18篇「AAAI2021」最新论文抢先看!看人工智能2021在研究什么?


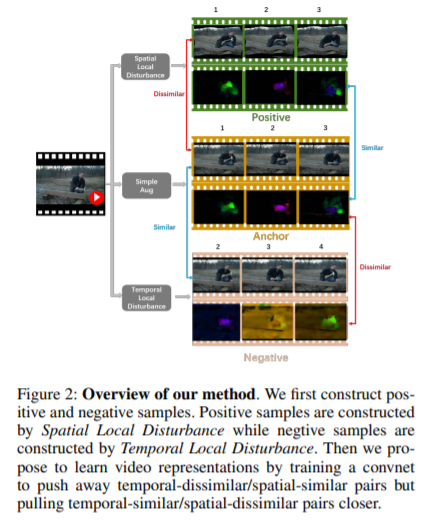
相比于图像表征学习,视频表征学习中的一个重要因素是物体运动信息(Object Motion)。然而我们发现, 在当前主流的视频数据集中, 一些动作类别会和发生的场景强相关, 导致模型往往只关注了场景信息。比如,模型可能仅仅因为发生的场景是足球场,就将拉拉队员在足球场上跳舞的视频判断成了踢足球。这违背了视频表征学习最初的目的,即学习物体运动信息,并且不容忽视的是,不同的数据集可能会带来不同的场景偏见(Scene Bias)。为了解决这个问题, 我们提出了用两个简单的操作来解耦合场景和运动(Decoupling the Scene and the Motion, DSM),以此来到达让模型更加关注运动信息的目的。具体来说, 我们为每段视频都会构造一个正样本和一个负样本,相比于原始视频, 正样本的运动信息没有发生变化,但场景被破坏掉了,而负样本的运动信息发生了改变,但场景信息基本被保留了下来。构造正负样本的操作分别叫做Spatial Local Disturbance和Temporal Local Disturbance。我们的优化目标是在隐空间在拉近正样本和原始视频的同时,推远负样本。用这种方式,场景带来的负面影响被削弱掉了,而模型对时序也变得更加敏感。我们在两个任务上,用不同的网络结构、不同的预训练数据集进行了实验验证,发现我们方法在动作识别任务上,在UCF101以及HMDB51数据集上分别超越当前学界领先水平8.1%以及8.8%。

https://www.zhuanzhi.ai/paper/df9fd0ff594591c5d35b4b679836d2ff
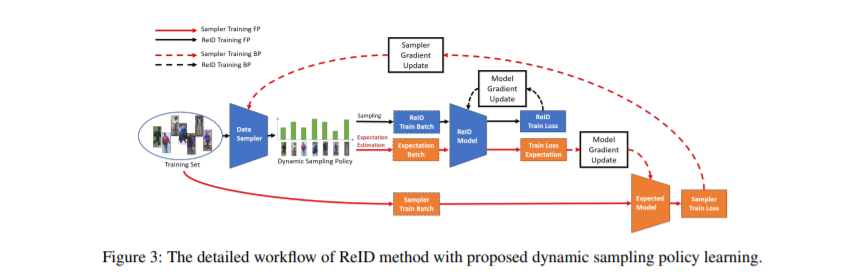
现有行人重新识别(ReID)模型的训练目标是在当前批次样本上模型的损失减少,而与其他批次样本的性能无关。它将不可避免地导致模型过拟合到某些样本(例如,不平衡类中的头部数据,简单样本或噪声样本)。目前有基于采样的方法通过设计特定准则来选择特定样本来解决该问题,这些方法对某些类型的数据(例如难样本,尾部数据)施加了更多的关注,这不适用于真实的ReID数据分布。因此,本文将所选样本的泛化能力作为损失函数,并学习一个采样器来自动选择可泛化样本,而不是简单地推测哪些样本更有意义。更重要的是,我们提出的基于可泛化能力的采样器可以无缝集成到ReID训练框架中,该框架能够以端到端的方式同时训练ReID模型和采样器。实验结果表明,该方法可以有效地改善ReID模型的训练,提高ReID模型的性能。
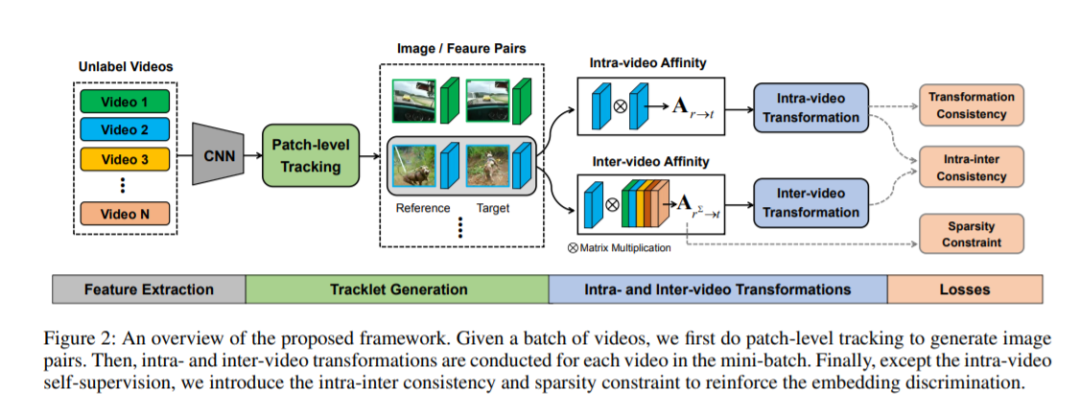
3. 自监督对应学习的对比转换,Contrastive Transformation for Self-supervised Correspondence Learning

https://www.zhuanzhi.ai/paper/449c58a142a4110ee7f089d12b51fdac
4. 小样本学习多标签意图检测

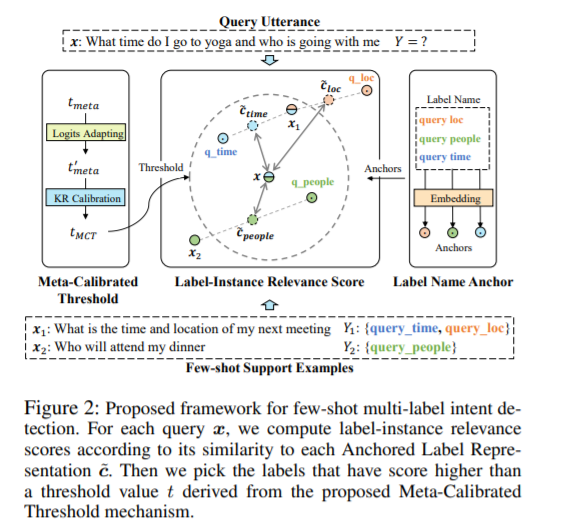
小样本学习(Few-shot Learning)近年来吸引了大量的关注,但是针对多标签问题(Multi-label)的研究还相对较少。在本文中,我们以用户意图检测任务为切入口,研究了的小样本多标签分类问题。对于多标签分类的SOTA方法往往会先估计标签-样本相关性得分,然后使用阈值来选择多个关联的标签。 为了在只有几个样本的Few-shot场景下确定合适的阈值,我们首先在数据丰富的多个领域上学习通用阈值设置经验,然后采用一种基于非参数学习的校准(Calibration)将阈值适配到Few-shot的领域上。 为了更好地计算标签-样本相关性得分,我们将标签名称嵌入作为表示(Embedding)空间中的锚点,以优化不同类别的表示,使它们在表示空间中更好的彼此分离。 在两个数据集上进行的实验表明,所提出的模型在1-shot和5-shot实验均明显优于最强的基线模型(baseline)。
https://www.zhuanzhi.ai/paper/caf3b2b72106ee93d00ddbe2416c4e1a
5. 组合对抗攻击,Composite Adversarial Attacks

https://www.zhuanzhi.ai/paper/4594af42d79efb3a1090149653d332e6

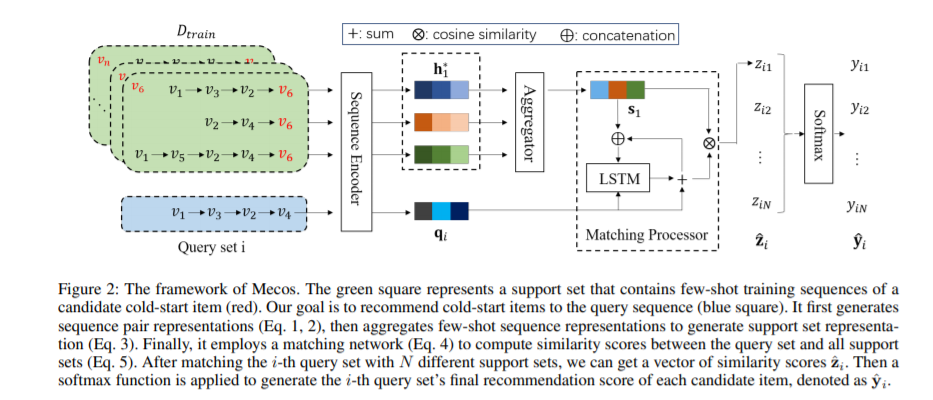
6. 元学习器的冷启动序列推荐,Cold-start Sequential Recommendation via Meta Learner

https://www.zhuanzhi.ai/paper/9e994364361a8060ccdd8be25b4398fd
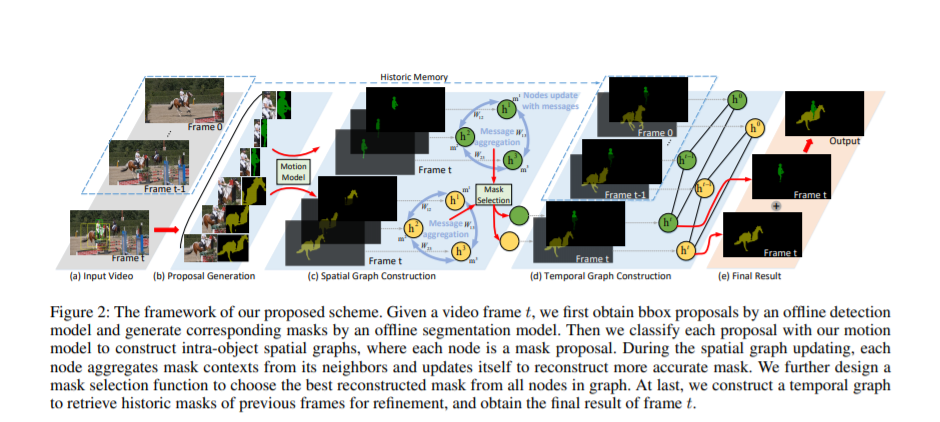
7. 基于时空图神经网络的视频对象分割掩模重构,Spatiotemporal Graph Neural Network based Mask Reconstruction for Video Object Segmentation

地址:
https://www.zhuanzhi.ai/paper/9e3f128d37d0f1d1ae98fbcc2214944c
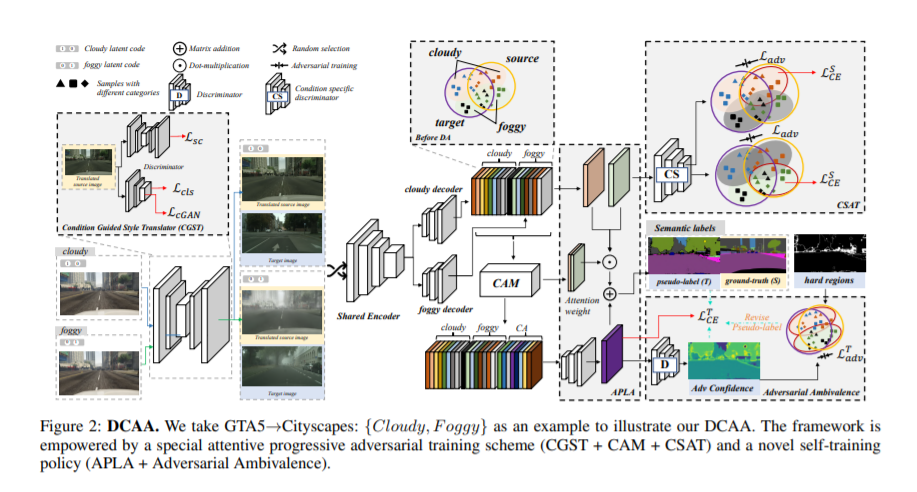
8. 领域自适应分割,Exploiting Diverse Characteristics and Adversarial Ambivalence for Domain Adaptive Segmentation

https://www.zhuanzhi.ai/paper/6a312cb480135d0521a9d9f5f6bbdc7c
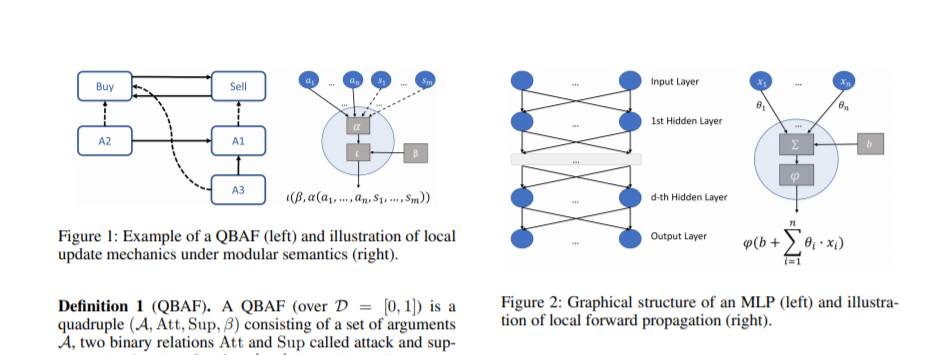
9. 将神经网络解释为定量论证框架,Interpreting Neural Networks as Quantitative Argumentation Frameworks

https://www.zhuanzhi.ai/paper/13e1eff13ab19fb000dd1c601b6b2972
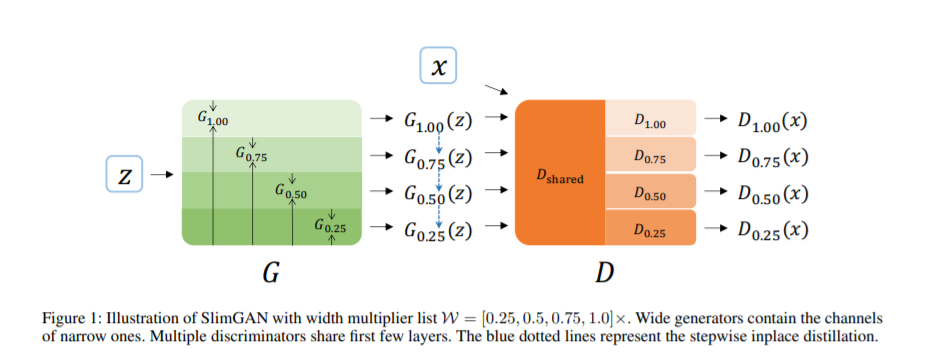
10. “可瘦身”的生成式对抗网络,Slimmable Generative Adversarial Networks

生成式对抗网络(GANs)近年来取得了显著的进展,但模型规模的不断扩大使其难以在实际应用中广泛应用。特别是对于实时任务,由于不同的计算能力,不同的设备需要不同大小的模型。在本文中,我们引入了“可瘦身”的GANs (slimmable GANs),它可以在运行时灵活地切换生成器的宽度(层的通道)以适应各种质量和效率的权衡。具体地说,我们利用多个部分参数共享判别器来训练“可瘦身”的生成器。为了促进不同宽度的生成器之间的一致性,我们提出了一种逐步替代蒸馏技术,鼓励窄的生成器向宽的生成器学习。至于类条件生成,我们提出了一种可分割的条件批处理规范化,它将标签信息合并到不同的宽度中。我们的方法通过大量的实验和详细的消融研究得到了定量和定性的验证。
https://www.zhuanzhi.ai/paper/fa7ad514cd791febd587068de1a7a6f5
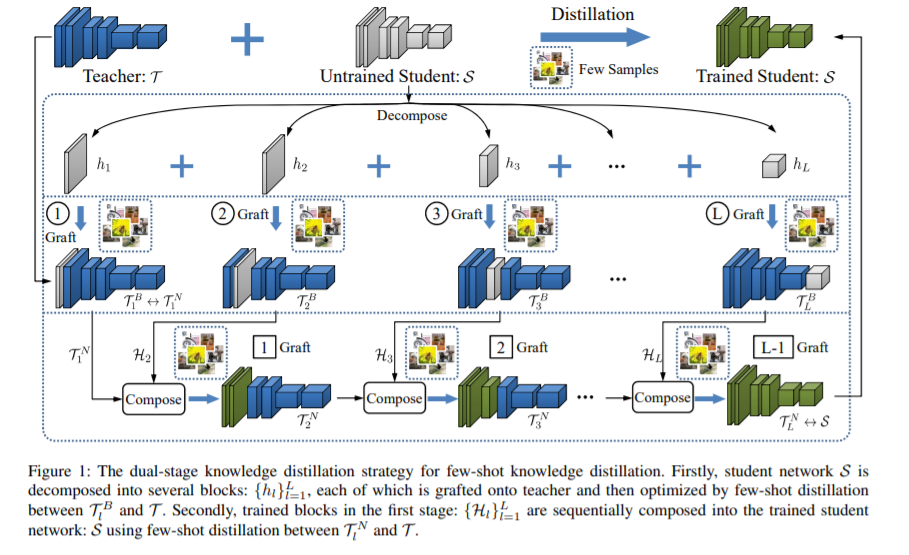
11. 少样本知识蒸馏,Progressive Network Grafting for Few-Shot Knowledge Distillation

https://www.zhuanzhi.ai/paper/63f75c9b913c204181b495ba440cc9f5
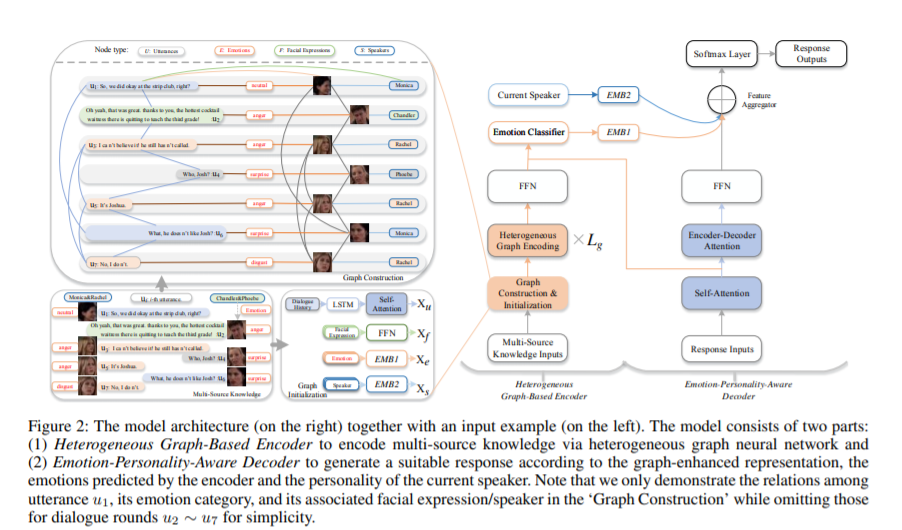
12. 用异构图神经网络注入多源知识进行情感会话生成,Infusing Multi-Source Knowledge with Heterogeneous Graph Neural Network for Emotional Conversation Generation

https://www.zhuanzhi.ai/paper/27a8426b488cac9202ac642ce0625318
13. 自然语言处理中经典的主题模型LDA针对规避攻击的脆弱性,EvaLDA: Efficient Evasion Attacks Towards Latent Dirichlet Allocation

https://www.zhuanzhi.ai/paper/cd0c035fe877c46be9ae21fdce3f5963

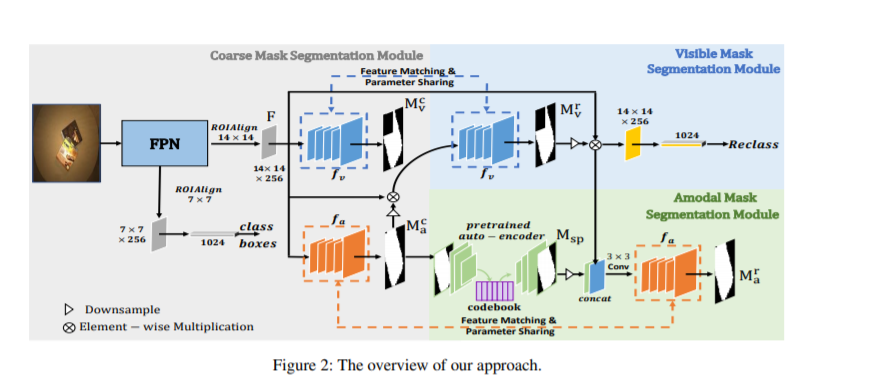
14. 非可见区域分割,Amodal Segmentation Based on Visible Region Segmentation and Shape Prior

https://www.zhuanzhi.ai/paper/25abd8be695165f479e9abd9305fd2fa
本文针对非可见区域分割问题,我们提出在粗糙可见光和非可见掩模的基础上,引入可见光区域和形状先验来推理非可见区域的统一框架。形状先验的引入使得非可见分割更加稳健。我们提出的模型在三个数据集上均优于现有方法。
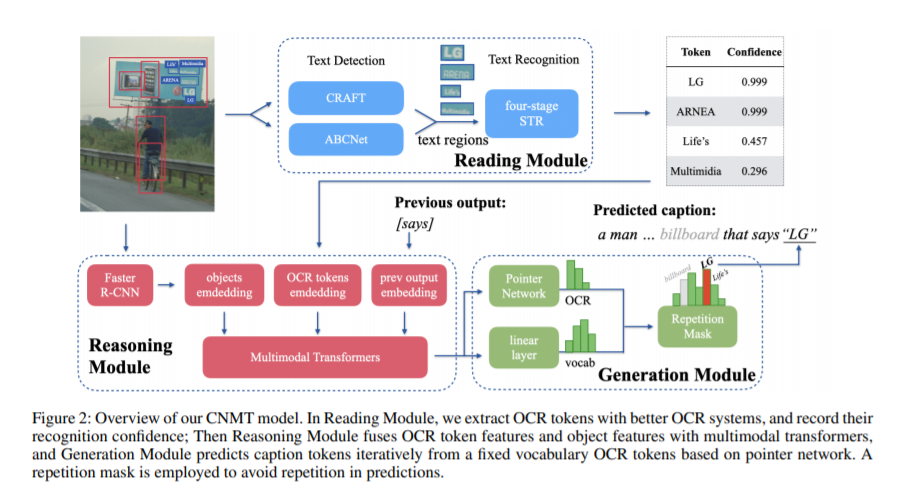
15. 非重复多模态Transformer,Confidence-aware Non-repetitive Multimodal Transformers for TextCaps

https://www.zhuanzhi.ai/paper/5e39735d44cf3e82c8738e4da7e2840a
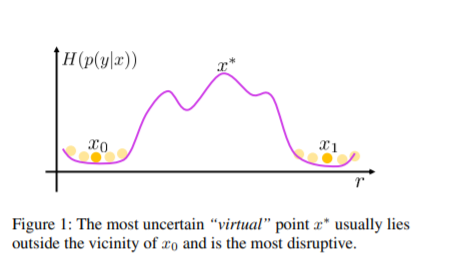
16. 带变分贝叶斯推理和最大不确定性正则化的半监督学习,Semi-Supervised Learning with Variational Bayesian Inference and Maximum Uncertainty Regularization

https://www.zhuanzhi.ai/paper/03927342b31ecbd7143b07c7b5c26614
17. 近似梯度下降的学习图神经网络,Learning Graph Neural Networks with Approximate Gradient Descent

本文首先给出了一种学习节点信息卷积隐含层的图网学习算法。根据标签是附着在节点上还是附着在图上,研究了两种类型的GNN。在此基础上,提出了一个完整的GNN训练算法收敛性设计和分析框架。该算法适用于广泛的激活函数,包括ReLU、Leaky ReLU、Sigmod、Softplus和Swish。实验表明,该算法保证了对基本真实参数的线性收敛速度。对于这两种类型的GNN,都用节点数或图数来表征样本复杂度。从理论上分析了特征维数和GNN结构对收敛率的影响。数值实验进一步验证了理论分析的正确性。
https://arxiv.org/pdf/2012.03429.pdf

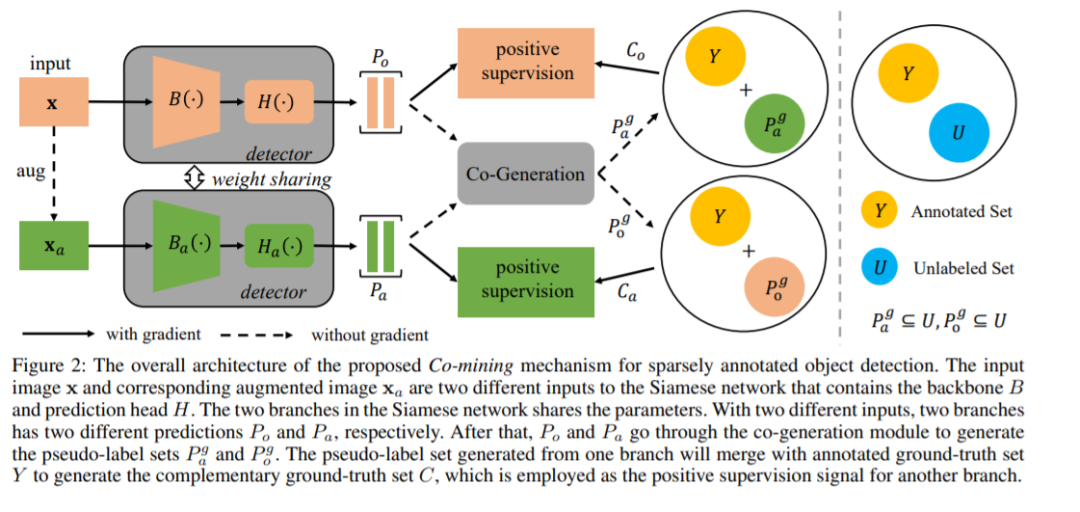
18. 协同挖掘:用于稀疏注释目标检测的自监督学习,Co-mining: Self-Supervised Learning for Sparsely Annotated Object Detection

目标检测器通常在完全标注实例的监督学习情况下获得很好的结果。但是,对于稀疏实例注释,它们的性能远远不能令人满意。现有的稀疏标注目标检测方法主要是对难的负样本的损失进行重加权,或者将未标注的实例转换为忽略区域,以减少假阴性的干扰。我们认为这些策略是不够的,因为它们最多可以减轻由于缺少注释而造成的负面影响。在本文中,我们提出了一个简单而有效的机制,称为协同挖掘,稀疏标注的目标检测。在协同挖掘中,一个连体网络的两个分支相互预测伪标签集。为了增强多视图学习和更好地挖掘未标记实例,将原始图像和相应的增强图像分别作为Siamese网络的两个分支的输入。协同挖掘可以作为一种通用的训练机制,应用于大多数现代目标检测器。在三种不同稀疏注释设置的MS COCO数据集上进行了实验,使用两种典型的框架:基于锚的检测器RetinaNet和无锚检测器FCOS。实验结果表明,与RetinaNet的协同挖掘方法相比,在相同的稀疏标注设置下,相比于不同的基线,改进了1.4%~2.1%,超过了现有的方法。
https://www.zhuanzhi.ai/paper/26fe94a8c64fbb5140619ab72ed036d1
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“AAAI2021” 就可以获取《18篇AAAI2021的论文pdf》专知下载链接





