多元回归理论及R语言实现
点击蓝字关注这个神奇的公众号~

作者:吴数,金融学在读研究生,R语言爱好者
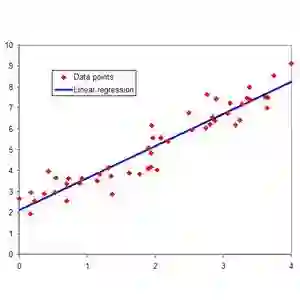
回归分析是研究两个变量之间的不确定性关系,考察变量之间的数量变化规律,通过回归方程的形式描述和反映这种关系,帮助人们挖掘出变量之间隐藏的规律。
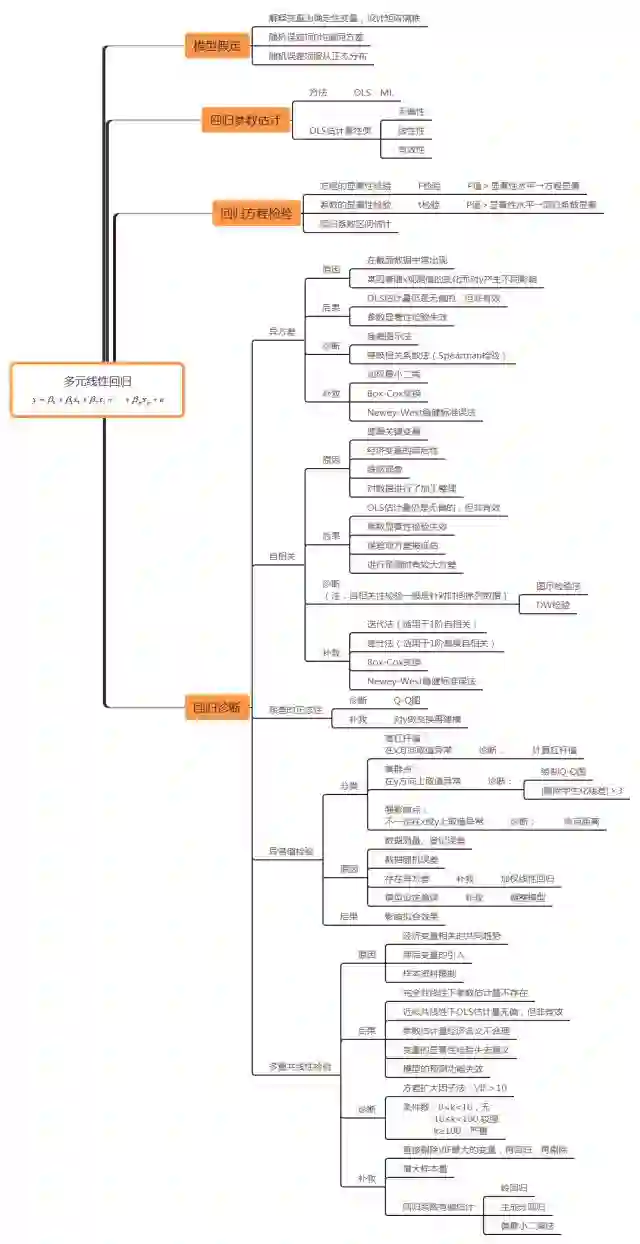
建立回归模型的一般过程为:
1)建立理论回归模型
2)估计模型参数
3)回归模型检验
4)模型诊断
5)利用回归方程进行预测
以下用思维导图展示回归分析的各个过程:
以下是RStudio实现过程:
1、建立模型及显著性检验
首先是载入数据,在此用的是UCI的一个数据集,包含13种汽车车型的相关指标,共398个样本。选可行驶的公里数MPG作为因变量y,排气量displace、马力horsepower、自重weigh为自变量,分别设为x1、x2、x3,各变量均为数值型。
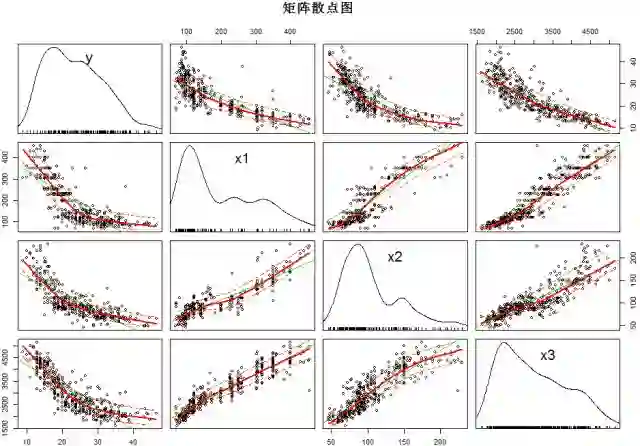
利用car包中的scatterplotMatrix函数绘制矩阵散点图,以便观察自变量与因变量的关系,可以看到,y与各自变量之间呈现出一定的线性关系。
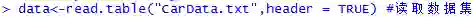
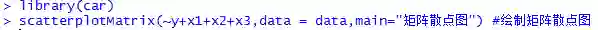
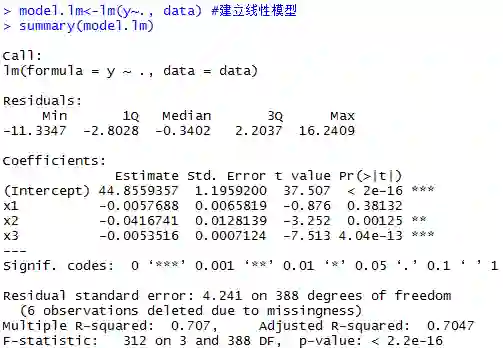
所以下一步建立回归方程,将y对x1、x2、x3三个变量进行多元回归。通过summary函数显示model.lm对象中的详细信息。
可以看到,调整R2为0.704;回归方程显著性的F检验中,P值小于显著性水平α(假设取0.05),表明选择线性模型合理。
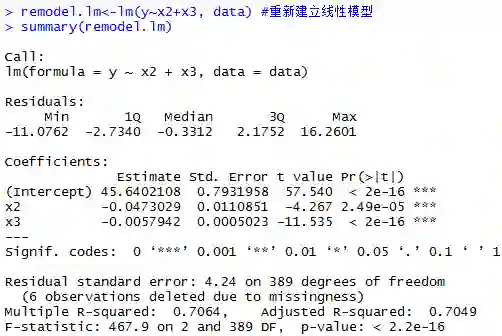
在回归系数显著性检验中,x1不显著,所以把x1直接剔除。再次进行回归,此时调整R2=0.704,回归方程显著,且各回归系数在显著性水平0.001下显著,所以该模型可用。
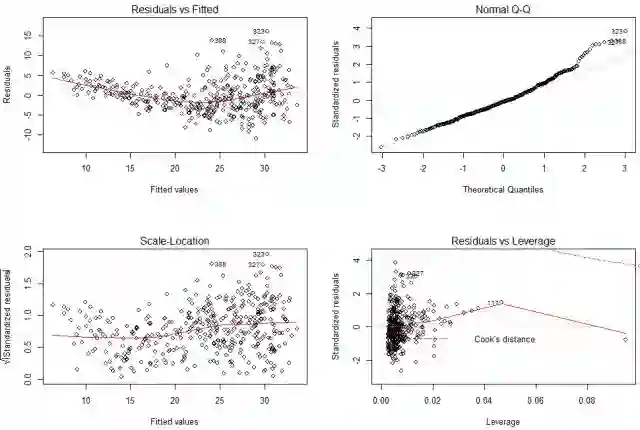
2、回归诊断
(1)残差项的正态性检验和等方差性检验
借助残差图进行,从右上Q-Q图可见,仍有部分残差点有规律地落在对角线之外;从左边两个图可见,误差项的方差随着y的拟合值而变化,尤其在y的拟合值>20之后,残差的方差有所增大。所以可近似地认为不满足残差项的正态性、等方差假定。

基于残差不满足正态性、等方差性,所以对模型进行改进,对y进行对数变换后再回归。
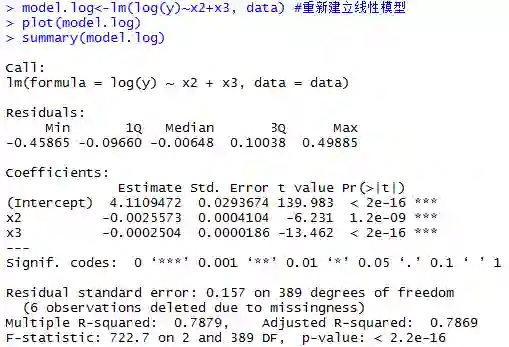
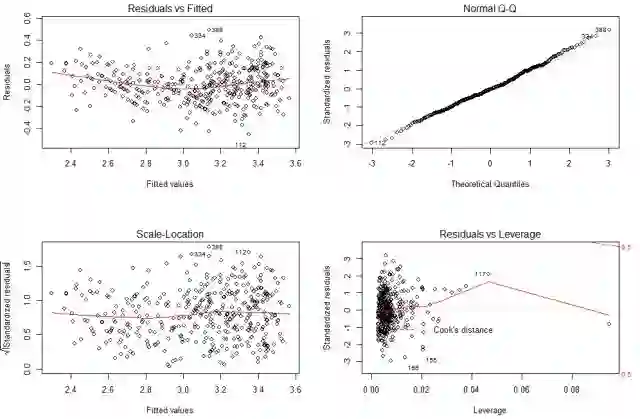
可见残差的正态性、等方差性基本上得到了满足,而且R2比之前的0.7049还大,说明建立对数模型是合理的。
用car包中的ncvTest函数再次检验异方差,P值>0.05所以基本上满足了等方差性。

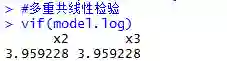
(2)多重共线性检验
从多重共线性检验效果来看,VIF<10,多重共线性还可以容忍。如果存在多重共线性可以直接删除变量,也可以通过岭回归等有偏估计处理。
(3)自相关检验
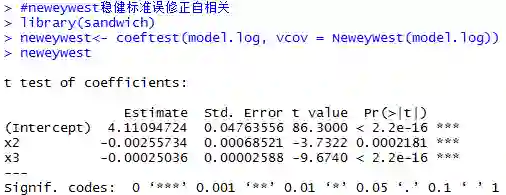
自相关关系主要存在于时间序列数据中,当然截面数据也有可能存在自相关,这种情况通常是由于遗漏了某些重要的解释变量或者模型设定偏误导致的。在截面数据中,对于异方差的处理一般就是添加忽略掉的解释变量或者调整模型,也可以用序列相关稳健标准误修正相应的方差。在时间序列数据中当以上方法不能满足时则需要用一阶差分法、广义差分法、序列相关稳健标准误等。

P值<0.05,说明残差存在自相关性,这里采用尼威-韦斯特稳健标准误修正相应的方差,它能够同时针对异方差、自相关进行修正,这种方法估计出的参数与OLS的相同,只是修正了参数的方差,消除自相关、异方差的存在带来的不良后果。
(4)异常值检测
利用car包中的influencePlot函数可以将各类异常值可视化。横坐标为杠杆值,纵坐标是学生化残差,圆圈大小表示库克距离的大小。可见117号观测点是强影响点,388号为离群点,14号为高杠杆值点。

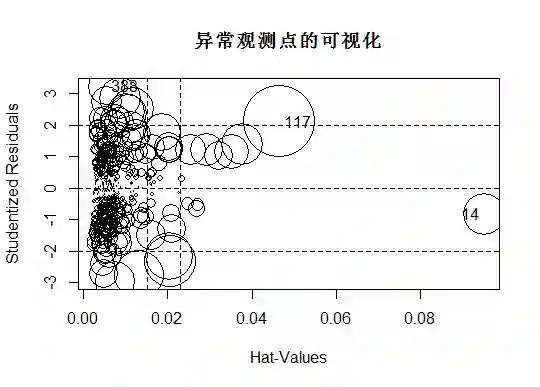
对于强影响点的删除需要谨慎,删除或者包含强影响点都可能会导致回归方程的截距和斜率产生很大的变化。可以先把异常值删除,再重新回归。
至此,最终回归模型已确立:。表示在x3一定的条件下,x2每增加100个单位,y将会减少26个单位。

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享