摆脱 JS 框架,5 年 Web 组件开发经验总结

作者 | Joe Gregorio
译者 | 王强
编辑 | Yonie
大约 5 年前开始我就不再用 JS 框架了,最近 Jon Udell 问我近况如何:
译文:4 年前 bitworking 提议:”别再用 JS 框架了,转向可复用、可正交组合的 HTML+CSS+JS 单元吧。“我很好奇这些年你在这方面积累了哪些经验,有了哪些想法和实践呢?
这几年我零零碎碎写过一些进展,现在既然 Jon 问到了,我觉得有必要把这些总结成一篇文章概括一下。
过去的五年中,我和我的团队一直在用 Web 组件来构建我们的 Web UI。我写下零框架宣言后,我们将所有开发工作都转移到了 Polymer。
我们一开始用的是 Polymer 0.5,因为当时它是最接近可用的 Web 组件的。在我写下零框架宣言时,Web 组件的相关规范还处于标准提议阶段,只有 Chrome 原生实现了其中的一些规范。我们紧跟 Polymer 的步伐,将我们所有的应用程序都迁移到了 Polymer 0.8,等到 Polymer 1.0 发布后也紧跟着升级了。这样一来我们就充分体验了 Web 组件的构建流程,并证明构建 HTML 元素是一条可行的 Web 开发路径。
在谈到零框架时人们经常会发问:不用框架怎么能将应用程序拼接在一起?简单的回答就是:“像你拼接原生元素那样做就行”,但我觉得应该逐一介绍具体的元素拼接方式,这样很有趣,也颇具教育意义。
不管是原生还是自定义元素之间都有六个接触面,或者说接触点,你在拼接它们时能用到这些点。
先来解释一下后文需要用到的术语和涉及的范围。提到范围,注意我们只讨论 DOM,不探讨组装 CSS 或 JS 模块的策略。至于术语这方面,我所说的 DOM 指的是元素的 DOM 接口,而不是元素标记。请注意标记元素和 DOM 接口之间有一点差异。
例如,<img data-foo="5" src="https://example.com/image.png"/>可能是一张图片的标记。对应的 DOM 接口具有 src 属性,其值为 https://example.com/image.png;但 DOM 接口没有 data-foo 属性,所有 data-* 属性都可通过 DOM 接口上的 dataset 属性获取。在 WhatWG 现行标准的术语中它们分别算作内容属性和 IDL 属性,而我要谈的只是 IDL 属性。
准备工作完成了,下面我们就来逐一分析这六个接触面。
头两个接触面可能是最显眼的,它们就是属性和方法。如果你正在和一个元素交互,通常会读取或写入属性值:
element.children或调用元素方法:
document.querySelector('#foo');技术层面来看这些都是一回事,因为它们只是类型不一样的属性而已。原生元素有自己已定义的属性和方法;对于自定义元素来说,它从哪个元素派生而来就会继承基础元素的属性和方法,此外还有自定义的元素和方法。
接下来的两个接触面是事件。事件实际上是两个接触面,因为元素可以监听事件,
ele.addEventListener(‘some-event’, function(e) { /* */ });并且元素可以调度自己的事件:
ele.addEventListener(‘some-event’, function(e) { /* */ });最后两个接触面是 DOM 树中的位置,它也算两个面,因为每个元素都有一个父元素,并且可以是另一个元素的父元素。是的,一个元素也能有兄弟姐妹,但这样就成七个接触面了,听起来不如六个面吉利。
<button><img src=""></button>
来看一个相对简单但功能强大的例子,也就是'sort-stuff'元素。这是一个自定义元素,允许用户对元素排序。所有具有'data-key'属性的'sort-stuff'子项用来对子元素排序,这些子元素是用 sort-stuff 的'target'属性指明的。来看下面的用法示例:<sort-stuff target='#sortable'><button data-key=one>Sort on One</button><button data-key=two>Sort on Two</button></sort-stuff><ul id=sortable><li data-one=c data-two=x>Item 3</li><li data-one=a data-two=z>Item 1</li><li data-one=d data-two=w>Item 4</li><li data-one=b data-two=y>Item 2</li><li data-one=e data-two=v>Item 5</li></ul>
如果用户按下“Sort on One”按钮,则 #sortable 的子项按其 data-one 属性的字母顺序排序。如果用户按下“Sort on Two”按钮,则 #sortable 的子项按其 data-two 属性的字母顺序排序。
以下是'sort-stuff'元素的定义:
window.customElements.define('sort-stuff', class extends HTMLElement {connectedCallback() {Array.from(this.querySelectorAll('[data-key]')).forEach(ele => ele.addEventListener('click', this));}handleEvent(e) {let target = document.getElementById(this.getAttribute('target'));let elements = [];let children = target.children;for (let i=0; i<children.length; i++) {elements.push({value: children[i].dataset[e.target.dataset.key],node: children[i],});}elements.sort((x, y) => (x.value == y.value ? 0 : (x.value > y.value ? 1 : -1)));elements.forEach(function(i) {target.appendChild(i.node);});}});
然后是上面代码的运行示例:

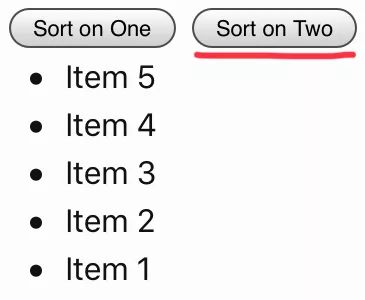
sort-stuff 有一个'target' 属性 ,用来选择要排序的元素。
目标子项具有数据属性 ,是元素排序的根据。
sort-stuff 从其子项注册“click”事件。
sort-stuff 子项具有数据属性,用于确定目标子项的排序方式。
此外还可以添加一个自定义事件'sorted',让'sort-stuff'在每次排序时生成这个事件。
用了 Polymer 这么多年之后,我们研究了一下 Polymer 2.0、3.0 之后的发展规划,发现它可能和我们想要的东西渐行渐远。
我们放弃 Polymer 有几个原因。一开始用 Polymer 是拿它做新标准的实验平台,现在依旧如此;它在这方面表现很好,因为他们能向标准委员会提供具体的反馈,并让人们了解提议的这些标准对开发有什么帮助。但使用新生技术也有缺点,因为有时这些东西不会成为标准。例如 HTML Import 就是 Polymer 1.0 的功能,它深刻影响了你编写元素的方式;结果当 HTML Import 未能成为标准时,你要么整体迁移到 ES 模块上,要么在 Web 应用剩下的生命周期中一直使用对应 HTML Import 的 polyfill。在 Polymer 3.0 中 CSS mixin 也有同样的遭遇。
Polymer 的一些实现方式我也不能苟同,Shadow DOM 的默认用法就是一个例子。Shadow DOM 可以用来封装自定义元素的子元素,使它们不用参与 querySelector() 和普通的 CSS 样式等。但是有几个问题,第一个是当使用 Shadow DOM 时你失去了全局更改样式的能力。如果你突然决定在应用程序中添加“黑暗模式”,那就得逐个修改每个元素的 CSS 了。另外它本该更快一些的,但由于每个元素都包含 CSS 的副本,因此存在性能损失——虽说人们正在设法解决这个问题。
Shadow DOM 这个方案其实会带来更多问题,而 Polymer 默认使用 Shadow DOM,你也可以选择改用 Light DOM;我觉得默认方法不应该选这条路。
最后,Polymer 的数据绑定有一些误区。它提供了双向数据绑定,这绝不是一个好主意,因为只要是双向数据绑定就迟早会出错。数据绑定有很多好处,理论上你只需更新模型,Polymer 将来就会用更新的值重新渲染你的模板。“将来”的意思是更新是异步的,理论上异步工作可以批量更新提高效率。但实际情况是你花费了大量的开发时间来更新模型,结果 DOM 却不动如山,让你抓狂;最后你要么调用强制同步渲染的函数,或者原因出在你更新的是模型的深层部分,并且 Polymer 无法观察到这种变化,所以你需要在代码里加上 set() 方法给出模型中刚刚更新的那部分的路径。对于简单的应用程序来说异步渲染和数据观察很好用,但对于更复杂的应用来说,这种方法会浪费开发人员的时间来做调试,还不如用更简单的数据绑定模型。
值得注意的是 Polymer 团队还提供了 lit-html 库,它只是一个模板库,使用模板字面量和 HTML 模板来提高渲染效率;这个库并没有涉及我上面指出来的这些问题。
于是我开始使用一个非常实际、数据驱动的极简主义方法。首先确定我们真正需要哪些基本元素,然后确定在构建这些元素时我们需要哪些库功能,最后确定在构建完整成熟的应用程序时需要从这些基本元素中发展出哪些功能。也许我们根本用不着异步渲染或 Shadow DOM,那就不用它们;我们会在构建现实应用的过程中判断哪些功能才是我们真正想要的。
第一步是确定我们真正需要哪些基本元素。Polymer 提供的 iron-*和 paper-*元素库太大了,我们自己做替代品也不太可能,所以我回顾了一下过去几年来我们用 Polymer 编写的代码,来确定哪些元素是我们确实需要的。如果我们现在开始做这项工作的话可能就会用 Elix 之类的纯 Web 组件库了,但当初我们没有这一类选择可用。
我做的第一件事是检查每个项目并记下各个项目中使用的所有 Polymer 元素。如果我要替换 Polymer,至少应该知道有多少元素需要重写。列出来的单子在很多方面都出乎意料,首先就是这个列表其实很短:

用 Polymer 开发了四年时间,我本以为这个列表会很长的。
第二个惊喜是这个列表中有很多元素根本就用不着。例如有些元素可以用精心调整样式的原生元素替换,比如说用 button 替换 paper-button。还有些可以用 CSS 或非元素方案替换,例如 iron-ajax 就可以抛弃,应该用 fetch() 函数替换。经过分析研究,放弃 Polymer 后需要重新实现的元素就变得很少了。
在下表中,“Native”一列中我们可以用调好样式的原生元素替代;“Use Instead”一列是我们可以用来代替自定义元素的选项。这里你会注意到很多元素都可以用 CSS 替换。最后一列“Replacement Element”是我们用来替换 Polymer 元素的元素名称:
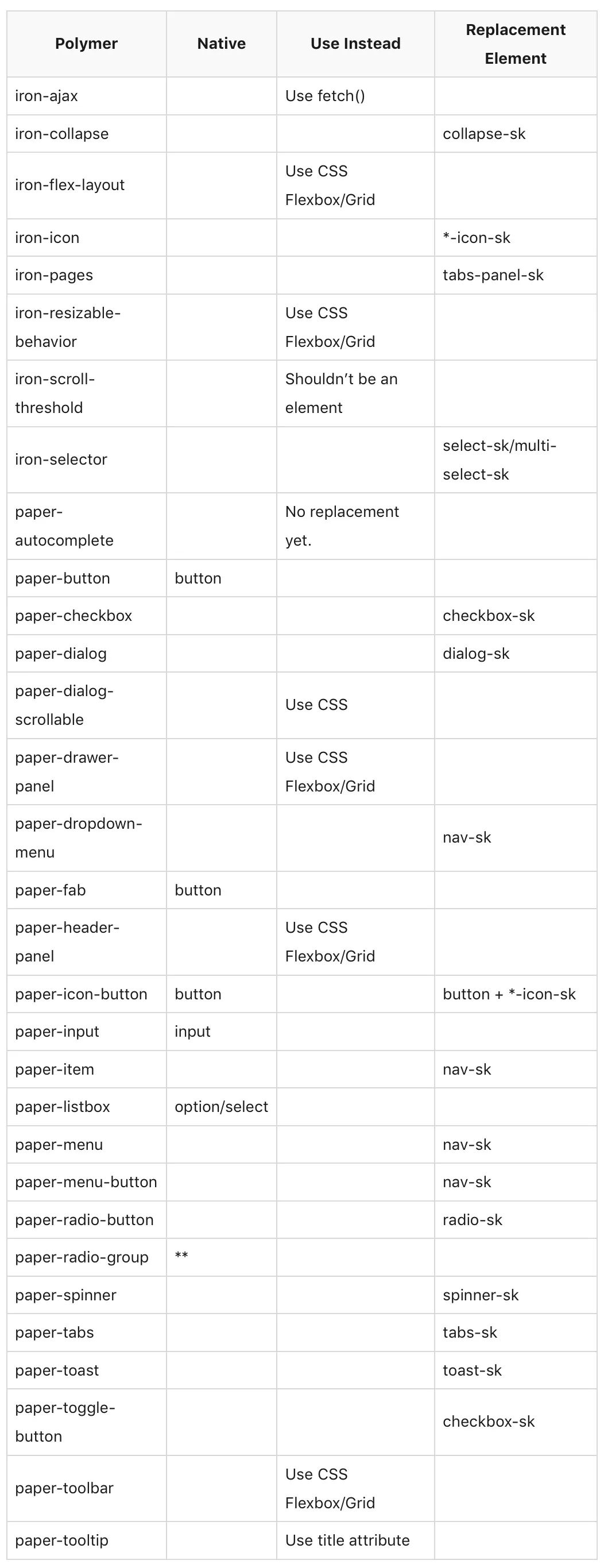
** 对于 radio-sk 元素来说只需设置一个通用名称,就像使用原生单选按钮一样。
这组最小自定义元素现在已经发布为 elements-sk。
现在我们已经有了基本的元素列表,该考虑一下我们需要的其他工具和技术了。
框架
模型
工具和结构
元素
模板
状态管理
这些东西都很美好,但为什么它们非得打包在一起卖出去呢?如果我们将框架的这些内容拆分独立开来,就可以在开发应用程序时选择各类实现了。这种开发方法我们叫做“点菜”式 Web 开发。
你只需选择所需的内容即可,但 Web 框架只能选择单一的解决方案。下面我列举了组件要进入 Web 开发“点菜”的菜单需要满足哪些标准。
“点菜”式 Web 开发摆脱了框架,只使用浏览器获取模型,你来根据需要挑选剩下的内容。在点菜式开发中,每道菜都是一份独立的软件:
定义项目如何组合在一起的目录结构,并为项目提供符合该结构的 JS 转换、CSS 前缀等工具。ES 模块和扩展应当兼容 webpack、rollup 等工具,例如为了导入其他类型的文件可以使用 webpack loaders。
ES6 模块中的 v1 自定义元素库。请注意,这些元素必须在 ES6 模块中提供,模块和扩展兼容 webpack、rollup 等工具,例如为了导入其他类型的文件可以使用 webpack 加载器。元素也应该是“整洁的”,只有 HTML、CSS 和 JS。
你喜欢的模板库都能用,只要它兼容 v1 自定义元素就行。
需要的话用你喜欢的状态管理库即可。
兼容 webpack、rollup 等工具的 ES6 模块及扩展,例如为了导入其他类型的文件可以使用 webpack 加载器。
基本元素是“整洁”的,只有 JS、CSS 和 HTML。不使用其他库,例如模板库就不用。注意,“整洁”的元素集也符合第一条要求,也就是说它们是兼容 webpack/rollup 的 ES6 模块。
当然还可以有其他规则可以参考,例如 “谷歌开发者指南——自定义元素最佳实践” 就是创建自定义元素集时应该遵循的规范;但对于 Shadow DOM 来说,我建议你除非真的必要否则就别用它了。
这些代码能在支持自定义元素 v1 规范的浏览器中原生运行。要兼容更多浏览器的话你需要添加 polyfill,并根据目标浏览器版本将 JS 编译回旧版本的 ES,并在 CSS 上使用前缀。要兼容的浏览器越多,你要转换的目标版本就越老,需要做的工作也越多,但原始代码不需要更改。只有特定的项目才需要这些额外的步骤。
现在我们有了开发系统,我们已经开始发布其中的一些内容了。
我们发布了 pulito,这是“工具和结构”组件的基本实现。你会发现它不是很复杂,只是个 webpack 配置文件而已。我们也发布了一组“整洁”的自定义元素集合 elements-sk。
现在我们的技术栈是这样的:
pulito: https://www.npmjs.com/package/pulito
elements-sk:https://www.npmjs.com/package/elements-sk
lit-html(https://www.npmjs.com/package/lit-html)我们在一个没发布的实验性应用程序中使用了 Redux,而其他应用中并没有用到状态管理库,所以我们的“状态管理”库还没定下来。
这个技术栈用起来感觉如何呢?我们来从头创建一个 Web 应用:
$ npm init$ npm add pulito
我们是从零开始的,所以使用 pulito 提供的项目骨架:
$ unzip node_modules/pulito/skeleton.zip$ npm
现在可以运行开发服务器,就能看到这个骨架应用了:
$ make serve现在加入 elements-sk,在 UI 里加一些项目
$ npm add elements-sk再向 pages/index.js 导入内容,引入所需的元素:
import 'elements-sk/tabs-sk'import 'elements-sk/tabs-panel-sk'import '../modules/example-element'
在 pages/index.html 上使用这些元素:
<body><tabs-sk><button class=selected>Some Tab</button><button>Another Tab</button></tabs-sk><tabs-panel-sk><div><p> This is Some Tab contents.</p></div><div>This is the contents for Another Tab.</div></tabs-panel-sk><example-element active></example-element></body>
最后重启开发服务器,看看页面更新的效果:
$ make serveWeb 框架通常会为你料理好这一切,你没有其他选择,就算你不需要某些功能也没辙。比如说你可能不需要状态管理,那么为什么你要为它投入资源呢?“投入资源”意味着要了解 Web 框架在这方面的内容,甚至可能必须运行实现状态管理的代码,实际上你根本就用不到它。而在“点菜”式开发中,你只要选择自己需要的那些内容即可。
另一个好处是省掉升级时的很多麻烦。Web 框架从 v1 大规模升级到 v2 时浪费了你多少时间和精力?“点菜”式开发不需要整体升级。比如说如果你想升级模板库,那么只用升级模版库即可,不用动应用的其他内容。
最后,“点菜”式 Web 开发不提供“模型”,而只考虑浏览器。框架提供的各种内容中,“模型”是最成问题的。许多框架都拥有自己的浏览器模型,决定 DOM 如何工作、事件如何工作等等。之前的文章中我深入探讨了这个问题(详情见下方链接),坏处总结起来就是无效的努力(学一些没法通用的内容)和阻碍复用。应该怎么做呢?只需考虑浏览器就行了,它已经有了一个将元素组合在一起的模型,现在又有了自定义元素 v1 使你能够创建自己的元素,你就拥有了所需的一切。
“点菜”式 Web 开发最重要的一点是它解耦了所有组件,这样这些组件的进化和适应用户需求的速度就会比一般的 Web 框架快得多。我们发布的 pulito 和 elements-sk 并不等于最好的解决方案。如果工具、基本元素集、模板和状态管理出现众多选项的话我会很高兴的。我希望看到基于 Rollup 的工具代替 pulito,最好再有一整套“整洁”的自定义元素集,具有不同级别的可定制性和覆盖面。
相关链接:
框架模型问题:
https://bitworking.org/news/2014/05/zero_framework_manifesto
我们在构建更大的应用程序时也在不断学习经验。
lit-html 非常快,我们处理过的所有应用程序更小更快了。调用 render() 函数是很愉快的事情,因为你会知道元素已经被渲染了,不会陷入异步渲染的陷阱。我们还没遇到过异步渲染的需求,但这并不奇怪。我们来考虑一下异步渲染会很有用的场景,也就是批量渲染和异步执行会有很大性能提升的情况。这种情况下元素必须有很多属性,并且属性的每次更改都会改变 DOM 的显示效果,因此需要大量调用 render()。但在我们做过的所有开发工作中这种情况从未出现过;元素的属性都很少。如果一个元素需要显示大量数据,通常是通过将少量复杂对象作为元素的属性传递来实现的,这样渲染负担就很小了。
我们也没有遇到过 Shadow DOM 的需求。实际上我认为 Light DOM 子元素和方法、属性、事件一样都算是元素的“正常”编程接触面。
另一条经验是,在构建应用程序时创建基本元素和更高级别的元素是不一样的。你不会在开发的每一步中都创建安全可复用的元素;级别更高时需要的可复用性和细节也没那么多了。如果一个元素看起来可以在应用程序之间重复使用,那么我们可以收紧元素的接触面并添加更多选项以涵盖更多场景,但这是根据需要做的工作,不是针对所有元素的。高级元素用不着像底层元素那么通用。你可以独立使用 HTML 模板、模板字面量以及其他 Web 组件 API。
原文链接:
https://bitworking.org/news/2019/07/looking-back-on-five-years-of-web-components

点个在看少个 bug 👇





