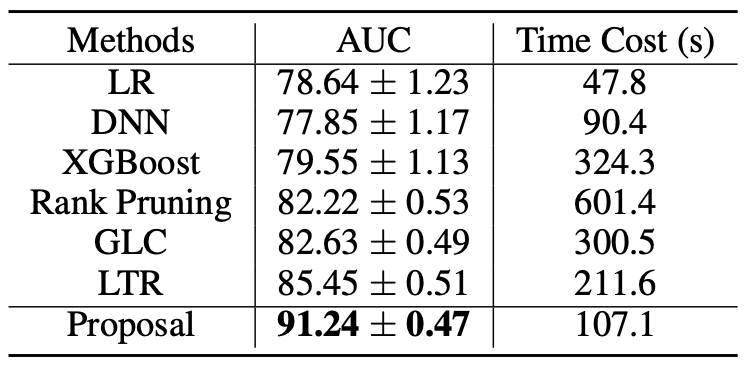
如何提升网约车用户体验?南大&滴滴提出复合弱监督学习方法,AUC提升5%以上


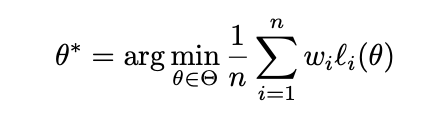
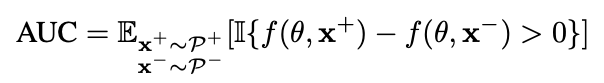
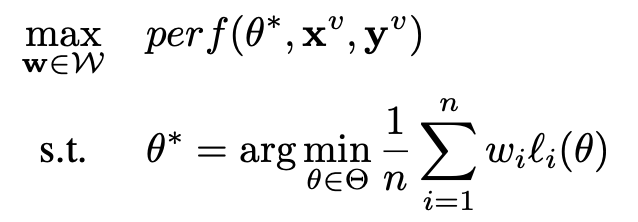
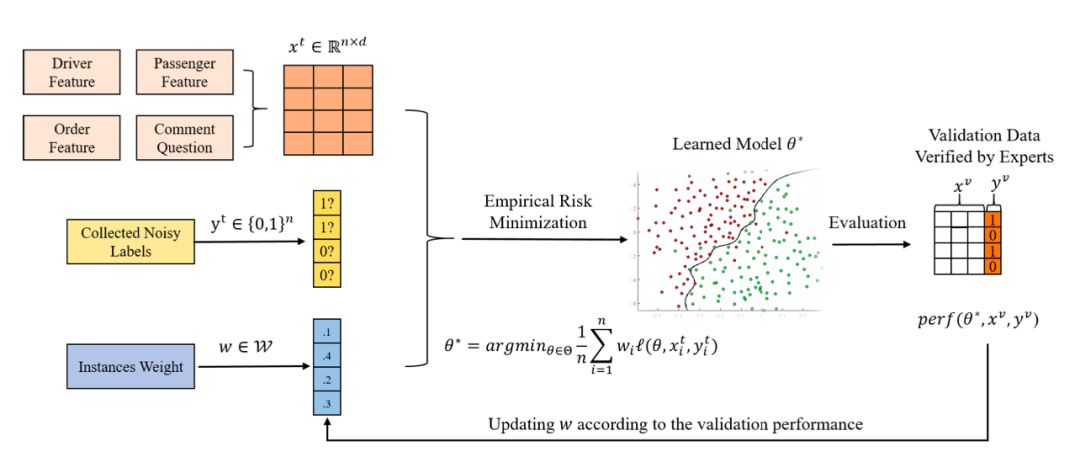



登录查看更多
相关内容

弱监督学习:监督学习的一种。大致分3类,第一类是不完全监督(incomplete supervision),即,只有训练集的一个(通常很小的)子集是有标签的,其他数据则没有标签。这种情况发生在各类任务中。例如,在图像分类任务中,真值标签由人类标注者给出的。从互联网上获取巨量图片很容易,然而考虑到标记的人工成本,只有一个小子集的图像能够被标注。第二类是不确切监督(inexact supervision),即,图像只有粗粒度的标签。第三种是不准确的监督(inaccurate supervision),模型给出的标签不总是真值。出现这种情况的常见原因有,图片标注者不小心或比较疲倦,或者某些图片就是难以分类。





相关VIP内容
相关资讯
相关论文