DeepMind提出「SACX」学习范式,训练机器人解决稀疏奖励任务

在本文中,我们提出调度辅助控制(Scheduled Auxiliary Control,SACX),这是强化学习(RL)上下文中一种新型的学习范式。SAC-X能够在存在多个稀疏奖励信号的情况下,从头开始(from scratch)学习复杂行为。为此,智能体配备了一套通用的辅助任务,它试图通过off-policy强化学习同时从中进行学习。实际上,我们方法所蕴涵的关键思想在于,主动(学习)调度和辅助策略的执行,使得智能体能够有效地对其环境进行探索,使其能够在稀疏奖励强化学习中表现突出。我们在若干个具有挑战性的机器人操作环境下进行实验,实验结果证明了我们的方法是非常有效的。

考虑下面的场景:一个学习智能体必须控制一个机器人手臂以打开盒子,并将一个方块放置在其中。尽管为这个任务定义一个奖励是非常简单和直接的,例如,使用诸如力传感器这样的盒子内的简单机制对所放置的方块进行检测,但是潜在的学习问题的解决还是存在一定难度的的。智能体必须能够发现一个长序列的“正确”行为,以便找到产生稀疏奖励的环境配置——即包含在盒子内的方块。可以说,发现这种稀疏的奖励信号是一个非常艰难的探索问题,而想要通过随机探索获得这种成功几乎是不可能的。
智能体在任一配置中对两个方块进行堆叠操作,将红色方块置于绿色方块之上,反之亦然
在过去的几十年里,为了帮助解决上述的探索问题,科学家们已经开发了许多种研究方法。这些方法包括:奖赏塑形(reward shaping)、课程学习(curriculum learning)、从模拟到现实的已学习策略的迁移、从演示中进行的学习、模型指导下的学习以及反向强化学习等。可以这样说,所有这些方法都依赖于特定于任务的先验知识的可用性。除此之外,它们还往往将控制政策偏向某种潜在意义上并不理想的方向。例如,使用由实验者设计的奖赏塑形(shaped reward),不可避免地会偏向智能体所能够找到的解决方案。与此相反,当使用稀疏任务公式时,智能体可以发现全新的、潜在意义上更为优异的解决方案。因此,可以这样说,我们更倾向于开发在学习期间支持智能体的方法,但是保留智能体从稀疏奖励中进行学习的能力。理想情况下,我们的新方法应该减少用于处理稀疏奖励的特定的先验任务知识。
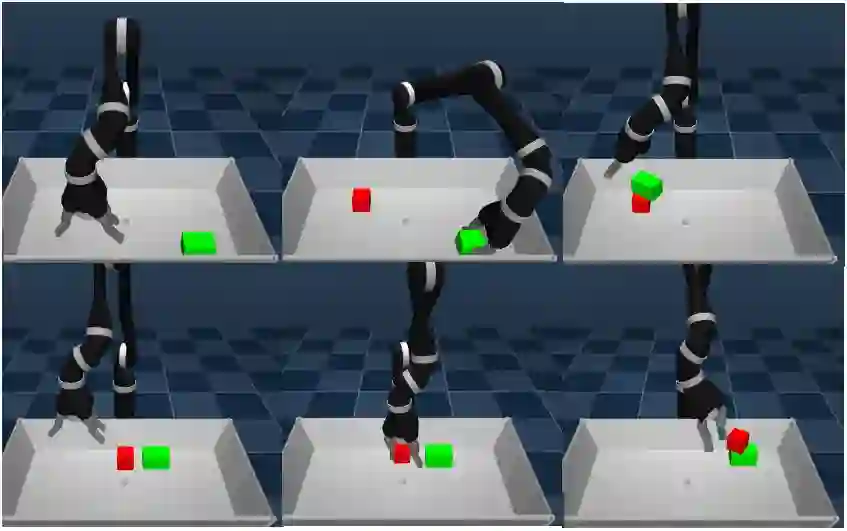
在“清理”任务中智能体操作的描述。图像描绘了将所有物品“放入盒子”意图的最终行为轨迹(从左到右,从上到下)
我们引入了一种称之为调度辅助控制(SAC-X)的新方法,将其作为实现这种方法策略的第一步。它基于四个主要原则:
1.每个状态动作对都与一个奖励向量相配对,由(通常而言是稀疏的)外部提供的奖励和(通常而言是稀疏的)内部辅助奖励组成。
2.每个奖励条目都有一个指定的策略,在下文中称为“意图(intention)”,该策略经过训练以最大化其相应的累积奖励。
3.有一个高级调度程序,它在出于提高智能体对外部任务的性能的目标考虑下,选择个体意图并加以执行。
4.学习是在off-policy过程中执行的(与策略执行异步),意图之间的经验是共享的,以便有效地使用信息。

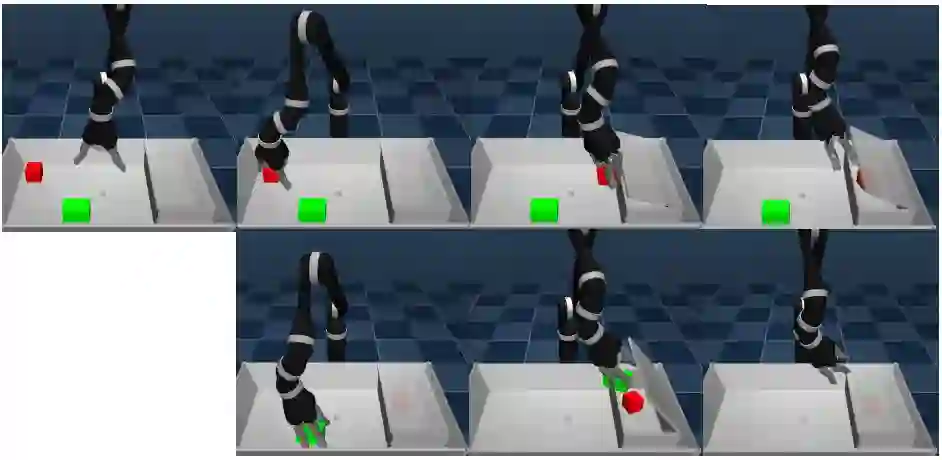
图像序列描绘了在一个真正机器人上训练后的SAC-Q智能体,处理“拿起”(顶部)和“放下”(底部)任务的过程
尽管本文所提出的方法通常来说适用于更为广泛的问题,但我们主要在一个具有稀疏奖励的典型机器人操作应用程序上对我们的方法加以讨论:将各种目标堆叠起来和清理桌子。
这些任务中的辅助奖励是基于智能体对于控制其自身的感官观察(例如图像、本体感受、触觉传感器)的掌握程度而定义的。它们被设计成在一个真实的机器人装置中非常易于实现。特别地,我们在一个原始感官层面上定义了辅助奖励,例如,是否检测到触摸。或者,可选择性地,在一个需要少量实体的预先计算的较高级别上对它们进行定义,例如,是否有任何目标移动,或者在图像平面上是否有两个目标彼此相接近。基于这些基本的辅助任务,智能体必须有效地对其环境进行探索,直到观察到更多有趣的外部奖励。其实,这种方式主要是受到人类在孩童时代玩游戏阶段的启发。

在“清理”任务实验中的期望奖励,SAC-Q能够可靠地对所有四项外在任务进行学习
我们展示了SAC-X在模拟机器人操作任务方面的能力,例如使用机器人手臂进行堆叠和整理桌面。所有任务都是通过稀疏的、易于定义的奖励进行定义的,并使用相同的一组辅助奖励函数加以解决。另外,我们经过试验证明,我们的方法具有样本高效性,从而使得我们能够在一个真实的机器人上从头开始学习。
我们引入SAC-X,一种能够同时在一组辅助任务中学习意图策略的方法,并对这些策略进行积极的调度和执行以探索其观察空间,从而寻找外部定义的目标任务的稀疏奖励。通过使用简单的辅助任务,SAC-X可以从以“纯粹”、稀疏、方式性进行定义的奖励中学习复杂的目标任务:只指定最终目标,而不是解决方案路径。
实验中,通过使用一组常见的简单且稀疏的辅助任务以及一个真实的机器人,我们展示了SAC-X在若干个具有挑战性的机器人模拟任务上的优异表现。所学到的意图是具有高度反应性的、可靠的,并表现出丰富且具有鲁棒性的行为。我们认为,这是实现将强化学习应用到现实世界领域的重要一步。
原文:https://arxiv.org/pdf/1802.10567.pdf
-学习人工智能,挑战百万年薪-

或点击“阅读原文”,查看详情



