AI 向善:帮助视障用户通过移动设备实时识别商品

文 / Chao Chen,软件工程师,Google Research
在商店和家中的橱柜里挑选包装食品,是普通人的生活常态,却是视障用户的一大难题。这是因为大多数食品的包装几乎都完全相同,比如同样大小的盒子、瓶子、金属罐和玻璃罐,仅仅容器上标签的文字和图像不同。不过,随着智能移动设备的普及,我们已经有能力运用机器学习 (ML) 解决这一难题。
近年来,设备端神经网络对各种感知任务的准确率有了显著提高。再加上现代智能手机计算能力不断提高,如今许多视觉任务都可在完全运行于移动设备上时产生高性能表现。将 MnasNet 和 MobileNets(基于资源感知架构搜索)等设备端模型开发与设备端索引结合,即可完全在设备端实时运行标签产品识别等完整的计算机视觉系统。
MnasNet
https://ai.googleblog.com/2018/08/mnasnet-towards-automating-design-of.html
最近,我们利用这些开发成果发布了一款名为 Lookout 的 Android 应用,通过计算机视觉帮助视障用户更顺畅地感知物理世界。用户只要将智能手机摄像头对准产品,Lookout 就会识别产品并大声地报出品牌名称和产品尺寸。Lookout 搭载了带有设备端产品索引的超市产品检测和识别模型,以及 MediaPipe (mediapipe.dev) 目标追踪和光学字符识别模型。最终产生的架构非常高效,可以完全在设备端实时运行。
Lookout
https://play.google.com/store/apps/details?id=com.google.android.apps.accessibility.reveal
为什么要在设备端?
完全设备端系统的优势在于低延迟和对网络连接的不依赖。然而,这也意味着一个产品识别系统要想完全派上用场,它的设备端数据库就必须充分覆盖各种产品。正是这些需求推动了 Lookout 所用数据集的设计。Lookout 数据集由两百万种热门产品组成,并且全部根据用户的所在的地理位置动态选择。
传统解决方案
过去,使用计算机视觉的产品识别以 SIFT 等算法提取局部图像特征来解决。这些非 ML 方法的匹配结果相当可靠,但单张索引图像的存储量很大(每张图像通常在 10KB 到 40KB 之间),而且容易受到光线不足和图像模糊的影响。此外,这些描述符由于局部性质,往往不会捕获产品外观等更全局的部分。
另一种方法是使用 ML。ML 方法具有许多优点,在查询图像和数据库图像上运行光学字符识别 (OCR) 系统来提取产品包装上的文字。图像上的文字查询可以通过 N-Grams 与数据库匹配,从而增强对 OCR 错误的判断,比如产品包装上的拼写错误、误识别、文字识别失败等。N-Grams 还可以使用雅卡尔相似系数等量度在查询文档与索引文档之间进行部分匹配,而不是要求完全匹配。当使用 OCR 时,索引文档可能会变得非常大,因为除了在产品包装文字的 N-Grams 之外,还有可能需要存储 TF-IDF 等其他信号。此外,OCR+N-Gram 方法还存在匹配可靠性问题,如果两个不同产品的包装上有大量共用单词,它很容易过度触发。
对比 SIFT 与 OCR+N-Gram 方法,我们的神经网络方法会为每张图像生成一个仅需 64 字节的全局描述符(即嵌入向量),大幅降低了存储需求,比每张图像 10-40KB 的 SIFT 特征索引条目更小,比每张图像几 KB 的 OCR+N-gram 方法更可靠。由于每张索引图像消耗的字节数较少,因此更多产品可以加入索引,实现更完整的产品覆盖和更良好的整体用户体验。
设计
Lookout 系统由帧缓存、帧选择器、检测器、目标追踪器、嵌入器、索引搜索器、OCR、评分器和结果表述器组成。
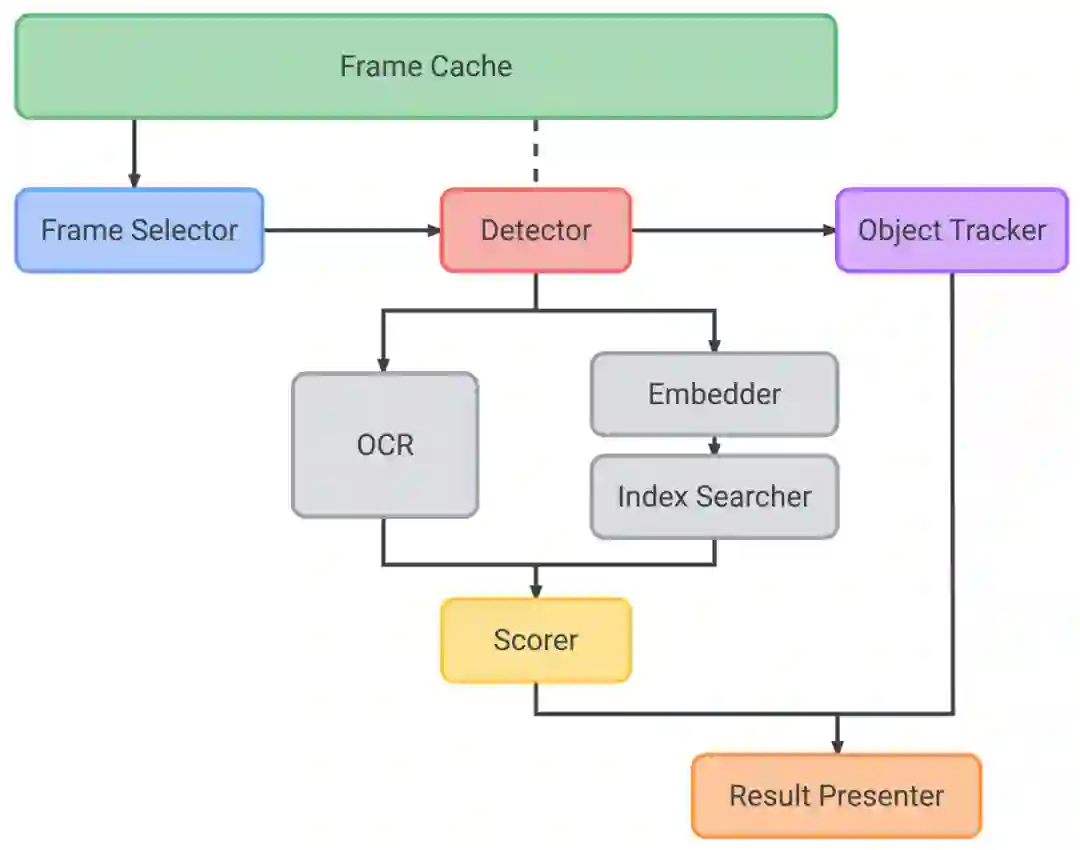
产品识别流水线内部架构
帧缓存管理流水线中输入摄像头帧的生命周期。它根据其他模型组件的请求有效提供数据,包括 YUV/RGB/灰度图像,并管理数据生命周期,避免多个组件请求的同一摄像头帧被重复转换。
当用户将摄像头取景器对准产品,基于 IMU 的轻型帧选择器将作为预筛选阶段运行。它根据角旋转率(度/秒)测量的抖动从连续传入的图像流中选择与特定质量标准(例如,平衡的图像质量和延迟)最匹配的帧。这种方式仅选择性处理高质量图像帧,跳过模糊帧,从而将能耗降到极低水平。
随后,各个选定帧被传递到产品检测器模型,该模型关注帧中的兴趣区域(也称为检测边界框)。检测器模型架构是以 MnasNet 为主干的单发检测器,可同时兼顾高质量与低延迟。
MediaPipe 检测框追踪用于实时追踪检测框,对于填补不同物体检测之间的空白、降低检测频率,从而降低能耗起到了重要作用。目标追踪器还维护着一个目标映射,运行期间,每个目标都被分配一个唯一目标 ID,后续将被 结果表述器用于区分目标,避免重复“表述”单个目标。对于每一个检测结果,追踪器可在映射中注册一个新目标,或者利用现有目标边界框与检测结果之间的交并比 (Intersection over Union) 更新现有目标的边界框。
嵌入器 (Embedder)
兴趣区域 (ROI) 由检测器传送至嵌入器模型,嵌入器模型随后计算出一个 64 维的嵌入向量。嵌入器模型最初是从涵盖了成千上万个类的大型分类模型(即教师模型,基于 NASNet)训练而来。模型中添加了一个嵌入向量层,用于将输入图像投射到“嵌入向量空间”,即向量空间。如果有两个点在空间内接近,就意味着它们表示的图像在视觉上相似(例如,两张图像显示的是同一个产品)。
NASNet
https://ai.googleblog.com/2017/11/automl-for-large-scale-image.html
仅分析嵌入向量可以确保模型足够灵活,并且无需在每次扩展到新产品时重新训练。然而,由于教师模型太大,无法在设备端上直接使用,因此我们采用它生成的嵌入向量来训练一个更小并且对移动设备友好的学生模型。该模型学习的是如何将输入图像在嵌入向量空间中映射到与教师网络相同的点。最后,我们应用主成分分析 (PCA) 将嵌入向量的维度从 256 减少到 64,简化设备端存储的嵌入向量。
索引搜索器使用查询嵌入向量在预建的兼容 ScaNN 索引上执行 KNN 搜索。它将返回排名靠前的索引文档,包含产品名称、包装尺寸等元数据。为了降低索引查找延迟,所有嵌入向量均以 k 均值聚类到簇。查询时,相关数据簇在内存中加载用于实际距离计算。为了在不牺牲质量的前提下缩减索引大小,我们在编制索引时使用了乘积量化。
OCR 会在每个摄像头帧的 ROI 上执行,提取包装盒尺寸、产品口味变体等额外信息。传统解决方案将 OCR 结果用于索引搜索,而在我们的方案中仅被用作评分。由 OCR 文本提供信息的适当评分算法可以协助评分器(如下)确定正确结果并提高精度,特别是在多个产品有相似包装的情况下。
评分器从嵌入向量(带有索引结果)和 OCR 模块中获取输入,对先前检索到的索引文档(通过索引搜索器检索到的嵌入向量和元数据)逐一评分。 评分后的最高结果将用作系统的最终 识别。
结果表述器 (Result presenter)
结果表述器收录以上所有结果,通过文字转语音服务报出产品名称,向用户表述结果。

在瑞士一家超市中进行的设备端产品识别早期实验
未来工作
本文概述的设备端系统可实现一系列全新的店内购物体验,包括产品信息详细显示(营养成分、过敏原等)、客户评分、产品比较、智能购物清单、价格追踪等。我们很期待探索这些未来应用,并将继续研究推进底层设备端模型的质量和稳健性。
致谢
本文所述论文由 Abhanshu Sharma、Chao Chen、Lukas Mach、Matt Sharifi、Matteo Agosti、Sasa Petrovic 和 Tom Binder 撰写。感谢 Alec Go、Alessandro Bissacco、Cédric Deltheil、Eunyoung Kim、Haoran Qi、Jeff Gilbert 和 Mingxing Tan,没有你们的支持和帮助,这项工作不可能完成。
更多 AI 相关阅读:






