遗珠之作?谷歌Quoc Le这篇NLP预训练模型论文值得一看
选自 arXiv
作者:Kevin Clark、Minh-Thang Luong、Christopher D. Manning、Quoc V. Le
机器之心编译
参与:路
在 BERT 论文出现的几周前,斯坦福大学和谷歌大脑合作的一篇同样关于 NLP 预训练模型的论文发布。该研究提出一种新型自训练算法 Cross-View Training (CVT),结合预训练词向量和自训练算法,使用标注数据和无标注数据的混合,从而改善 Bi-LSTM 句子编码器的表征,进而改善整个模型。此外,CVT 与多任务学习结合起来后效果尤为显著。

在大量标注数据上训练的深度学习模型效果最好。但是,数据标注成本很高,这刺激了人们对有效半监督学习技术的需求(半监督学习可以利用无标注样本)。在神经自然语言处理任务中广泛使用且成功的一种半监督学习策略是预训练词向量 (Mikolov et al., 2013)。近期的研究训练 Bi-LSTM 句子编码器去做语言建模,然后将其语境敏感(context-sensitive)表征纳入监督模型中。这种预训练方法先在大型无标注数据语料库上进行无监督表征学习,然后再进行监督训练。
预训练的一个重要缺陷在于表征学习阶段无法利用标注数据——模型尝试学习通用表征而不是针对特定任务的表征。较老的半监督学习算法(如自训练算法)没有这个问题,因为它们在标注和无标注数据上连续学习一项任务。自训练曾对 NLP 非常有效,但该方法较少用于神经模型。而斯坦福大学和谷歌大脑合作的这篇论文展示了一种对神经序列模型也很有效的新型自训练算法——Cross-View Training (CVT)。
在自训练中,模型在标注数据上正常学习,而在无标注数据上则兼任教师和学生:教师对样本作出预测,学生基于预测进行训练。尽管该过程对一些任务有价值,但它略显累赘:模型已经在训练过程中生成预测了。近期的计算机视觉研究解决了这个问题,方法是向学生网络的输入添加噪声,训练一个对输入扰动足够鲁棒的模型。但是,使用噪声对离散输入(如文本)比较困难。
该研究从多视角学习(multiview learning)中获得灵感,训练模型对同一输入的不同视角生成一致的预测结果。CVT 没有将整个模型作为学生模型,而是向模型添加辅助预测模块——将向量表征转换成预测的神经网络,将它们也作为学生来训练。每个学生预测模块的输入是模型中间表征的子集,对应于受限视角的输入样本。例如,用于序列标注的一个辅助预测模块仅关联到模型第一个 Bi-LSTM 层的「前向」(forward)LSTM,因此它在进行预测时看不到当前序列右侧的任何 token。
CVT 的作用在于改善模型的表征学习。辅助预测模块可以从整个模型的预测中学习,因为整个模型具备更好、视角不受限的输入。尽管辅助模块的输入对应受限视角的输入样本,但它们仍然能够学习作出正确的预测,因此能够改进表征的质量。这反过来改善了整个模型,因为它们使用的是同样的表征。简而言之,该方法将在无标注数据上进行表征学习与传统的自训练方法结合了起来。
CVT 可用于多种任务和神经架构,但是本研究主要聚焦于序列建模任务,其预测模块与共享 Bi-LSTM 编码器关联。研究者提出对于序列标注器、基于图的依存句法分析器和序列到序列模型都很有效的辅助预测模块,并在英语依存句法分析、组合范畴语法(CCG)supertagging、命名实体识别、词性标注、文本语块识别(text chunking)和英语-越南语机器翻译任务上对该方法进行了评估。CVT 在所有这些任务上都改进了之前发布的结果。此外,CVT 还可以轻松高效地与多任务学习结合使用:只需在共享 Bi-LSTM 编码器上添加适合不同任务的额外预测模块。训练统一模型来联合执行所有任务(除了机器翻译)可以改善结果(优于多任务 ELMo 模型),同时降低总训练时间。
论文:Semi-Supervised Sequence Modeling with Cross-View Training

论文链接:https://arxiv.org/pdf/1809.08370.pdf
代码地址:https://github.com/tensorflow/models/tree/master/research/cvt_text
摘要:无监督表征学习算法(如 word2vec 和 ELMo)可以提升很多监督式 NLP 模型的准确率,主要原因在于它们可以利用大量无标注文本。而监督模型在主要的训练阶段只能从任务特定的标注数据中学习。因此,我们提出一种半监督学习算法 Cross-View Training (CVT),使用标注数据和无标注数据的混合改善 Bi-LSTM 句子编码器的表征。在标注数据上使用标准的监督学习;在无标注数据上,CVT 教只能看到有限输入(如句子的一个部分)的辅助预测模块将预测结果与能看到完整输入的整个模型的预测结果进行匹配。由于辅助模块和完整模型共享中间表征,因此这会反过来改善完整模型。此外,我们还展示了 CVT 与多任务学习结合起来后效果尤为显著。我们在五个序列标注任务、机器翻译和依存句法分析任务上对 CVT 进行了评估,均达到了当前最优结果。
2 Cross-View Training(CVT)
2.1 方法
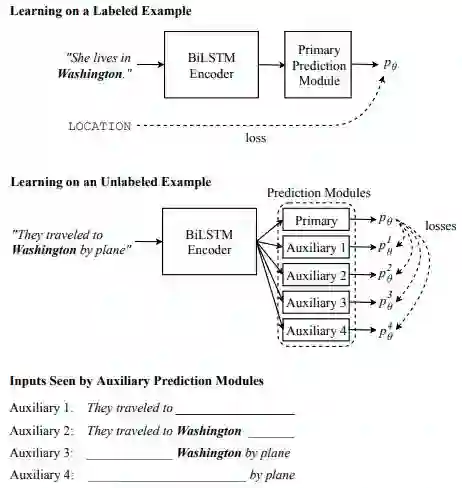
图 1:CVT 方法概览。
2.2 将 CVT 与多任务学习结合起来
在共享 Bi-LSTM 编码器上添加适用于其他任务的额外预测模块即可轻松结合 CVT 与多任务学习。在监督学习阶段,我们随机选择任务,然后使用小批量标注数据更新 Lsup。在无监督学习阶段,我们一次性在所有任务上联合优化 LCVT,首先让所有主要预测模块运行推断,然后让所有辅助预测模块从预测中学习。模型在小批量标注数据和无标注数据上进行交替训练。
多个任务的标注数据对多任务系统的学习很有用,但是大部分数据集只为一个任务而标注。因此多任务 CVT 的一个好处就是模型基于无标注数据创建了适用所有任务的(artificial)标注数据。这显著改善了模型的数据效率、缩短了训练时间。由于运行预测模块计算成本较低,因此计算用于多个任务的 LCVT 并不比单任务模型慢多少。但是,我们发现适用所有任务的标注数据可以大幅加速模型收敛速度。例如,在六个任务上训练的 CVT 模型收敛时间大约是单个任务上模型的平均收敛时间的 3 倍,总训练时间降低了 50%。
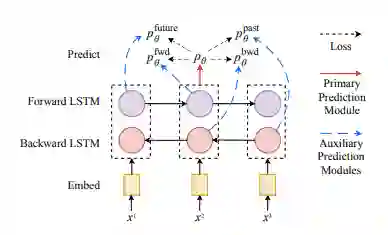
图 2:序列标注模型中的辅助预测模块。每个模块都只看到受限视角的输入。例如,「forward」预测模块在预测当前 token 的标签时看不到它右侧的语境。为简洁起见,这里仅展示了一个层 Bi-LSTM 编码器,以及该模型一个时间步的预测。
4 实验

表 1:在测试集上的结果,所有分数均为 5 次运行的平均值。NER、FGN 和机器翻译任务的分数标准差大约为 0.1,POS 的分数标准差是 0.02,其他任务的分数标准差是 0.05。+Large 模型的隐藏单元数量是其他模型的 4 倍,它的大小与包含 ELMo 的模型差不多。* 表示半监督,† 表示多任务。
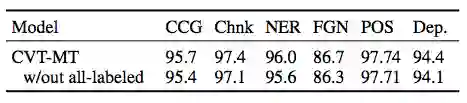
表 2:有/没有适用所有任务的标注数据时,多任务 CVT 的开发集性能。
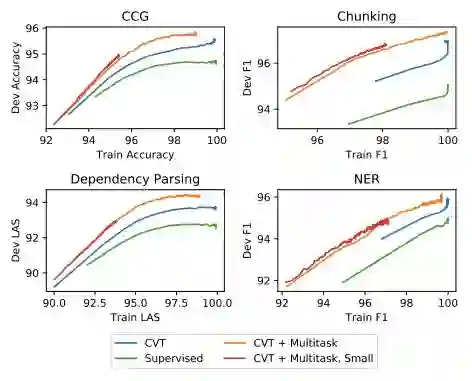
图 4:不同方法的开发集 vs. 训练集准确率。「small」模型的 LSTM 隐藏状态大小是其他模型的 1/4(256 vs. 1024)。
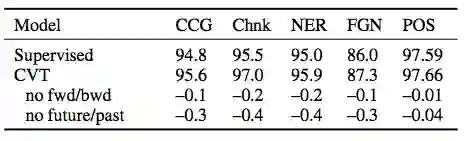
表 3:在序列标注任务上,对辅助预测模块进行模型简化测试(ablation study)。

图 5:左图:模型在开发集上的性能 vs. 模型训练集所占比例。右图:开发集性能 vs. 模型大小。x 轴表示 LSTM 层中隐藏单元的数量,网络中投影层和其他隐藏层的隐藏单元数量是它的一半。点表示三次运行的平均值。
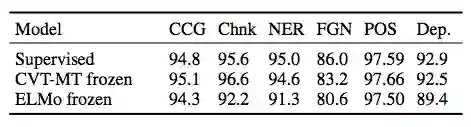
表 4:单任务模型在开发集上的性能对比。CVT-MT frozen 表示我们在五个任务上预训练了 CVT + 多任务模型,然后在第六个任务上仅训练预测模块。ELMo frozen 表示我们基于 ELMo 嵌入训练预测模块(不包括 LSTM)。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



