20日
专知会员服务
46+阅读 · 2020年1月11日
专知会员服务
26+阅读 · 2019年12月5日
专知会员服务
8+阅读 · 2019年11月15日
专知会员服务
95+阅读 · 2019年11月8日
Arxiv
6+阅读 · 2019年9月27日


相关VIP内容
专知会员服务
52+阅读 · 2020年1月20日
专知会员服务
46+阅读 · 2020年1月11日
专知会员服务
26+阅读 · 2019年12月5日
专知会员服务
8+阅读 · 2019年11月15日
专知会员服务
95+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
6+阅读 · 2019年9月27日