人和人吵架生气,但AI和AI吵架反倒可以带来安全

OpenAI 新文章使用辩论来达到安全的 AI 系统。
AI 科技评论按:OpenAI 近日的一篇新文章简述了如何通过辩论使 AI 系统矫正自身的问题来保证系统的安全,人类是辩论的最终评价者。由于人类直接决定辩论胜负,所以人类可以让 AI 系统的价值取向始终与人类保持一致,作者认为这种方法可以保证 AI 系统的安全。AI 科技评论全文翻译如下。

AI Safety via Debate 通过辩论达成 AI 安全
我们提出了一项新的人工智能安全技术,该方法先训练智能体对话题进行辩论,然后由人判断输赢。我们认为这种或类似的方法最终可以帮助我们训练 AI 系统去执行超过人类认知能力的任务,同时这些任务的执行结果仍然与人的价值观是一致的。我们将通过初步的概念验证实验来概括这种方法,同时我们还会发布了一个 Web 网页,让人们可以体验这项技术。
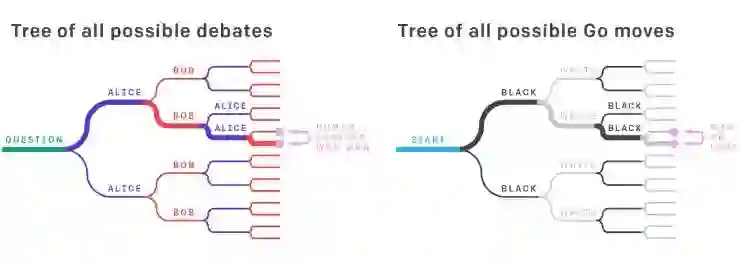
辩论方法可视为围棋中使用的游戏树,只不过把走子换成了辩论的句子,然后在最终的叶子节点由人类的判断决定输赢。在辩论和围棋中,真正的答案要从整个树进行全局考虑,但是强大的智能体选择的某条单一路径可以是最终答案。 例如,虽然业余的围棋手不能直接评估职业选手某一步下法的好坏,但他们可以通过评估游戏结果来判断职业玩家的实力。
想要让 AI 智能体符合人类目标和偏好,有一种方法是人类在训练期间先规定好哪些行为是安全和有用的。虽然这种思路看似不错,但这种方法要求人类判断 AI 智能体表现出的行为的好坏,然而在很多情况下,智能体的行为可能太复杂,以至于人们无法理解,或者任务本身可能就难以判断或评价。例如,在计算机安全相关环境中运行的代理程序或协调大量工业机器人的代理程序,这些都是人类无法直接观察进行评价的场景。
我们如何使人类能够有效地监督先进的 AI 系统呢?一种方法是利用 AI 自身来辅助监督,即要求 AI 系统指出所有自身行为中存在的缺陷。为了达到这个目的,我们将学习过程重新定义为两个智能体之间进行辩论,然后人类对辩论过程进行评判。即使智能体对问题有比人类更深层次的理解,人类也可以去判断哪个智能体有更好的论点(类似于专家和证人争辩说服陪审团)。
我们的方法为两个对抗的 AI 智能体之间的辩论游戏提供了一个特定的辩论格式。这两个智能体可以进行自我训练,类似于 AlphaGo Zero 或 Dota 2 AI。我们希望经过适当培训的智能体能够拥有远超人类价值判断能力。如果两个智能体对现状持不同意见,但它们各自完整的推理过程太繁琐而无法向人展示,那么辩论就可以集中在更简单的事实争议上,最终向人类呈现一个简单可判断的选择。
上面讲的不直观,下面举个例子,我们现在考虑一下这个问题:「哪里是度假的最佳去处?」。如果一个智能体 Alice 从主人翁的角度考虑后说「阿拉斯加」,其实很难判断这是否是最好的选择。如果第二个智能体 Bob 说「不,应该是巴厘岛」,这听起来可能令人信服,因为巴厘岛更加暖和。Alice 回复说:「你不能去巴厘岛,因为你的护照来不及办了」,这表明巴厘岛这个选项存在缺陷,而这一缺陷我们可能没意识到。然后鲍勃反击「加急护照服务只需两周」。辩论一直持续到人类可以正确选择为止,也就是直到另一方的智能体知道再辩论下去也无法再改变人类的决定为止。
说服一个稀疏 MNIST 分类器
虽然我们认为这种方法在智能体长期使用自然语言与对方进行对话时最为有效,但我们需要在更简单的领域进行测试,因为今天的自然语言建模能力不足以完成此任务。另一方面因为对于未超出人类能力的任务,测试更容易。所以我们决定将测试转到可视化领域,并将「智能体有评价者(人类)不具有的能力」的降辩论难度,降低到「智能体有评价者(人类)不具有的知识」。测试中评价者的目的是猜测图像的内容,但评价者除了智能体筛选显示的像素点外看不到其他内容。智能体们看到完整的图像,然后开始游戏——它们交替显示单个像素给评价者,这个过程会持续很多轮。这个测试中的完整图像人类无法轻易判断出来,每个显示的像素都是智能体的辩论点。
描述一下实验可能更加容易理解。我们在最简单的 MNIST 数据集上进行了测试。测试的评价者不是人类,而是预先训练的分类器,在预训练分类器时每个图片都随机采样,最终目的是这个分类器通过识别 6 个非黑色像素来判断 MNIST 数字。实验开始首先两个智能体对交替显示的像素的位置进行辩论,在显示 6 个像素后停止(所以评价者总共只看到一点点信息)。测试中一个智能体是诚实的,并试图让评价者猜对,另一个智能体试图让评价者猜错。如果两个智能体均事先声明他们争论的是哪个数字,那么这场辩论会将稀疏分类器的准确率从 59.4%提升到 88.9%。也就是说,诚实的智能体在 MNIST 测试集中获胜概率为 88.9%,在辩论过程中还提升了评价者的准确率。
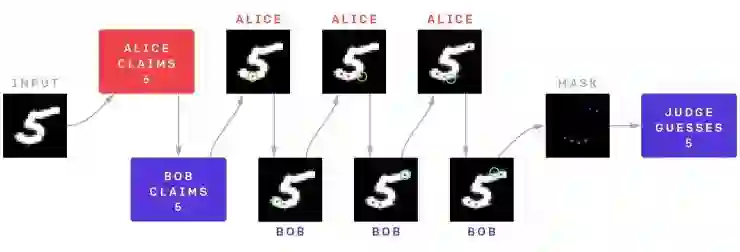
MNIST 辩论游戏的结构。辩手 Alice 和 Bob 看到一个图像,Alice 试图欺骗评价者认为它是一个 6,Bob 试图正确说服评价者是一个 5。他们交替向评价者展示非黑色像素,评价者在看完 6 个像素后正确地将其标识为 5。Alice 追踪显示底部曲线使其看起来像一个 6(红色像素),但是 Bob 通过揭示右上角的像素(蓝色像素)来有效地针对 Alice 的策略,因为这是 MNIST 中大多数 6 所没有的部位。
直观地说,图像更可能包含证明图片真实内容的像素,而不是包含混淆图片内容的的像素,所以选择的 6 个像素中一半诚实和一半欺骗,要比 6 个随机像素更公平。如果评价者是一个能够一次综合多个参数进行推理但不能筛选所有可能参数的人类,那么我们希望奖励机制可以奖励辩论智能体帮我们做筛选这一行为,即便我们缺乏一个区分辩论好坏的先验机制。
下面的图片显示了几个示例游戏。因为欺骗者胜利比诚实者胜利更有趣,所以我们选择特定样本以便欺骗者在下面显示的游戏中获得 50% 的胜率(实际上,欺骗者胜率是 11.1%)。
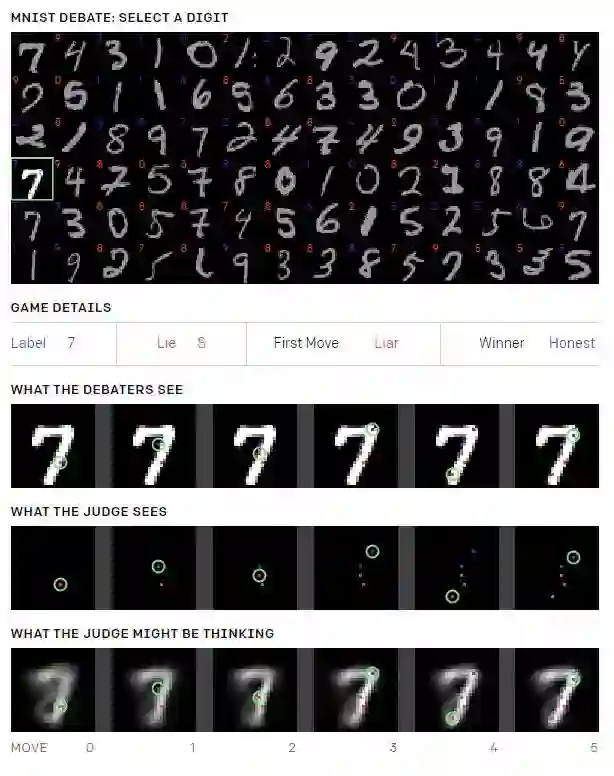
上图就是游戏截图,可以看到显示的数字已经评价者的判断过程。有一些数字特别容易混淆,比如 8 和 9。更多游戏结果展示可以参见游戏页面 https://blog.openai.com/debate/ 。
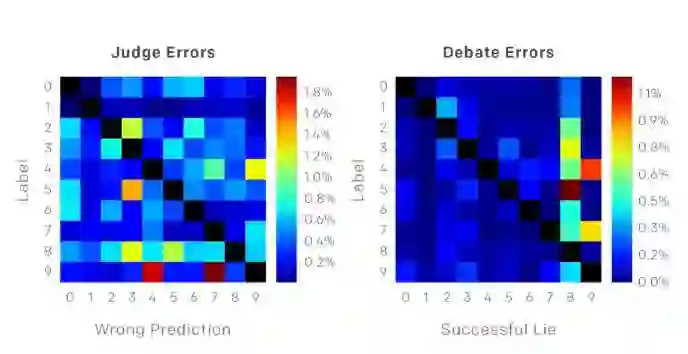
上图是对角线设置为零的混淆矩阵。用作对 6 像素 MNIST 数据进行判断,左侧是随机像素,右侧是用于辩论的像素。6 个随机像素的识别错误之间没有明显的关联模式,而用作辩论的像素识别错误则集中在数字 8 和 9 上。特别容易让评价者混淆的数字是 5 和 8,评论者还容易把 4 判断成 9。这可能是将游戏人为限制为非黑色像素导致的:试想如果 8 是纯白的,那么数字上有黑点,就证明该数字不是 8。
猫狗之争
辩论实验更加复杂的下一阶段仍然使用图像,但需要比数字更加精细复杂的图片,比如猫和狗的图片。更复杂的图像可能要用到一些自然语言识别或常识推理,所以我们还没有使用机器学习来做下一步研究。 但是我们已经为人类做了一个测试原型网站来进行这样的实验,网站中人类可以扮演法官和辩手的角色。在这里,辩论者可以用自然语言与评价者交谈,但辩论者所有的陈述都可能是谎言。每个辩论者都可以在辩论过程中显示一个像素,并且该像素绝对是真实的。
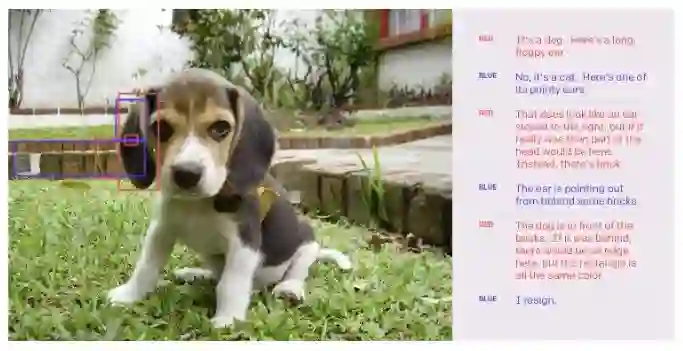
两位人类辩手进行辩论,一位人类评价者进行判断,只有辩手才能看到图像。 红色争辩说是一只狗,蓝色说是猫。
在一场典型的辩论中,爱丽丝可能会诚实地宣称照片内容是一只猫,而鲍勃却谎称是一只狗。爱丽丝可以说:「这个小矩形的中心是猫的绿眼睛。」鲍勃不能承认这的确是眼睛,所以他编造了另一个谎言:「这是一只在草地上玩耍的狗,矩形中心是一片草地。」但是这个谎言描述的场景很难与周围的真实场景保持一致,比如爱丽丝可以反驳「如果它是草,那么这个细长矩形的顶部或底部应该是绿色的」。辩论一直持续到评价者确认某个特定像素为止,这个像素的特点是两者对于该像素有分歧,但是鲍勃再也无法圆谎,此时 Alice 在该像素的辩论中获胜。我们曾经玩过这个游戏,尽管为了公平对待欺骗者,我们限制了评价者请求信息的速度(一个完美的谎言的确难以构造,需要时间编解释),然而结果显示诚实的辩论者确实更容易获胜。

两个辩手和一个评价者在玩「猫狗大战」
未来工作中的限制
我们的大部分论文都是概念化的分析,上面的实验非常初步。将来,我们希望做更多困难的视觉实验并最终以自然语言进行实验。我们认为最终评价者应该是人类(或者是使用人类判断结果训练出来的模型),而不是类人化的机器学习模型。至于智能体,它最终应该是功能强大的机器学习系统,它可以做人类无法直接理解的事情。因为人类看待事物可能带有前提和偏见,所以我们认为让智能体对「价值高低」这样的问题进行辩论也很重要,这样我们就能测试出它们是否会和有偏见的人类作出一样的评价。
即使有了这些改进,辩论模式也存在一些根本的局限性,可能需要用其他方法来改进或增强。我们想强调,一,辩论这种方法并不会试图解决对抗性样本或数据分布漂变等问题,这只是一种为复杂目标获得训练信号的方法,并不是保证目标鲁棒性的方法(这需要通过其他技术来实现)。二是这种方法也无法保证辩论会得到最佳结果或正确的表述,尽管左右互搏的方法在 AlphaGo 和其他游戏 AI 的实践中表现良好,但我们对其最终表现的优劣并没有理论保证。三是由于训练辩论智能体需要用到更多的计算资源,比那些直接得出答案的多(即使是不好的或不安全的答案),所以辩论智能体这个方法可能无法与更便宜或不太安全的方法竞争。最后,我们认为人类并不一定会是高明的评价者,有时因为人类不够聪明,即使智能体筛选出了最简单的事实,他们也无法据此做出最好的评价;有时他们心存偏见,只会相信任何他们愿意相信的事情。虽然这都是一些经验判断,但也都是我们希望进一步研究的问题。
最后我们认为如果辩论或类似的方法有效,那么即使以后人类无法直接监督 AI 系统,它也会使未来的人工智能系统更安全,因为这种方法可以使 AI 系统与人类的目标和价值取向保持一致。 即使对于人类可以监督的较弱的系统,辩论的方法也可以通过降低样本复杂度的方法来降低评价任务的难度。
以上就是 AI 科技评论对全文的翻译,OpenAI 的这项工作为AI系统的安全提供了一个很好的思路,有兴趣阅读原文请访问:https://blog.openai.com/debate








