Azure“升维”之道:微软亚洲研究院提供智能原力
编者按:伴随着微软亚洲研究院数据、知识、智能组与微软云产品团队的深度合作,一系列创新技术已经在云系统的故障预测、异常检测、智能诊断、容量规划、事故管理等诸多实际应用场景中落地,相关研究成果也在 ICSE、NSDI、USENIX ATC、WWW、AAAI、ICDM 等高影响力的会议中发表, 极大地提升了服务质量、用户体验和工业生产力。
最近,各个行业已陆续复工,相信对诸多企业和个人来说,和这场疫情同样猝不及防的还有生产、生活方式的改变。随着协同合作、远程办公、在线教育等场景被迅速催熟,在将来复盘之时,“科技文明”一定会占据浓墨重彩的篇幅。而在这些场景下,我们的基础设施是否已经准备好应对未来的变革呢?
Gartner 研究副总裁 Sid Nag 认为云已经成为主流策略:“下一代的产品方案,几乎都是搭建于云平台上的。”2020年将有更多应用服务转向云端,5G 也将为云计算的发展带来可预见的新高峰。但随着越来越多的用户上云,系统的管理正面临着前所未有的挑战。海量用户、大规模集群、复杂的系统架构使传统的运维方式力不从心。如何实时检测异常、快速响应故障、合理规划容量等问题已成为重要课题。
在炙手可热的人工智能领域,数据驱动、AI 赋能的微软云始终以理性而乐观的姿态立足于全球云服务市场。数据为微软云的管理提供了新的维度——数据智能。伴随着微软亚洲研究院数据、知识、智能组与微软云产品团队的深度合作,一系列创新技术已经在云系统的故障预测、异常检测、智能诊断、容量规划、事故管理等诸多实际应用场景中落地,相关研究成果也在 ICSE、NSDI、USENIX ATC、WWW、AAAI、ICDM 等高影响力会议中发表, 极大地提升了服务质量、用户体验和工业生产力。本文将概述研究团队在服务智能各个场景上的研究成果。

图1:智能云服务的愿景
为了保证云平台的高可靠性和高可用性,实时检测可能的系统异常尤为重要。大规模系统的异常检测主要通过监控平台的各种运行状态数据来实现,如性能指标数据(访问成功率、响应速度、CPU 使用率、内存占用率),系统事件,系统日志等,从数据窥探系统的健康状况。研究团队在时序数据和日志数据上进行了异常检测的研究。
基于时序数据的异常检测- ATAD
在基于时序数据的异常检测中,传统方法一般分为基于规则的模型、无监督模型和有监督模型。其中有监督模型因为有标注信息的指导,可以很好地针对异常信号建模,使得误报率大大降低,效果远优于其它两类方法。然而,鉴于大规模云系统中,各种监控信号的数据量庞大,模式漂变迅速、多样性强等特点,构造基于标注数据的有监督异常检测模型并非易事。因此,研究团队提出了一种基于迁移学习和主动学习的跨数据集的时间序列异常检测框架。首先,针对时间序列数据,我们提取了一系列时间顺序相关的特征以反映时间序列的特点;而后,使用无监督领域自适应的迁移学习技术,将在源域学习到的知识迁移到目标域当中。最终,为了进一步弥合源域和目标域之间的差距,我们专门设计了一种基于不确定性和时间上下文多样性的主动学习技术,推荐极少量的待标注样本交由领域专家进行标注,从而使得模型效果获得极大的提升。通过实验证明,我们的方法可以有效地在不同时间序列数据集之间进行迁移,并且只需要1%-5%的标注样本量即可达到很高的检测精度。相关研究发表在系统领域顶级会议 USENIX ATC 2019 [1]。
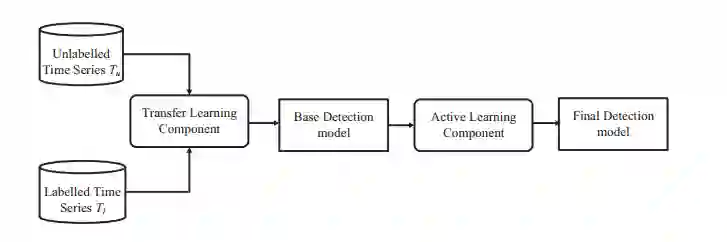
图2: ATAD
基于日志数据的异常检测 – LogRobust
当前,Log 数据在大型软件系统的故障诊断、问题定位、异常检测等诸多任务中,发挥着不可替代的作用。运维人员和开发工程师通过 log 数据可以查看并理解系统的运行状态、探测到系统出现的故障并定位其根因所在。迄今为止,已有大量的研究工作在集中讨论如何使用 log 数据进行系统的异常检测,并取得了显著进展。然而,在实际应用中,这些方法却并不能很好地适应工业场景的需要,其根本原因在于大部分的同类方法均以静态假设为基本前提,即 log 数据是稳定的,不会随时间变化而变化。因此,此类方法一般直接将训练集中的 log 数据统一以事件表示建模,并直接应用到待测试的数据上。但是,研究团队发现 log 数据在实际场景中并不稳定,log 会随着源代码的修改、更新、增加、删除而持续变化;另外,在 log 数据预处理和收集的过程中,也会引入大量的不确定噪声。因此,在固定数据上训练得到的检测模型,往往不能很好地在测试数据上泛化。
研究团队提出了一种基于深度学习技术的 log 异常检测模型,使用预训练的词向量在词级别对 log 进行表示,而不是在事件级别表示,可以有效克服 log 中词级别变动导致的不稳定问题。同时,使用 tf-idf 对不同的词进行加权,以突出重要的单词信息。之后,我们使用长短期记忆神经网络(LSTM)训练异常检测模型,并引入注意力机制,使得模型可以更好地学习到不同 log 之间不同的重要性,以克服 log 序列级别的不稳定问题。实验证明,LogRobust 可以比传统方法更好地适应工业中的实际场景,在快速漂变的实际工业数据中取得了出众的效果。 该研究发表在软件工程领域顶级会议 FSE 2019 [2]。
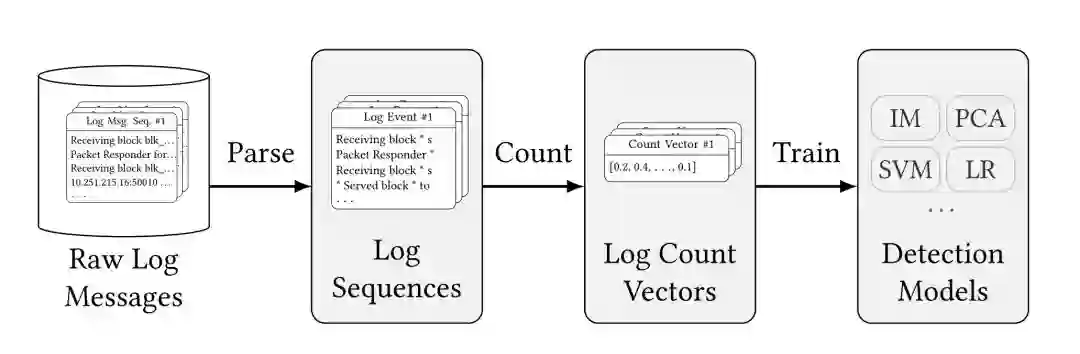
图3:LogRobust
当检测出系统异常或发生故障时,快速有效的诊断是正确修复系统的第一步。各种各样的故障状况频出令工程师们心力交瘁,如何利用系统数据自动定位可能的故障原因、缩小问题空间是系统维护的重点,也是研究领域的难点。
时空相关性分析
诊断的关键切入点是寻找相关性。在大规模的云系统中做故障诊断面临着巨大挑战。故障情形多种多样,系统结构复杂,应用服务之间相互关联,这些使得故障原因扑朔迷离,简单的关联判断在实际生产场景中容易导致归因错误。为此,研究团队和产品部门合作,提出了时空相关性模型,通过在时间和空间的双重维度上对比故障前后的系统状态,为故障诊断提供线索。该模型在安全部署这一应用场景中取得很高的准确率,相关研究发表在系统和网络领域顶级会议 NSDI 2020 [3]。
因果相关性分析
研究团队在大规模服务中断的诊断上也有新的研究成果。云平台上同时分布着多个服务,比如数据流、存储流等,小的服务故障常常累积而形成大规模中断(Outage),大大降低系统可用性并影响用户体验。大型系统如 Azure 包含许多子系统(即服务),每个子系统由许多相互关联的组件和服务组成。每个组件或服务都有自己的监控方式,可以定期收集检查组件的运行状态的信号。
大部分针对大型复杂系统(如数据中心、网格系统和防御系统)中诊断故障的方法只考虑单个系统,而忽略了可能对结果产生影响的相关系统。研究团队提出要关注大型系统中各个组件存在的关联性,以及关联性对故障检测与修复问题的帮助。针对组件和服务关联性问题,我们借助因果分析方法 FCI 中的条件独立检验确定各个组件或服务收集的时域信号是否存在相关性。通过因果分析时域信号的关联性,将不同层次之间的组件信号和服务信号进行关联性构建,得到组件和服务的关联图,进而定位大规模中断的可能原因。下图展示了该服务中断的诊断过程,模型指出数据流服务最相关的服务主要是存储流服务和存储故障诊断(Storage trouble guide)服务。而实践中该大规模服务中断确实为存储流服务故障导致,也验证了模型的准确性。 相关技术作为短文发表在计算机顶级会议 WWW 2019 [4]。
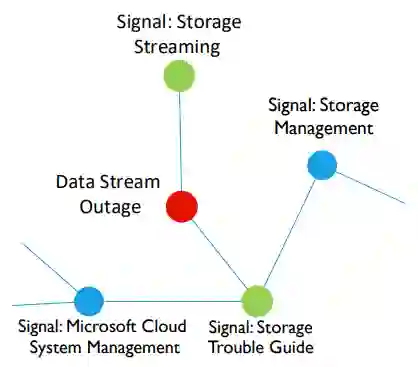
图4:Data Stream 大规模服务中断诊断
在故障发生之前,提前预测以避免可能的损失是智能服务的杀手锏。2018年,研究团队发表了磁盘故障预测[5]和节点故障预测[6] 两项研究成果,2019年在大规模服务故障预测上又有新的突破[4]。
硬盘故障预测
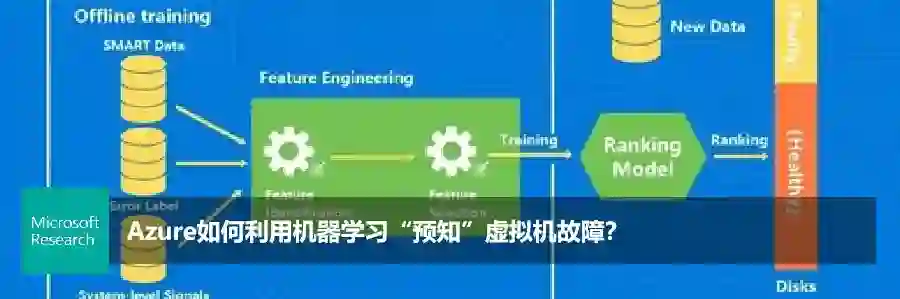
据统计,云系统出现故障的主要原因之一是硬件故障,而硬盘故障是最影响用户的硬件故障之一。在现有的硬盘故障预测的研究中,现有方法抽象为故障与否的二分类问题,采集磁盘监控的 SMART 数据,使用分类模型(如随机森林、SVM)做预测,并取得了相当好的实验效果。但在实际生产环境中,这些“实验室成果”黯然失色。首先,硬盘故障可以看作一种“灰色故障”,也就是说在硬盘彻底无法使用之前,其上层应用已经受到影响,单纯依靠磁盘自身数据无法即时预测。其次,极度不平衡的正负样本为在线预测带来了极大的挑战。健康节点(磁盘)被标记为负样本,故障节点(磁盘)为正样本,在磁盘故障预测中,Azure 每日的故障磁盘与健康磁盘的比例大约3: 100,000,预测结果会倾向于把所有磁盘都预测为健康,带来极低的召回率。再者,在实际生产环境中,将一个健康样本预测成故障与将故障样本预测为健康带来的应对成本并不同,需要将这些成本考虑进去。
为此,研究团队综合考虑硬盘 SMART 数据和系统级信号,提出了一种基于排序思想的机器学习模型。该模型已经应用在 Azure 中,相关研究发表在 USENIX ATC 2018[5].
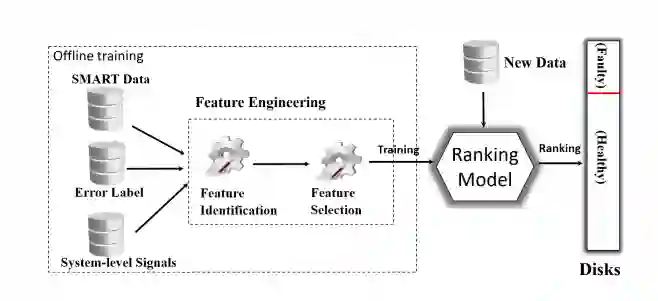
图5:Azure 云硬盘错误预测系统框架
大规模服务故障预测
为了最大程度的避免大规模服务中断 (outage) ,减少服务停机时间,确保云服务的高可用性,研究团队开发了一种智能的大规模中断预警机制 AirAlert,可以在云服务大规模中断发生前预测中断的发生。AirAlert 收集整个云系统中的所有系统监控信号(monitor signals),检测监控信号之间的依赖性并动态预测整个云系统中任何地方发生的大规模中断,使用鲁棒梯度提升树(robust gradient boosting tree)技术预测潜在的大规模中断。研究团队在微软云系统收集了超过1年的服务中断数据,并在数据集上验证了该方法的有效性。
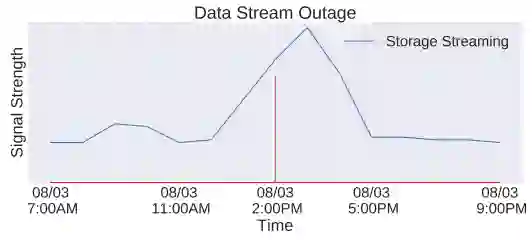
图6: Data Stream 大规模服务中断预测
上图展示了一个预测大规模服务中断的例子,从图中可以看到,在数据流(Data stream)服务出现大规模中断前,其相关的存储流(Storage streaming)服务监控信号已经发生异常。该方法可以捕获这样的异常,并对数据流服务中断进行预警。
容量规划 —— 一种预测导向框架
正如物资管理之于抗击疫情的关键性,有效的容量规划是保障云服务高可用性的重要课题。虽然软件系统开发通常采用明确的规则和启发式方法,但机器学习一直在推动现代系统设计的革命。在容量规划问题中,研究团队提出一种新的预测导向(Prediction-guided)框架,它利用机器学习技术来支持系统本身的决策。在此设计中,系统不仅由各种类型的数据(例如系统平台操作与事件、工作负载、用户行为等)自动驱动,而且带来了“预先”的观念。因此,一些重大问题可以在变成灾难之前被阻止。
预测导向框架具有三个关键词:数据(data)、系统状态(status)、操作(action)。机器学习模型利用数据预测未来的系统状态,系统根据预测的状态触发决策,进而采取相应的操作。该框架极具扩展性,对于不同的业务场景,只需确定以下问题:
1. 预期的操作有哪些?
2. 哪种系统状态可以区分这些操作?
3. 哪些数据与系统状态有关?
例如,容量缓冲管理(buffer management)对任何公共云提供商都至关重要。然而,传统方法主要是基于对集群(cluster)中硬件/软件故障概率的统计。无论集群中部署的工作负载如何,对大小和属性相似的集群都会使用相同的策略。为了保证所有集群都有足够的容量,策略必须为最坏的情况做好准备。然而,这种管理方法会导致大量集群保留过多的缓冲容量,导致低利用率和高销售成本(COGS)。
为了解决这个问题,我们基于预测导向框架设计了一种智能缓冲区管理方法,根据不同集群的工作负载,动态地调整预留缓冲区,来实现以足够的缓冲区避免故障和最小化过剩容量之间的最佳平衡。该系统的核心是一个基于机器学习的预测引擎,它监控集群已经部署的工作负载和平台事件(数据),预测这些部署在未来将导致多少容量增长需求(状态)。接纳控制器将预测的需求增长作为输入,并对是否允许新部署虚拟机放置到集群中做出二元决策(操作)。具体而言,在预测需求较高的集群中,接纳控制器会更早地拒绝新的虚拟机部署,从而保证更多容量被预留用于集群中现有客户的增长。在预测需求较低的集群中,接纳控制器会允许新的工作负载进入集群。该系统已集成到微软 Azure 云平台中,不仅显著提高了容量配置的可靠性,还为公司减少了大量的成本支出。 相关成果即将发表在 AAAI 2020 Workshop [7] 。
在线服务系统运行期间,意料外的服务中断或降级(称为故障 Incident) 是很难避免的,这些故障可能会造成重大的经济损失和客户满意度下降。 在故障管理中,首先需要将故障报告分配给合适的团队,使受影响的服务得到快速恢复。 我们将此步骤称为故障分派(Incident Triage),这一环节显著影响故障解决的效率。

图7:事故管理
为了更好地了解业界对故障分派的尝试和实践,研究团队基于微软20个大型在线服务系统展开实例研究,发现故障分派不正确的情况时有发生,这导致了大量不必要的成本,特别是严重程度较高的故障。例如,我们发现针对不同的在线服务,其中4.11%至91.58%的故障报告经过了多次分配,由于错误分配而导致的时间开销是正确分配的10倍左右 [8]。
由于故障分派与软件错误分派(自动将软件 bug 报告分配给软件开发人员)有一定相似性,所以我们将典型的错误分派技术应用到在线服务故障分派中。结果表明,这些错误分派技术在一定程度上能够正确地将事件报告分配给对应的团队,但仍需进一步改进。
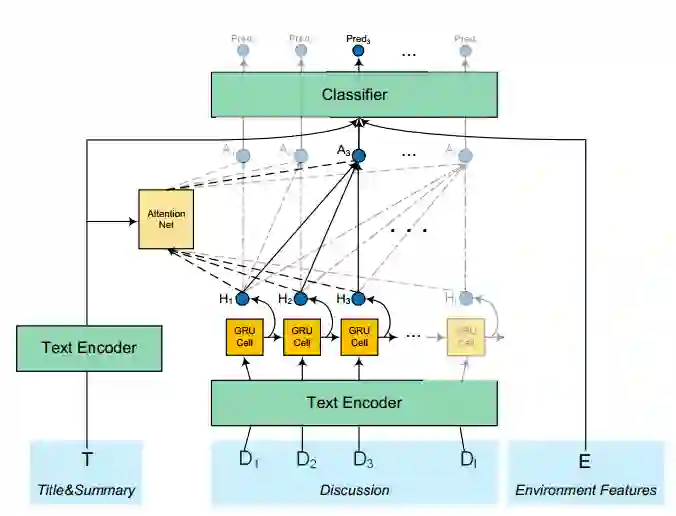
图8:DeepCT
在实例研究中我们还发现,故障分派不是一个单次事件,而是一个连续的过程,在这个过程中,不同团队的工程师不断进行深入的讨论,完善对故障的理解,直到将故障分配给正确的团队。基于这种观察,我们提出一种基于深度学习的自动化连续故障分派算法 DeepCT 。DeepCT 结合了一个新的基于 attention 的屏蔽策略、门控循环单元模型(GRU)和改进版的损失函数,可以从工程师对问题的讨论中逐步积累知识并更新分派结果。DeepCT 可以通过少量的讨论数据来实现正确的故障分派。我们对 DeepCT 进行了广泛而深入的评估,结果显示 DeepCT 能够实现更准确、更高效的故障分派,故障分派的平均准确度可以提高到0.729(在考虑5条讨论数据的前提下)。DeepCT 的算法细节发表在 ASE 2019 [9]。
打日志是记录系统运行相关信息的关键方法,日志数据是检测和诊断系统问题的重要资源。由于系统规模大、复杂性高,微软的一个服务系统每天会产生 TB 级别的日志数据,一旦出现问题,传统的关键词检索方式相当低效。日志数据的类型多样性和半结构化特点也给分析带来了挑战。研究团队一直活跃在大规模日志研究的前沿, 在日志收集、日志处理、日志分析方面均有丰富的研究成果,如低成本高效率的日志记录方法[11],基于日志聚类的系统异常识别[12],日志与其他监控数据的关联性分析[13],日志的上下文分析及程序执行流程抽取[14] 等,研究细节请参考论文。
在解决云系统实际问题的同时,我们的研究也推动了人工智能领域的发展。在云系统场景下的机器学习任务中,特征工程是模型有效性的关键,也是开发有效机器学习模型的核心步骤。传统上,特征工程是手动执行的,这不仅需要实践者拥有大量领域知识,而且非常耗时。最近,学术界提出了许多自动特征工程(Automated Feature Engineering)方法。这些方法通过将原始特征自动转换为一组新特征来提升机器学习模型的性能。在实践中,自动特征工程是对自动机器学习(Automated Machine Learning)的补充。然而,现有的自动特征工程方法存在特征空间爆炸的问题,这使得其实际性能停滞不前。为了应对这一技术挑战,我们提出了神经特征搜索(Neural Feature Search,NFS),一种基于新型神经架构的自动特征工程方法。NFS 利用基于递归神经网络的控制器,通过最有潜力的变换规则(Transformation Rule)来变换每个原始特征。该控制器通过强化学习进行训练,以最大化机器学习模型的预期性能。实验表明,在大量公共数据集上,NFS 优于现有的最先进的自动特征工程方法。NFS 已在 ICDM 2019 发表[10],在自动特征工程研究领域确立了新的技术水平。
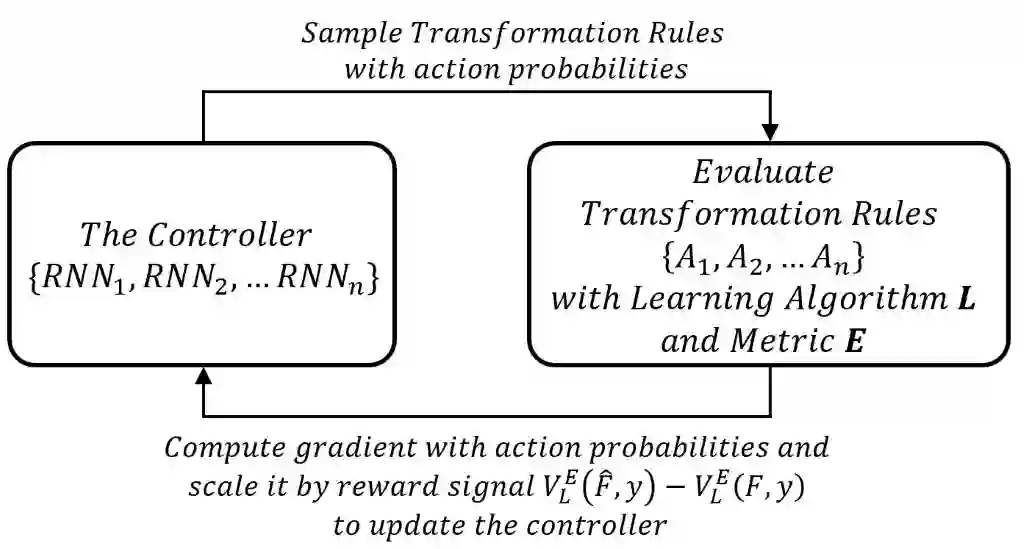
图9:NSF
在服务智能领域,复杂的系统和纷繁的应用场景带来了错综复杂的研究问题,而这种复杂性也正是它吸引研究者和工程师的地方。未来,微软亚洲研究院数据、知识、智能组将继续保持对问题的好奇、对数据的敏感和对技术创新的热忱,与大家分享在该领域中的全新突破。
参考文献
[1] Cross-dataset Time Series Anomaly Detection for Cloud Systems
https://www.microsoft.com/en-us/research/publication/cross-dataset-time-series-anomaly-detection-for-cloud-systems/
[2] Robust Log-based Anomaly Detection on Unstable Log Data
https://www.microsoft.com/en-us/research/publication/robust-log-based-anomaly-detection-on-unstable-log-data/
[3] An Intelligent, End-To-End Analytics Service for Safe Deployment in Large-Scale Cloud Infrastructure
https://www.microsoft.com/en-us/research/publication/an-intelligent-end-to-end-analytics-service-for-safe-deployment-in-large-scale-cloud-infrastructure/
[4] Outage Prediction and Diagnosis for Cloud Service Systems
https://www.microsoft.com/en-us/research/publication/outage-prediction-and-diagnosis-for-cloud-service-systems/
[5] Improving Service Availability of Cloud Systems by Predicting Disk Error
https://www.microsoft.com/en-us/research/publication/improving-service-availability-cloud-systems-predicting-disk-error/
[6] Predicting Node Failure in Cloud Service Systems
https://www.microsoft.com/en-us/research/publication/predicting-node-failure-in-cloud-service-systems/
[7] Prediction-Guided Design for Software Systems
https://www.microsoft.com/en-us/research/publication/prediction-guided-design-for-software-systems/
[8] https://www.microsoft.com/en-us/research/publication/an-empirical-investigation-of-incident-triage-for-online-service-systems/
https://www.microsoft.com/en-us/research/publication/an-empirical-investigation-of-incident-triage-for-online-service-systems/
[9] Continuous Incident Triage for Large-Scale Online Service Systems
https://www.microsoft.com/en-us/research/publication/continuous-incident-triage-for-large-scale-online-service-systems/
[10] Neural Feature Search: A Neural Architecture for Automated Feature Engineering
https://www.microsoft.com/en-us/research/publication/neural-feature-search-a-neural-architecture-for-automated-feature-engineering/
[11] Log2: A Cost-Aware Logging Mechanism for Performance Diagnosis
https://www.microsoft.com/en-us/research/publication/log2-cost-aware-logging-mechanism-performance-diagnosis-2/
[12] Log Clustering based Problem Identification for Online Service Systems
https://www.microsoft.com/en-us/research/publication/log-clustering-based-problem-identification-online-service-systems-2/
[13] Identifying Impactful Service System Problems via Log Analysis
https://www.microsoft.com/en-us/research/publication/identifying-impactful-service-system-problems-via-log-analysis/
[14] Contextual Analysis of Program Logs for Understanding System Behaviors
https://www.microsoft.com/en-us/research/publication/contextual-analysis-program-logs-understanding-system-behaviors-2-2/
你也许还想看: