无需一行代码就能搞定机器学习的开源神器

作者 | Shantanu Kumar
责编 | 魏伟
对于机器学习和数据科学的初学者来说,最大的挑战之一是需要同时学习太多知识,特别是如果你不知道如何编码。你需要快速地适应线性代数、统计以及其他数学概念,并学习如何编码它们,对于新用户来说,这可能会有点难以承受。
如果你没有编码的背景并且发现很难学习下去,这时你可以用一个GUI驱动的工具来学习数据科学。当你刚开始学习的时候,可以集中精力学习实际的项目。一旦适应了基本的概念,你就可以在以后慢慢学习如何编写代码。
在今天的文章中,将介绍一个基于GUI的工具:KNIME。读完本文,你将在无需编写任何代码的情况下,预测零售商店的销售情况。
让我们开始吧!
为什么是KNIME ?
KNIME是一个基于GUI工作流的强大分析平台。这意味着你不必知道如何编写代码(对于像我这样的初学者来说是一种解脱),就能够使用KNIME并获得洞察力。
你可以执行从基本I/O到数据操作、转换和数据挖掘等功能。它将整个过程的所有功能合并到一个工作流中。
设置系统
在开始KNIME之前,首先你需要安装它并在PC上设置它。到KNIME下载页面(http://www.knime.com/downloads)下载。

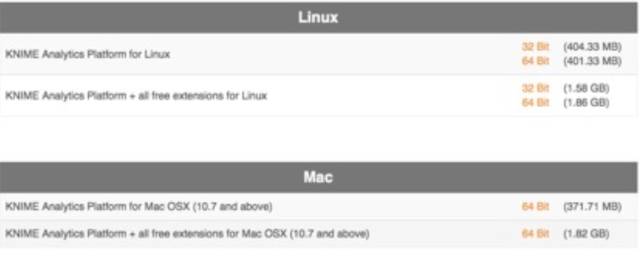
为你的电脑确定正确的版本:
安装该平台,并为KNIME设置工作目录以存储其文件:
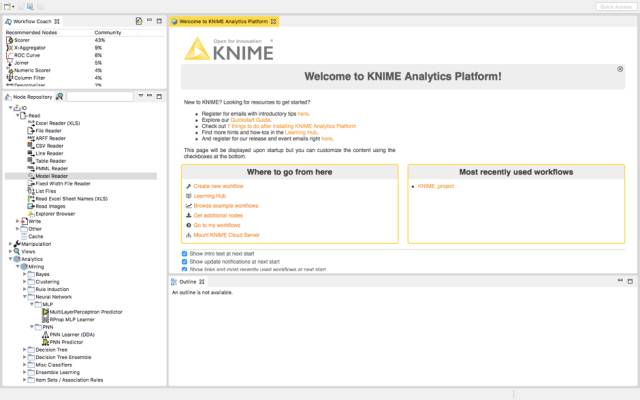
这就是你屏幕上显示的样子。
创建你的第一个工作流程
在我们深入研究KNIME的工作原理之前,让我们先定义几个关键术语来帮助我们理解,然后看看如何在KNIME中打开一个新项目。
节点:节点是任何数据操作的基本处理点。它可以根据你在工作流程中选择的内容来执行一些操作。
工作流:工作流是指你在平台上完成特定任务的步骤或操作的顺序。
在左上角的工作流指导会向你展示KNIME社区特定节点的使用百分比。节点存储库将显示特定工作流可以拥有的所有节点,这取决于你的需要。当创建第一个工作流时,你还可以浏览示例工作流来检查更多的工作流。这是迈向解决任何问题的第一步。
要建立一个工作流,可以遵循这些步骤。
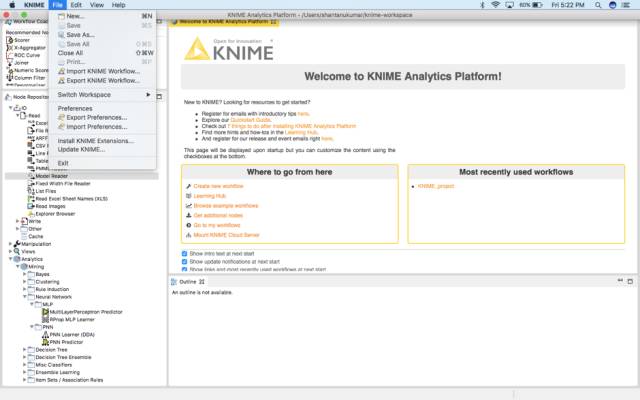
进入文件菜单,点击新建:
在你的平台上创建一个新的KNIME工作流并命名它为Introduction。
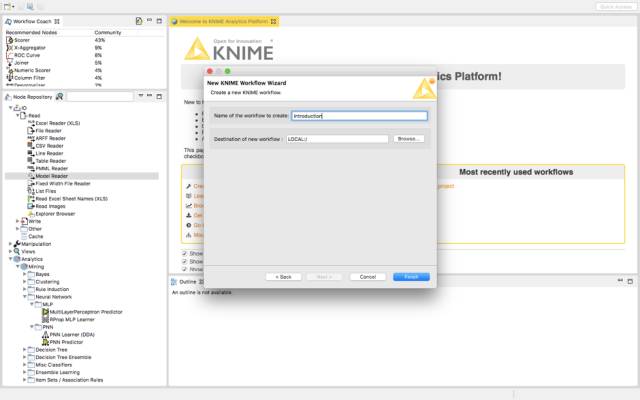
现在,当点击Finish时,你应该已经成功创建了你的第一个KNIME工作流。
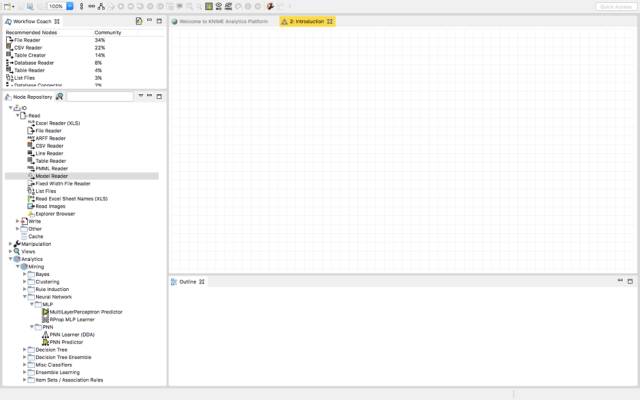
这是你在KNIME上的空白工作流程。现在,你就可以从存储库将任何节点拖放到工作流中来探索和解决任何问题。
KNIME介绍
KNIME是一个可以帮助解决我们在数据科学的边界上可能遇到任何问题的平台。从最基本的可视化或线性回归到高级深度学习,KNIME可以做到这一切。
作为一个示例用例,我们在本教程中要解决的问题是Datahack可以访问的BigMart销售问题。
这个问题具体描述如下:
BigMart的数据科学家已经收集了2013年不同城市10家商店1559种产品的销售数据。此外,还定义了每个产品和存储的某些属性。其目的是建立一个预测模型,并在特定的商店中找出每种产品的销售情况。使用这个模型,BigMart将尝试了解产品和商店的属性,这些属性在增加销售中扮演着关键的角色。
你可以在这里(https://www.analyticsvidhya.com/blog/2016/02/bigmart-sales-solution-top-20/?utm_source=dzone&utm_medium=social)找到BigMart销售问题的方法和解决方案。
导入数据文件
让我们从理解这个问题的第一步骤开始:导入我们的数据。
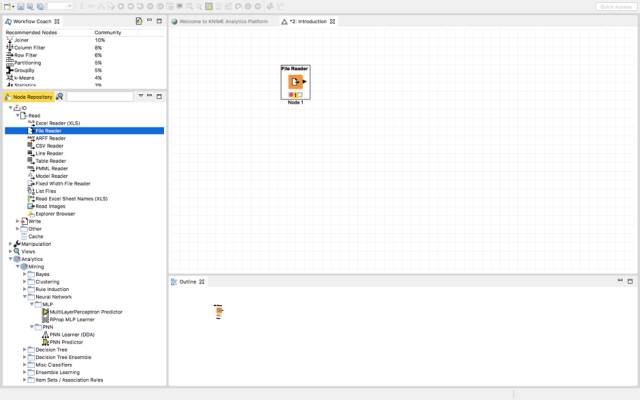
拖放文件阅读器节点到工作流并双击它。接下来,浏览需要导入到工作流中的文件。
在本文中,我们将学习如何解决BigMart销售的问题,我将从BigMart Sales导入训练数据集:
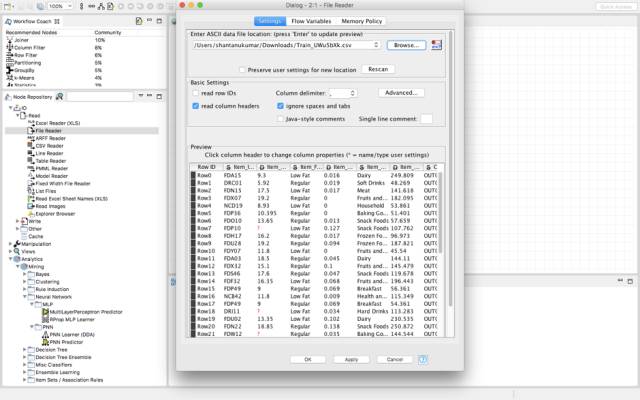
这就是导入数据集时预览的样子。
让我们可视化一些相关的列,并找出它们之间的相关性。相关性帮助我们发现哪些列可能是相互关联的,并具有更高的预测能力来帮助我们最终的结果。
要了解更多相关信息,请阅读本文
https://www.analyticsvidhya.com/blog/2015/06/correlation-common-questions/?utm_source=dzone&utm_medium=social
为了创建一个correlation matrix矩阵,我们在节点存储库中键入“linear correlation”,然后将其拖放到我们的工作流中。
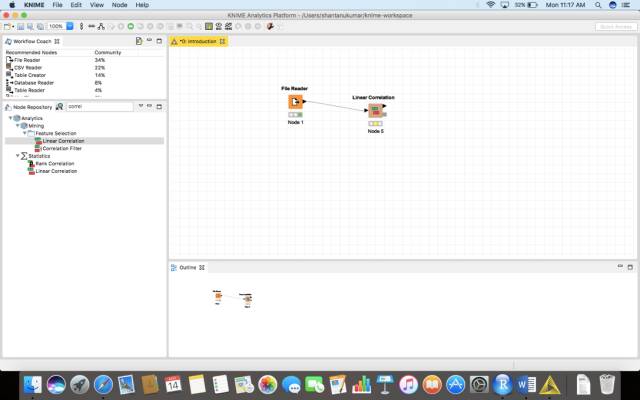
在我们拖放之后,我们将把文件阅读器File reader的输出连接到节点linear correlation的输入。
单击topmost面板上的绿色按钮Execute。然后右击相关节点并选择View:Correlation Matrix 生成下图。
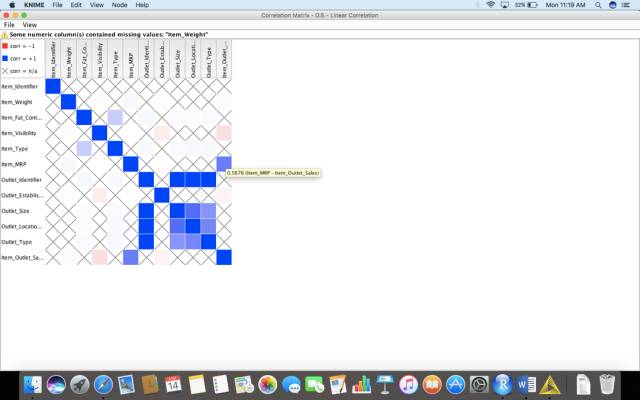
这将帮助你选择重要的特性,并通过在特定的单元上悬停来更好地预测。
接下来,我们将可视化数据集的范围和模式来更好地理解它。
可视化和分析
其实,我们想要从数据中了解到的主要事情之一就是:什么东西被卖得最多。
有两种解释信息的方法:散点图(Scatter Plot )和饼图(pie chart)。
散点图
在我们的节点存储库中搜索Views 项下的Scatter Plot 。将其以类似的方式拖放到工作流中,并将文件阅读器的输出连接到此节点。
接下来,配置节点,选择你需要多少行数据,并希望可视化(我选择了3000)。
单击Execute,然后查看:散点图。
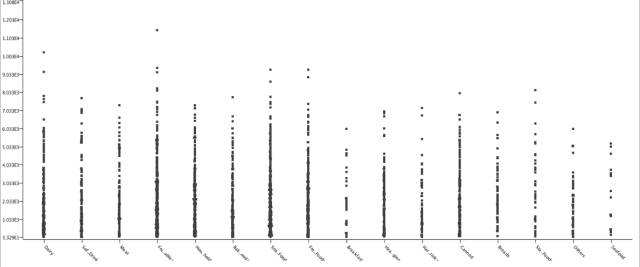
X轴为Item_Type,Y轴为Item_Outlet_Sales。
上面的图代表了每种商品的销售情况,并向我们展示了水果和蔬菜的销售量是最高的。
饼状图
要了解我们数据库中所有产品类型的平均销售估算,我们将使用一个饼图。
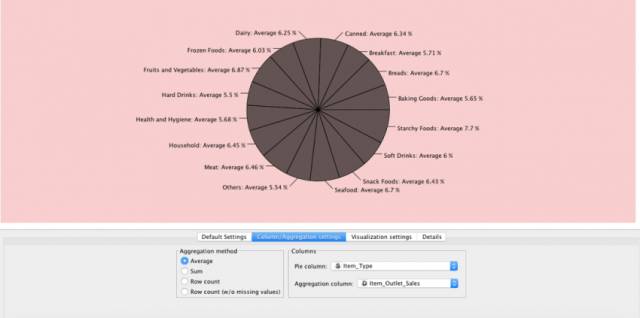
单击视图下的饼图节点并将其连接到你的文件阅读器。选择需要隔离的列并选择首选的聚合方法,然后应用。
这张图表向我们展示了销售在各种产品上的平均分配。“淀粉类食品”的平均销量为7.7%。
以上,我只使用了两种类型的视图,尽管你还可以在浏览Views选项卡下查看多种表单中的数据。比如可以使用直方图、行图等来更好地可视化你的数据。
我喜欢像Tableau这样的工具,它是实现数据可视化的最有力工具。
如何清洗数据?
在训练模型之前,你可以进行的一项内容就是数据清理和特性提取。这里,我将提供一个关于KNIME数据清理步骤的概述。
寻找Missing Values
在估算值之前,我们需要知道哪些是缺失的。
再次访问节点存储库,找到Missing Values节点。拖放它,并将我们的文件阅读器File reader 的输出连接到节点。
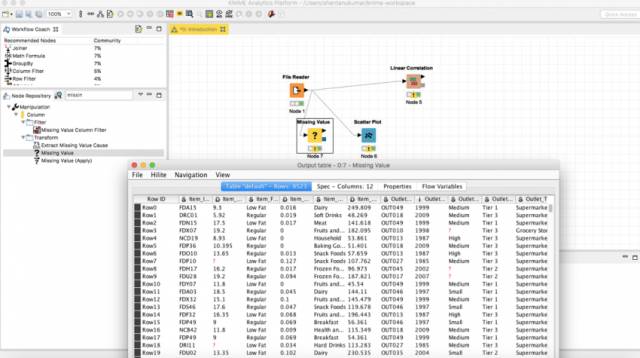
Imputations
要imputed values ,请选择Missing value并单击Configure。根据所要数据的类型,选择你想要的数据,并点击Apply。
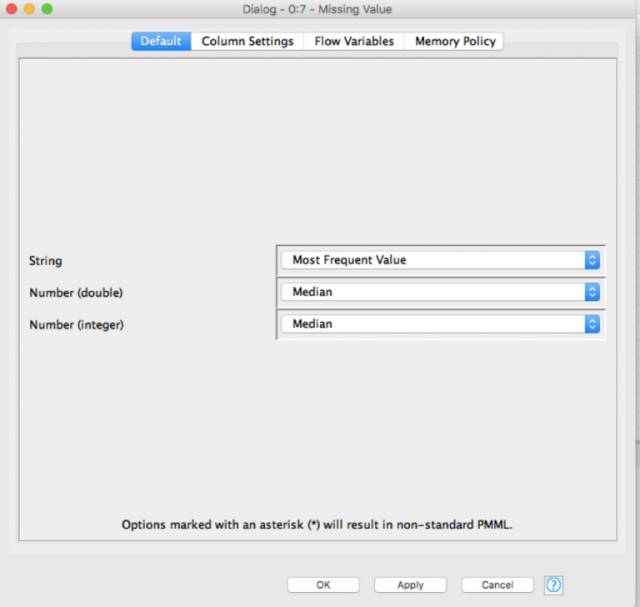
现在,当我们执行它时,在Missing value节点的输出端口上已经准备好了具有imputed values的完整数据集。在我的分析中,我选择了imputation 方法为:
String
Next value
Previous value
Custom value
Remove row
Number (double and integer)
Mean
Median
Previous value
Next value
Custom value
Linear interpolation
Moving averag
训练你的第一个模型
让我们来看看如何在KNIME中构建机器学习模型。
实现一个线性模型Linear Model
首先,我们将训练一个线性模型Linear Model ,它包含了数据集的所有特性,以了解如何选择特性并构建模型。这是一个初学者的线性回归指南。
进入你的节点存储库,并将Linear Regression Learner拖到工作流中。然后将收集的干净数据连接到 Missing value 节点的输出端口。
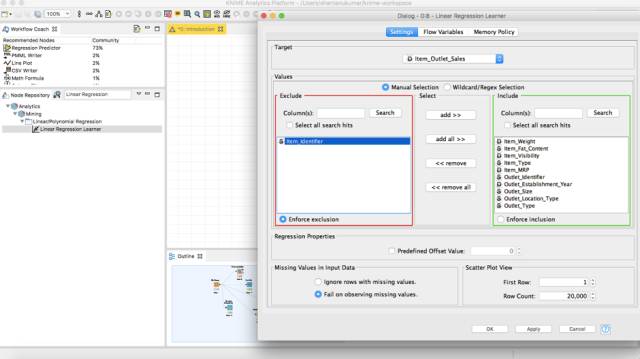
这是你现在的屏幕呈现。在Configuration选项卡中,排除Item_Identifier并在顶部选择目标变量。完成这个任务之后,需要导入testdata来运行模型。
将另一个文件阅读器拖放到工作流中,并从你的系统中选择测试数据。
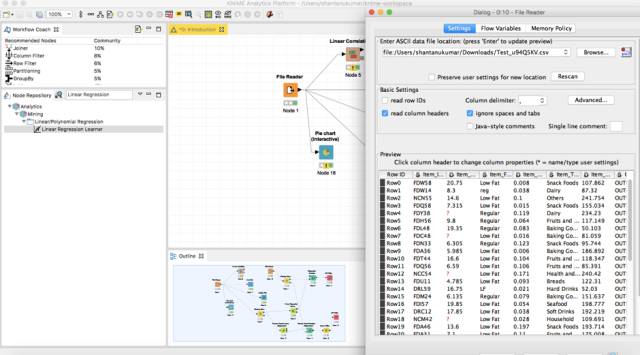
正如我们所看到的,测试数据也包含缺失值。我们将以与训练数据相同的方式在Missing value节点上运行它。
在我们清洗了测试数据之后,将引入一个新的节点:Regression predictor。
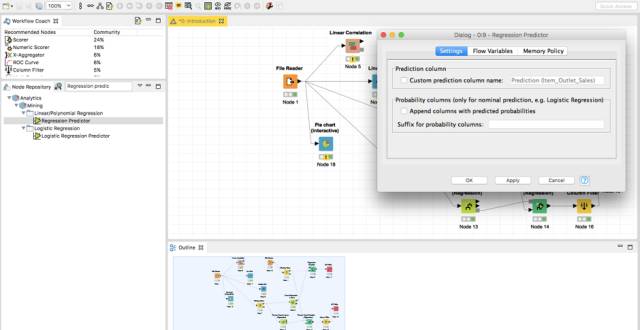
通过将learner的输出与预测器的输入连接起来,将你的模型加载到预测器中。
在预测器的第二个输入中,加载你的测试数据。预测器会根据你的learner自动调整预测栏,但也可以手动改变它。
KNIME有能力在分析标签下训练一些非常专业的模型。这里是一个列表:
Clustering
Neural networks
Ensemble learners
Naïve Bayes
提交你的解决方案
在执行预测器之后,输出几乎已经准备好提交了。
在节点存储库中找到节点列过滤器Column filter,并将其拖到工作流中。将预测器的输出连接到列筛选器,并配置它筛选所需的列。在这种情况下,你需要Item_Identifier、Outlet_Identifier和Outlet_Sales的预测。
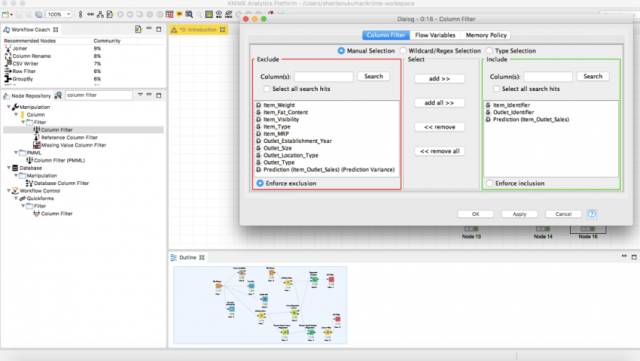
执行列过滤器Column filter,最后,搜索节点CSV writer并将你的预测记录在硬盘上。
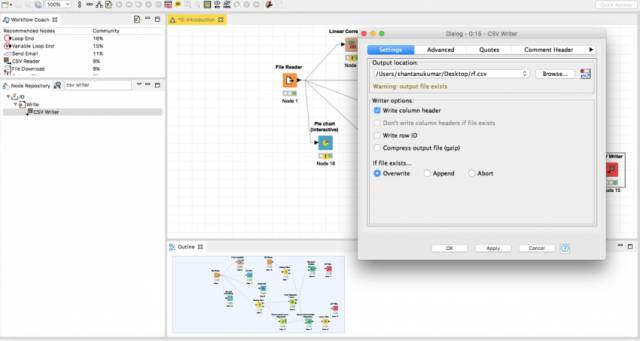
调整路径,将其设置为需要存储的CSV文件,并执行该节点。最后,打开CSV文件以按照我们的解决方案来纠正列名。将CSV文件压缩成ZIP文件并提交你的解决方案!
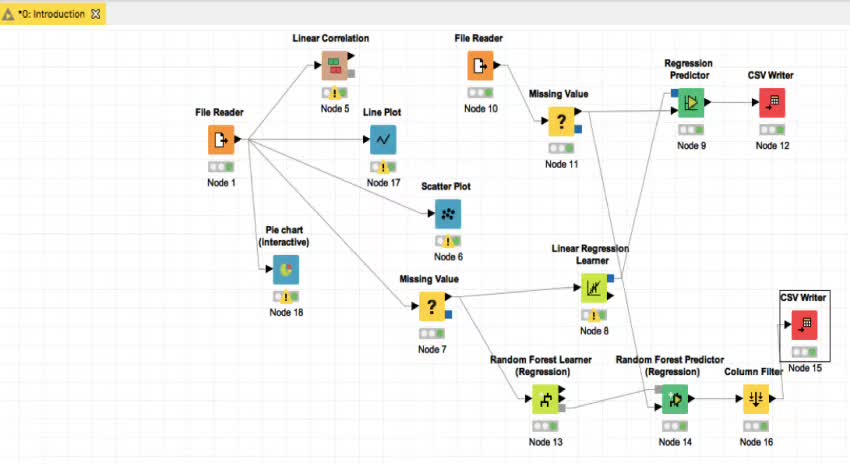
这是最终的工作流图。
在可移植性方面,KNIME工作流非常方便。它们可以发送给你的朋友或同事一起构建,增加你产品的功能!
为了导出一个KNIME工作流,可以简单地单击File > Export KNIME Workflow。
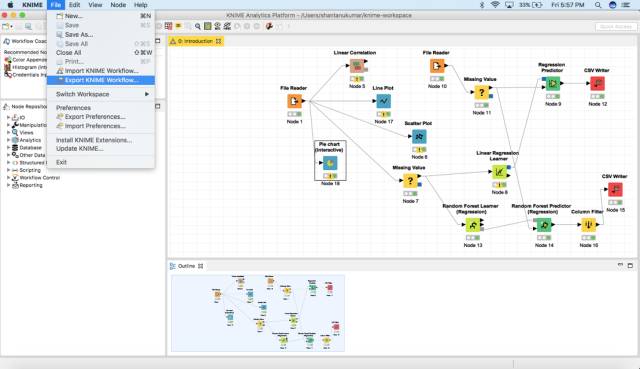
在此之后,选择您需要导出的合适的工作流,然后单击Finish。
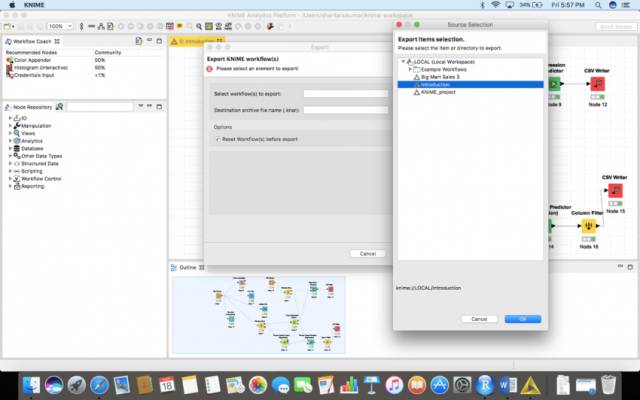
这会创建一个.knwf文件,你可以发送给任何人,他们将能够使用一键访问它!
限制
KNIME是一个非常强大的开源工具,但是它也有自己的局限性。主要是:
可视化并不像其他一些开源软件(比如RStudio)那样简洁优雅。
版本更新不受支持;你将不得不重新安装软件(也就是说,从版本2更新到版本3,你将需要重新安装)。
贡献社区不像Python或CRAN社区那么大,因此新的功能需要很长时间才能添加到KNIME中。
原文链接:
https://dzone.com/articles/building-your-first-machine-learning-model-using-k
资源推荐
重磅 | 128篇论文,21大领域,深度学习最值得看的资源全在这了
爆款 | Medium上6900个赞的AI学习路线图,让你快速上手机器学习
Quora十大机器学习作者与Facebook十大机器学习、数据科学群组
Chatbot大牛推荐:AI、机器学习、深度学习必看9大入门视频
葵花宝典之机器学习:全网最重要的AI资源都在这里了(大牛,研究机构,视频,博客,书籍,Quora......)
重磅|数据科学入门必看:来自斯坦福、MIT、微软、Twitter等名校名企的20门课程清单





