TensorFlow Lite 新功能亮相 TF DevSummit ‘20
文 / TensorFlow Lite 团队

随着边缘设备(例如智能手机)算力的逐年增强,越来越多的设备端机器学习 (on-device ML) 应用案例得以实现。TensorFlow Lite 是在边缘设备上运行 TensorFlow 模型推理的官方框架。如今它运行在全球超过 40 亿台活跃设备上,而且是跨平台运行,包括 Android、iOS 以及基于 Linux 的 IoT 设备和微控制器。
我们持续改进 TensorFlow Lite,不断突破设备端机器学习的限制,向开发者提供更快捷、更易用的机器学习框架。在本文中,我们将重点介绍 TensorFlow Lite 的最新功能,这些新功能均是在近半年内(TensorFlow DevSummit 前)开发完成的。
中文字幕 | TensorFlow Lite:移动端和智能设备中的机器学习
突破设备端机器学习的局限
启用最前沿的 (SOTA) 模型
机器学习是一个飞速发展的领域,每隔几个月就会有新的模型出现并刷新最新记录。我们知道您希望自己的机器学习功能快人一步,因此我们付出了很多努力确保 SOTA 模型在 TensorFlow Lite 上运行良好。最近,我们增加了对 EfficientNet-Lite(图像分类模型系列),MobileBERT 和 ALBERT-Lite(支持多种 NLP 任务的轻量级版本 BERT)的支持。
MobileBERT
https://tfhub.dev/tensorflow/mobilebert/1ALBERT-Lite
https://tfhub.dev/s?deployment-format=lite&q=albert
EfficientNet-Lite
EfficientNet-Lite 是一种新颖的图像分类模型,可通过减少计算和参数的数量级来实现 SOTA 的准确性。它针对 TensorFlow Lite 量化方式进行了优化,在损失较低精度(几乎可忽略)的同时大大提升了推理速度,并可以运行在CPU、GPU 和 EdgeTPU 上。您可以在我们的这篇 文章 中了解更多的相关信息。
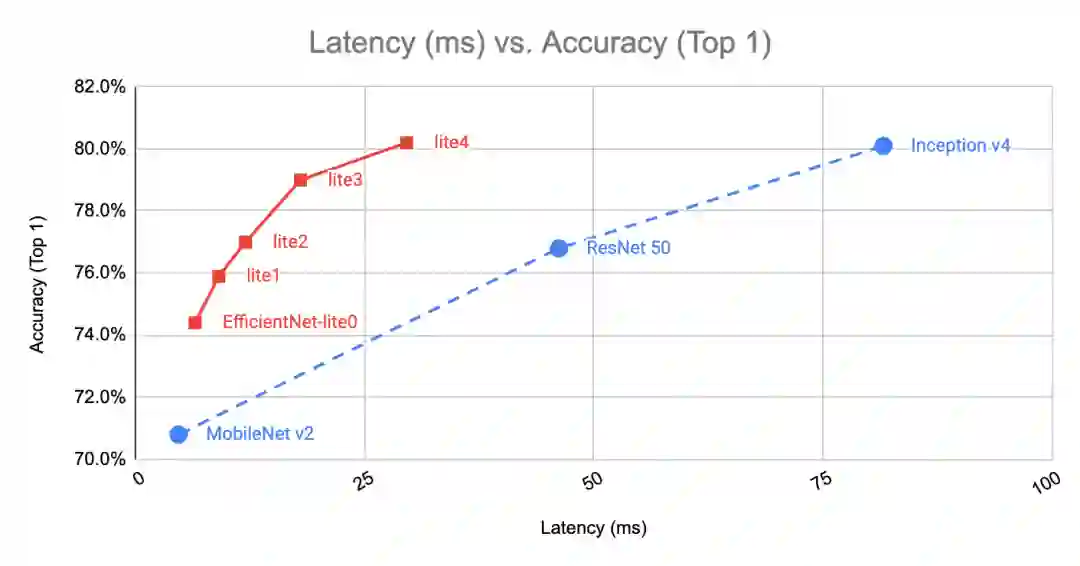
MobileBERT 和 ALBERT-Lite
MobileBERT 和 ALBERT-Lite 是流行的 BERT 模型的优化版本,该模型在一系列 NLP 任务(包括 问答 (QA),自然语言推断等)上均达到了 SOTA 的准确度。
MobileBERT 的体积是 BERT 的 1/4,速度是 BERT 的 4 倍,同时保持了相近的准确度。
ALBERT-Lite 的体积甚至更小,仅有 BERT 的 1/6,也就是 MobileBERT 体积的 2/3,在速度上 ALBERT-Lite 稍逊于 MobileBERT。
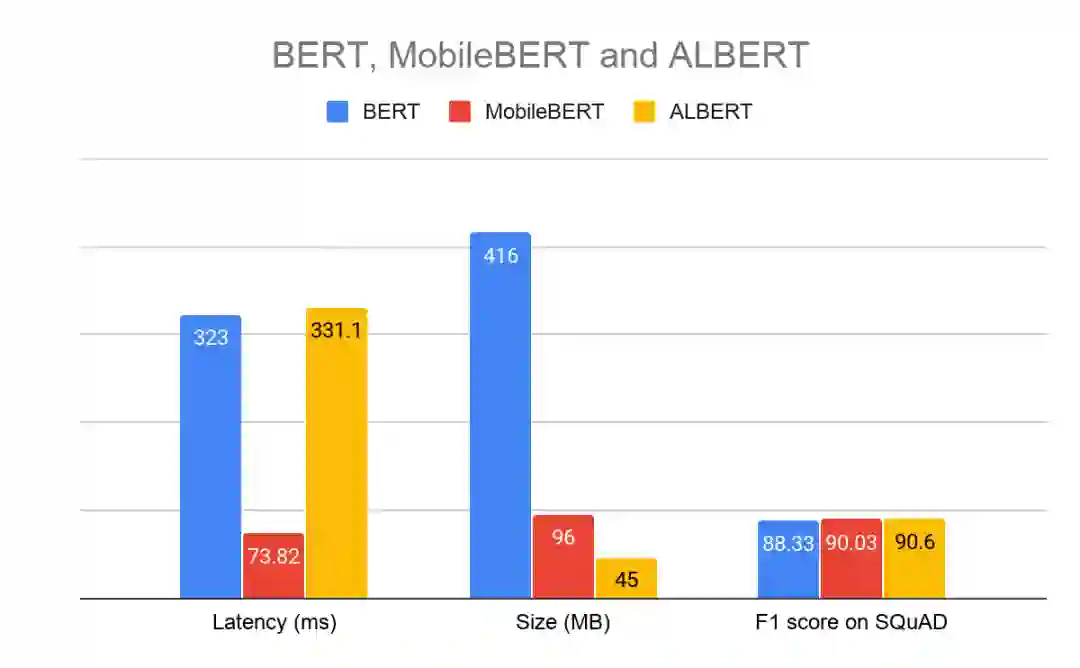
在 Pixel 4 CPU 上以四线程运行的 Float32 问答模型
新的 TensorFlow Lite 转换器
-
支持新类型的模型进行转换,如 DeepSpeech V2,Mask R-CNN,MobileBERT,MobileNetSSD 等等 -
增加了对功能控制流 (Functional Control Flow) 的支持(在 TensorFlow 2.X 中默认启用) -
在转换过程中跟踪原始 TensorFlow 节点名称和 Python 代码,用于在转换发生错误时显示它们 应用 Google 的最先进的 ML 编译器技术 MLIR ,扩展功能需求时更轻松
-
MLIR
https://github.com/tensorflow/mlir
新的转换器完全向下兼容,并且将在 TensorFlow 2.2 中默认启用 ,而旧的转换器仍然可以通过参数启用。更多详细信息请参见此 文档 。
文档
https://tensorflow.google.cn/lite/convert#new_in_tf_22
支持 Keras 模型的训练时量化
训练时量化 (QAT,Quantization-aware training) 使您可以利用量化的高性能和小体积的优势来训练和部署模型,同时保持接近量化前的准确度。我们刚刚推出了对 Keras 模型的 QAT 支持。仅需一行代码,您即可将 QAT 添加到模型中。
import tensorflow_model_optimization as tfmot
model = tf.keras.Sequential([
...
])
# Quantize the entire model.
quantized_model = tfmot.quantization.keras.quantize_model(model)
# Continue with training as usual.
quantized_model.compile(...)
quantized_model.fit(...)
QAT 可使模型大小缩小为原来的 1/4,运行速度更快,同时保持原有准确度。下表是 QAT 与原始浮点模型以及训练后量化 (Post-Training Quantization) 模型的准确度对照表。
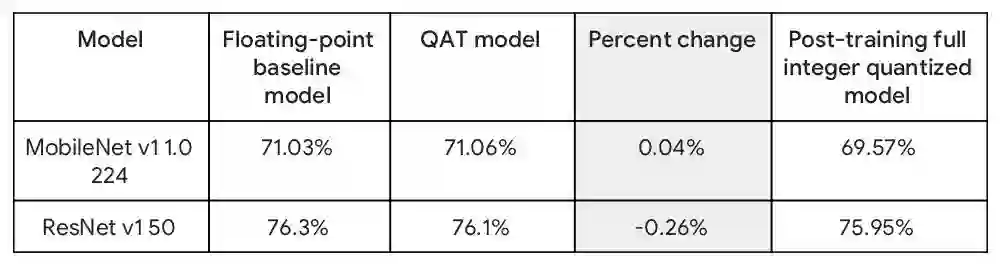
了解更多,请阅读 此文。
更快的跨平台推理
更佳的 CPU 性能
提升 CPU 性能一直是团队的首要任务,并且在最近几个月中,我们进行了多项与 CPU 相关的性能优化研究,并发布了相关成果。我们还开发了一个优化后的矩阵乘法库 (ruy), 此库是从头构建的,针对移动环境中使用的 CPU 硬件和模型所进行的性能优化。自 TensorFlow 1.15 版本开始,这个库就在所有 ARM 设备上默认启用,并大范围的为降低模型和用例的延迟提供了帮助,将延迟降低了 1.2 到 5 倍 。
-
ruy
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/experimental/ruy
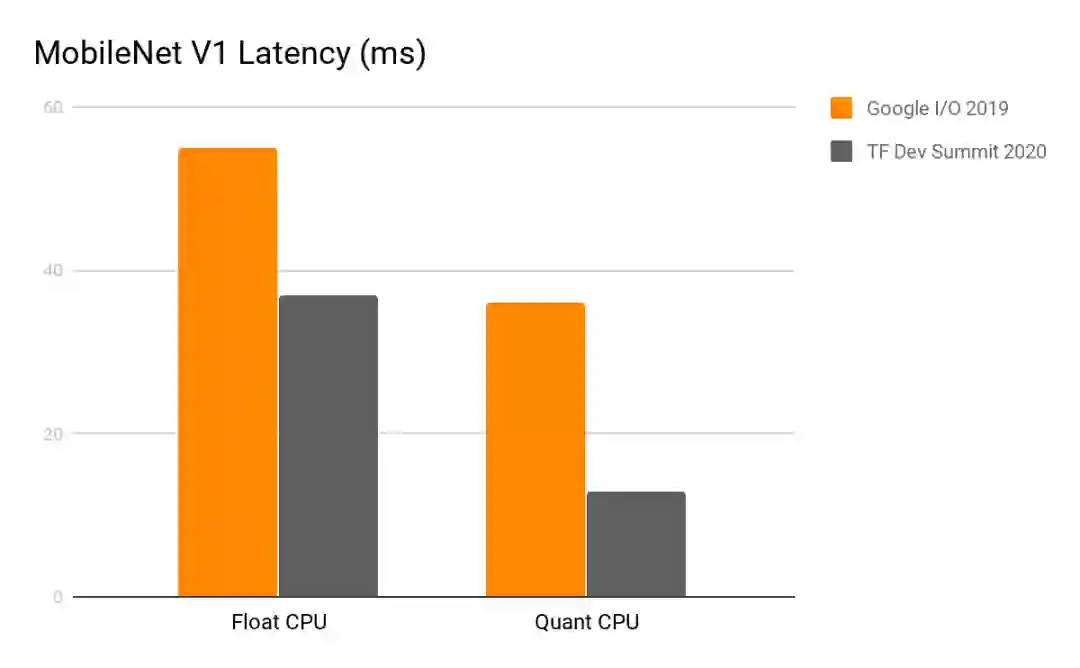
Pixel 4 单线程 CPU,2020年2月
我们计划在 TensorFlow 2.3 版本中发布一些 CPU 优化功能,包括可以提高执行速度约 40% 的模型 训练后量化 (Post-training weight quantization),以及全新的高度优化后的浮点卷积核库 (XNNPACK)。在 TensorFlow Lite 支持的所有关键浮点卷积模型上的测试结果表明,XNNPACK 可以使执行速度提高 20-50% 。
XNNPACK
https://github.com/google/XNNPACK
新的硬件加速器 Delegate 助力实现更快推理
我们致力将 TensorFlow Lite 打造成真正的跨平台框架,这样您只需训练一次模型便可在所有支持的平台上获得最佳性能。在过去的几个月中,我们增加了对 高通 Hexagon DSP 和 苹果 CoreML 的推理支持,并通过增加对 OpenCL 的支持提高了安卓 GPU 上的推理速度。
Hexagon DSP 是一种微处理器,常见于百万台使用高通骁龙 SoC 的安卓手机。与 CPU 相比,新的 TensorFlow Lite Hexagon Delegate 利用 DSP 实现了 MobileNet 和 InceptionV3 等模型,性能大幅提升,提升幅度可达 3-25 倍,同时 CPU 和 GPU 的能效也得到了提升。可阅读我们的这篇 文章 了解更多。
CoreML 是在苹果设备上使用的机器学习框架,它还提供了在 Neural Engine 上运行机器学习模型的 API。新的 TensorFlow Lite CoreML Delegate 允许在 CoreML 和 Neural Engine(如果设备载有该芯片)上运行TensorFlow Lite 模型,以更低的功耗实现更快的推断速度。在含有 Neural Engine 的 iPhone XS 以及后续发布的设备上,我们观察到各种计算机视觉模型的性能提高了 1.3 倍至 11 倍。更多详细信息请参阅我们的这篇 文章。
OpenCL 是一款用于编写跨异构平台执行程序的框架。我们最近在 TensorFlow Lite GPU Delegate 中增加了对 OpenCL 的支持。在多个计算机视觉模型上进行测试,更新后的性能提升为在 CPU 上的 4-6 倍, 在 OpenGL 的 2 倍。下图是三者在 Pixel 4 上测试后端性能的对照结果。
-
TensorFlow Lite GPU Delegate
https://tensorflow.google.cn/lite/performance/gpu
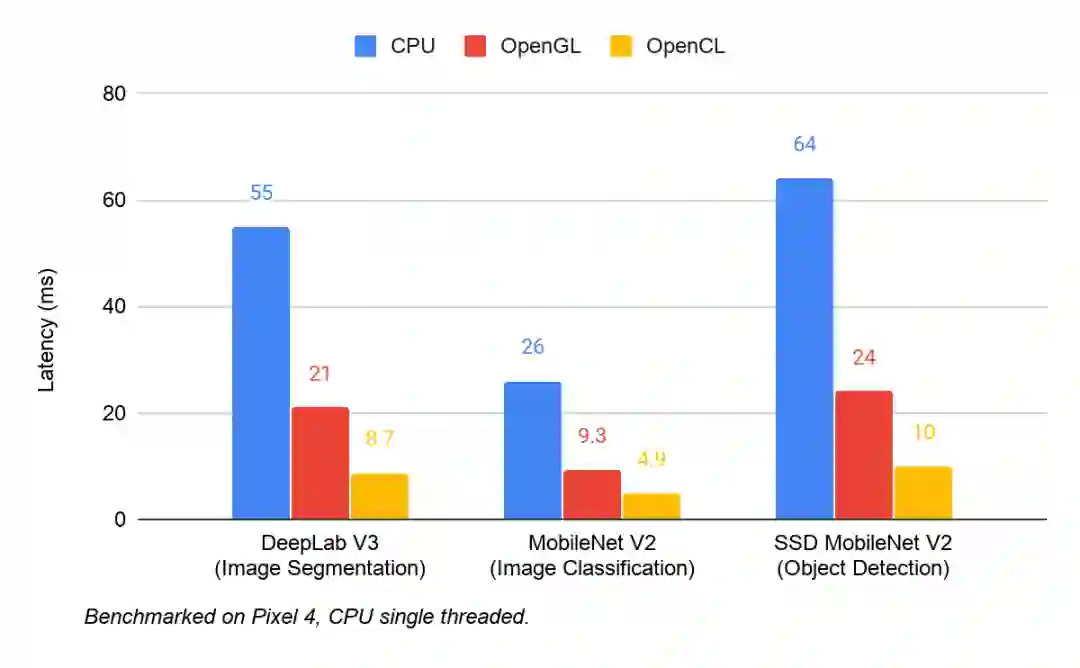
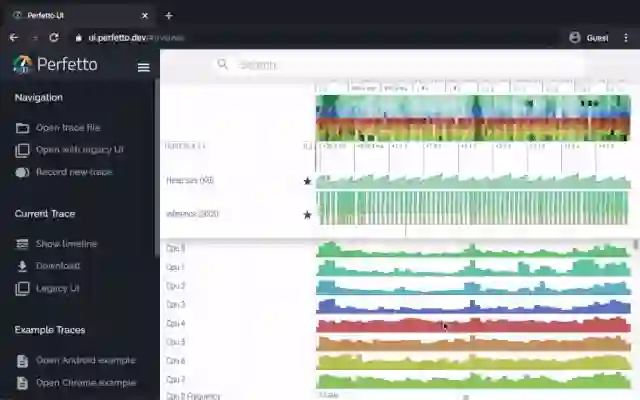
性能分析工具,助力识别 Android 性能瓶颈
TensorFlow Lite 支持对内部事件(如算子调用)的检测日志记录,可以通过 Android 的 系统跟踪 (System Tracing) 进行追踪。新的性能分析数据助您识别性能瓶颈。
系统跟踪
https://developer.android.com/topic/performance/tracing
以下是一些性能分析工具给出的分析示例,及性能提升的备选解决方案:
如果可用的 CPU 内核数量少于推理线程的数量,则 CPU 调度开销可能会导致性能下降。您可以在应用程序中重新调度其他大量占用 CPU 的任务,以避免与模型推断重叠,或尝试调整解释器线程的数量。
如果算子没有完全 delegate,那么模型计算图中的某些部分将在 CPU 上执行,而不是按预想的在硬件加速器上执行。您可以将不支持的算子替换为相似的已支持算子。
这里
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/tools/benchmark/android#to-trace-tensorflow-lite-internals-including-operator-invocation
易用性方面的改进
无需 ML 专业知识也能创建模型
通过 TensorFlow Lite Model Maker,您也可以用上 SOTA 模型,仅需对数据集进行迁移学习。利用直观的 API 简化了机器学习中的复杂概念,这大大降低了刚接触机器学习的开发人员的学习门槛。例如,仅需 4 行代码即可训练一个 SOTA 图像分类模型。
data = ImageClassifierDataLoader.from_folder('flower_photos/')
model = image_classifier.create(data)
loss, accuracy = model.evaluate()
model.export('flower_classifier.tflite', 'flower_label.txt', with_metadata=True)
Model Maker
https://github.com/tensorflow/examples/tree/master/tensorflow_examples/lite/model_maker
Model Maker 支持由 TensorFlow Hub 提供的许多 SOTA 模型,包括 EfficientNet-Lite 模型。它目前支持两个用例:图像分类(教程 1)和文本分类(教程 2),更多的 CV 和 NLP 用例将在不久后推出。
教程 1
https://colab.research.google.com/github/tensorflow/examples/blob/master/tensorflow_examples/lite/model_maker/demo/image_classification.ipynb教程 2
https://colab.research.google.com/github/tensorflow/examples/blob/master/tensorflow_examples/lite/model_maker/demo/text_classification.ipyn
使用元数据(Metadata)简化模型共享
传统上,使用 TensorFlow Lite 运行推理使用的是原始张量。这带来了两个问题:
比如 TensorFlow Lite 模型的使用者将需要确切地知道一个 1x224x224x3 张量的含义。它是位图吗?如果是,是红色,蓝色还是绿色通道?如果模型的创建团队和模型的使用团队不是同一个时,这就会成为问题。
另一个问题是在对高维数据进行转换时,使用极易产生各种错误的样板代码。例如把 Bitmap 转换为 RGB 浮点数组或者 ByteArray 。
为了解决第一个问题,我们在 TensorFlow Lite 中增加了对 模型元数据(视频相关请看这篇文章)的支持 ,这让模型创建者可以使用类型化的对象来描述模型的输入和输出,从而避免 TensorFlow Lite 模型使用者会产生种种猜测除了基本信息(例如位图或颜色通道的大小)之外,我们还支持如均值和标准差之类的信息的添加,从而让模型的使用者了解应当如何在使用时进行适当的归一化操作。
模型元数据
https://tensorflow.google.cn/lite/convert/metadata
为了解决第二个问题:样板代码,我们创建了一个 Android 代码生成器 ,可以读取 TensorFlow Lite 元数据,并创建适当的包装代码以调整图片大小,对其进行归一化且从 ByteArray 进行转换。这意味着使用模型的开发人员现在可以使用他们熟悉的高级对象与 TensorFlow Lite 模型进行交互:
// 1.初始化 模型
MyClassifierModel myImageClassifier = new MyClassifierModel(activity);
// 2.设置了一个名为inputBitmap位图输入
MyClassifierModel.Inputs inputs = myImageClassifier.createInputs();
inputs.loadImage(inputBitmap));
// 3.运行模型
MyClassifierModel.Outputs outputs = myImageClassifier.run(inputs);
// 4.检索结果
Map<String, Float> labeledProbability = outputs.getProbability();
Android 代码生成器
https://tensorflow.google.cn/lite/guide/codegen
目前这仍是一项实验功能,最先得到支持的是关于图像的模型。我们实现了对 TensorFlow Hub 和 Image Classifier Model Maker 上面的大多数 TensorFlow Lite 视觉模型的元数据支持。接下来,该项目将会往以下三个方向进行扩展:支持图像以外的输入类型以实现更多用例,构建 Android Studio 插件使它更易于使用,最后但同样重要的一点是,增加对 iOS 的支持。
Image Classifier Model Maker
https://colab.research.google.com/github/tensorflow/examples/blob/master/tensorflow_examples/lite/model_maker/demo/image_classification.ipynb
更多示例和学习资料
我们在 Coursera 和 Udacity 上推出了两个在线课程,为 TensorFlow Lite 提供结构化的学习路径。这两门课程都是为期四周的课程,介绍如何在不同的平台上使用 TensorFlow Lite:Android,iOS 和 IoT 设备。
Coursera
https://www.coursera.org/learn/device-based-models-tensorflowUdacity
https://www.udacity.com/course/intro-to-tensorflow-lite--ud190
社区对 TensorFlow 一直有着非常重要驱动作用。TensorFlow Lite 社区的一些热心成员共同创建了预训练模型,样本和教程的集合。您可以在 GitHub 上找到它们,同时欢迎您的加入,一同为社区贡献力量!
GitHub
https://github.com/margaretmz/awesome-tflite
更好地支持微控制器
Arduino 官方支持
TensorFlow Lite for Microcontrollers 现已成为官方 Arduino 库,这使得您可以轻松地在 5 分钟内将语音检测部署到 Arduino Nano。这就是比以往都更易上手的 TF Micro!

更多 TF Micro 优化
我们一直与领先的行业合作伙伴展开合作。为了让 TF Micro 在其微控制器或 DSP 的硬件架构上跑出更好的性能,他们正在努力优化 TF Micro 的代码实现。Cadence 宣布旗下的 Tensilica HiFi DSP 系列支持 TF Micro 。Cadence 是我们的 DSP 关键合作伙伴,我们将继续与他们合作以带来更多优化。当开发人员想要对 TF Micro 模型实现优化时,只需选用上述特定硬件即可,无需手动移植或手动调试模型!
Cadence 宣布旗下的 Tensilica HiFi DSP 系列支持 TF Micro
https://www.cadence.com/en_US/home/company/newsroom/press-releases/pr/2020/cadence-tensilica-hifi-ip-accelerates-ai-deployment-with-support.html
Google 内部是如何应用 TF Lite?
基于服务器的模型迁移到基于客户端的设备上模型,改善用户体验 — Google Lens
构建机器学习流水线,处理实时视频流 — Live Perception
展望
XNNPACK 集成与执行高度优化浮点模型。
这将大大加快跨平台的 CPU 推理速度。
更新 SOTA 设备端模型以及相关的指南和示例,将会展示更多的使用案例,例如用于在移动设备上进行本地推理的 C/C++ API。
调整二进制代码大小的新工具,根据客户端使用的算子进行大小调整,以减少模型大小对客户端应用程序的影响。
对 Model Maker 进行增强,可以执行更多类型的任务,例如对象检测或 NLP 任务。
我们会增加 BERT 支持,以支持新的 NLP 任务(例如问答),这可以让没有 ML 专业知识的开发人员能够通过迁移学习来构建最新的 NLP 模型。
-
扩展元数据和代码生成工具,以支持更多用例,包括对象检测和其他与 NLP 相关的任务,以及与 Android Studio 的集成。
如需查看 TensorFlow Lite 的长期产品路线图,请访问我们的 网站。
网站
https://tensorflow.google.cn/lite/guide/roadmap
关于 TensorFlow DevSummit 系列视频,中文视频正在陆续制作与上传中,请点击“阅读原文”,访问 Bilibili “Google中国”。