IJCAI 2019 丨利用半参表示算法缓解推荐系统中的冷启动问题

缓解 I2I 推荐的冷启动问题
作者 | 阿里巴巴
编辑 | Camel
本文是阿里巴巴集团机器智能技术和优酷人工智能平台合作的论文《Hybrid Item-Item Recommendation via Semi-Parametric Embedding》的解读,该论文发表在 IJCAI 2019,本文提出结合商品行为 & 内容信息的半参表示算法 SPE, 旨在结合 collaborative filtering based 和 content-based 算法,以更好地缓解 I2I 推荐的冷启动问题。
1、研究动机
由于常见电商、视频等推荐系统 (淘宝首猜、优酷推荐等) 用户量巨大, 而且用户个性化兴趣差异明显, Item-CF 较于 User-CF 有着天然的巨大优势,它因此被广泛运用于推荐系统中. 常见的 Item-CF 推荐系统中, 服务器收到用户访问请求, 经解析、查询得到用户 profile(包括用户长期画像、历史足迹等) 后,通过 Item2Item、tag 等方式进行候选召回,参与后续排序和后处理。其中 Item2Item(I2I) 是至关重要的一环。
I2I 解决的是针对给定商品 (trigger item),推荐一系列相关商品 (rec_items) 的问题。一方面 I2I 是 feeds 瀑布流等用户推荐场景的基础, 另一方面,「为你推荐」、「猜你喜欢」等场景天然就是 I2I 的问题. I2I 在推荐系统中的作用至关重要。
Behavior-based 的 I2I 矩阵计算通常基于商品之间以往的共同行为 (例如商品被同一个用户浏览点击过), 它在行为充分的商品上通常有较好的推荐效果。然而对很多新品较多的场景和应用上,例如优酷新视频发现场景和闲鱼这种二手电商社区,由于没有历史行为累计,商品的冷启动问题异常严重,behavior-based 算法在这些商品上的效果较差。
冷启动一直以来都是推荐系统重要的挑战之一, 常见的 content-based 方法是引入商品的内容信息,利用商品之间的文本、描述、类目等内容信息进行 I2I 相似度矩阵的计算。然而 content-based 方法涉及到商品的特征工程和相似性度量的选择,需要有相应的领域知识,另外由于非专业卖家、内容作者的积极性和专业能力不够,商品的特征信息也不够丰富甚至有误,content-based 方法的效果差强人意。
因此,本文提出结合商品行为 & 内容信息的半参表示算法 SPE (Semi-Parametric Embedding), 以缓解 I2I 推荐中的冷启动问题。
2、方法
2.1 半参向量表示(SPE)
与CF-based的矩阵分解算法中使用行为信息建模商品向量的做法不同, 本文同时使用行为和内容信息来建模商品表示, 也即
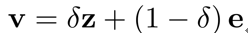
其中, v 为商品的向量表示; z 为商品的行为信息表示部分, 每个商品的行为表示各自不同; e 为内容信息表示部分, 通过特征输入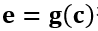
行为向量 z 和内容向量 e 分别为模型中非参数化向量和参数化向量, 结合两者,作者将其称作半参向量表示。
2.2 SPE 用于I2I 推荐
本文将半参向量表示应用于 I2I 推荐中, 基于商品的向量表示, 定义相似性度量为
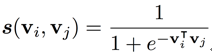
则可以通过最小化如下目标函数求解
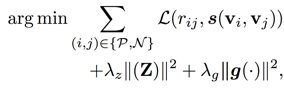
其中, g 为非线性激活函数的多层感知机, 后两项为正则化子。
2.3 多层降噪自动编码机
由于非专业卖家、非专业 UPGC 作者的积极性和专业能力不够, item 的内容特征信息不够丰富甚至缺失、错误。本文针对参数化向量表示,引入了深度学习中的多层降噪自动编码机(stacked denoise autoencoder, sDAE), 以学习更鲁棒的内容向量表示。则目标函数更新为:
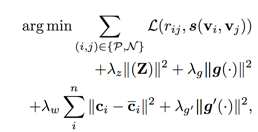
其中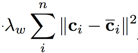
3、实验
在实验部分,论文中共选取了2个 benchmark 和阿里二手交易平台的真实数据集,分别将半参向量表示框架与 cf-based, content-based, hybrid 方法进行了比较, 选取的指标为 in-matrix(item 在训练集中出现过)和 out-of-matrix(item在训练集中未出现过)数据集上的HitRatio@10 和 NDCG@10。详细结果如下,
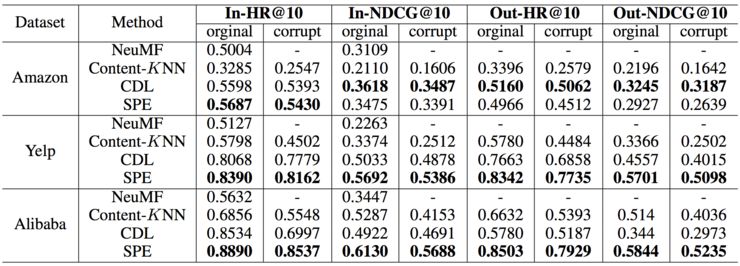
此外,实验中对 SPE 和SPE-sDAE的鲁棒性进行了对比, 论文通过对Amazon数据集中的内容特征进行随机扰动(非零值以corrupt-ratio的概率进行置零)得到不同版本的噪音数据集,
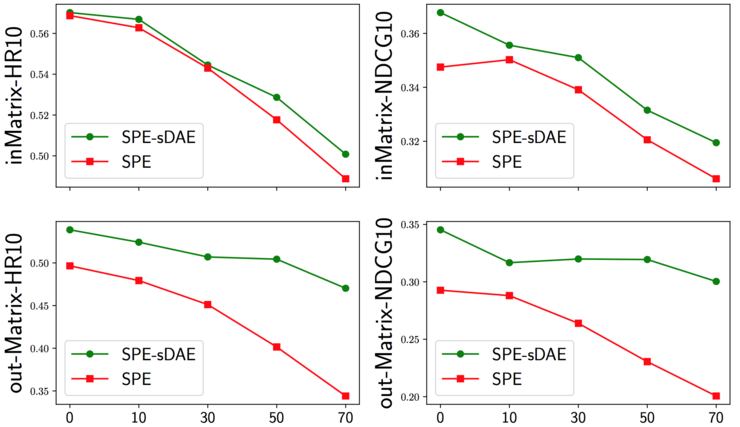
由图可见,随着扰动比率的增大,两者的指标都在下跌,但是SPE-sDAE比SPE更鲁棒,特别是在out-of-matrix的数据集上的优势更明显。
4、总结
本文提出了一种半参表示框架, 它结合商品的行为信息和内容信息,以达到在维持行为丰富 item 上表现的同时,缓解新发商品上的冷启动问题。另外本文引入 sDAE 来帮助学习更强力的内容表示,以达到更鲁棒的效果。3 个真实数据集、3类对比推荐算法、4 种评价指标上的对比实验,验证了该算法的可靠性和鲁棒性。
参考文献:
[1] BadrulSarwar, GeorgeKarypis, Joseph Konstan, and John Riedl. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, pages 285–295, 2001
[2] Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. Computer, 42(8), 2009
[3] Yue Shi, Martha Larson, and Alan Hanjalic. Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Computing Surveys, 47(1):3, 2014
[4] Hao Wang, Naiyan Wang, and DitYan Yeung. Collaborative deep learning for recommender systems. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1235–1244, 2015


AI研习社独家推出「顶会赞助计划」,为AI学术青年和开发者助力
点击下方 阅读原文 查看详情





