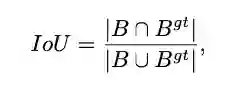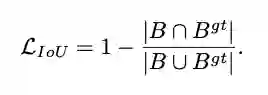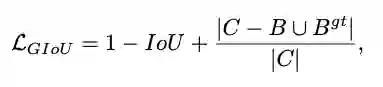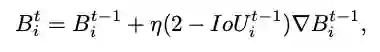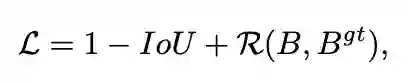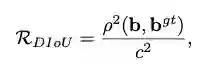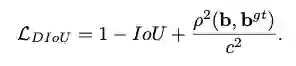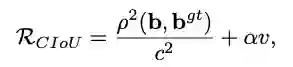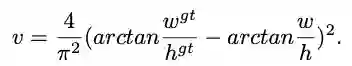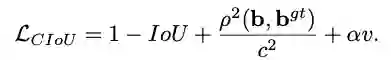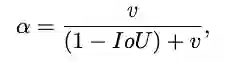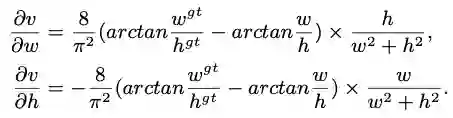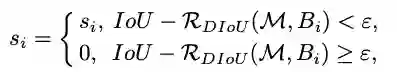![]()
作者 | VincentLee
编辑 | Camel
本文来源于微信公众号:晓飞的算法工程笔记
本文对发表于 AAAI 2020 的论文《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》进行解读。
![]()
论文地址:https://arxiv.org/abs/1911.08287
代码地址:https://github.com/Zzh-tju/DIoU
论文提出了IoU-based的DIoU loss和CIoU loss,以及建议使用DIoU-NMS替换经典的NMS方法,充分地利用IoU的特性进行优化。
并且方法能够简单地迁移到现有的算法中带来性能的提升,实验在YOLOv3上提升了5.91mAP,值得学习。
1、IoU
![]()
IoU是目标检测里面很重要的一个指标,通过预测的框和GT间的交集与并集的比例进行计算,经常用于评价bbox的优劣 。
但一般对bbox的精调都采用L2范数,而一些研究表明这不是最优化IoU的方法,因此出现了IoU loss。
2、IoU loss
![]()
IoU loss顾名思义就是直接通过IoU计算梯度进行回归,论文提到IoU loss的无法避免的缺点:
当两个box无交集时,IoU=0,很近的无交集框和很远的无交集框的输出一样,这样就失去了梯度方向,无法优化。
IoU loss的实现形式有很多种,除公式2外,还有UnitBox的交叉熵形式和IoUNet的Smooth-L1形式。
这里论文主要讨论的类似YOLO的检测网络,按照GT是否在cell判断当前bbox是否需要回归,所以可能存在无交集的情况。
而一般的two stage网络,在bbox regress的时候都会卡
,不会对无交集的框进行回归。
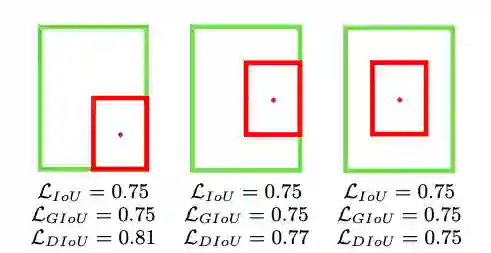
3、GIoU loss
![]()
GIou loss在IoU loss的基础上增加一个惩罚项,
为包围预测框
和
的最小区域大小,当bbox的距离越大时,惩罚项将越大。
尽管GIoU解决了IoU的梯度问题,但他仍然存在几个限制:
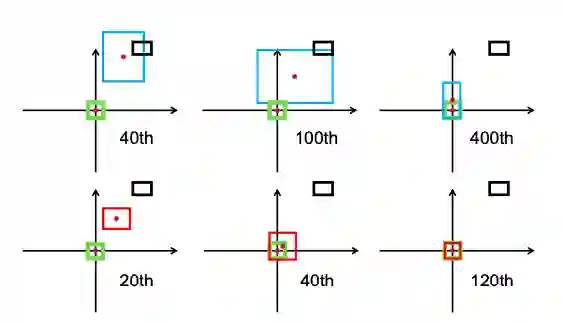
![]()
图 1、边界框回归步骤GIoU损失(第一行)和DIoU损失(第二行)。绿色和黑色分别表示target框和anchor框。蓝色和红色分别表示GIoU损失和DIoU损失的预测框。GIoU损失一般会增加预测框的大小,使其与target框重叠,而DIoU损失则直接使中心点的归一化距离最小化。
如图1所示,在训练过程中,GIoU倾向于先增大bbox的大小来增大与GT的交集,然后通过公式3的IoU项引导最大化bbox的重叠区域。
![]()
图 2、在这种情况下,GIoU的loss会退化为IoU的loss,而DIoU的loss仍然可以区分。绿色和红色分别表示目标框和预测框。
由于很大程度依赖IoU项,GIoU需要更多的迭代次数来收敛,特别是水平和垂直的bbox(后面会分析)。
一般地,GIoU loss不能很好地收敛SOTA算法,反而造成不好的结果。
4、DIoU
综合上面的分析,论文提出Distance-IoU(DIoU) loss,简单地在IoU loss基础上添加一个惩罚项,该惩罚项用于最小化两个bbox的中心点距离。
如图1所示,DIoU收敛速度和效果都很好,而且DIoU能够用于NMS的计算中,不仅考虑了重叠区域,还考虑了中心点距离。
另外,论文考虑bbox的三要素,重叠区域,中心点距离和长宽比,进一步提出了Complete IoU(CIoU) loss,收敛更快,效果更好。
二、对 IoU Loss 和GIoU Loss 的分析
为了全面地分析IoU loss和GIoU的性能,论文进行了模拟实验,模拟不同的距离、尺寸和长宽比的bbox的回归情况。
1、Simulation Experiment
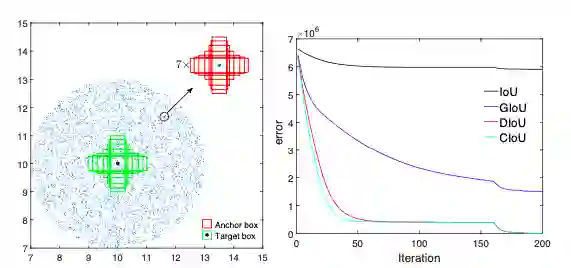
![]()
![]()
图 3、Simulation Experiment
如图3所示,实验选择7个不同长宽比(1:4, 1:3, 1:2, 1:1, 2:1, 3:1, 4:1)的单元box(area=1)作为GT,单元框的中心点固定在(7, 7),而实验共包含5000 x 7 x 7个bbox,且分布是均匀的:
-
Distance:
在中心点半径3的范围内均匀分布5000中心点,每个点带上7种scales和7种长宽比;
-
Scale:
每个中心点的尺寸分别为0.5, 0.67, 0.75, 1, 1.33, 1.5, 2 ;
-
Aspect ratio:
每个中心点的长宽比为1:4, 1:3, 1:2, 1:1, 2:1, 3:1, 4:1。
![]()
给定一个loss函数
,可以通过梯度下降来模拟bbox优化的过程。
对于预测的bbox
,
为
阶段的结果,
为
对
的梯度,使用
来加速收敛。
bbox的优化评价使用
-norm,共训练200轮,error曲线如图3b所示
2、Limitations of IoU and GIoU Losses
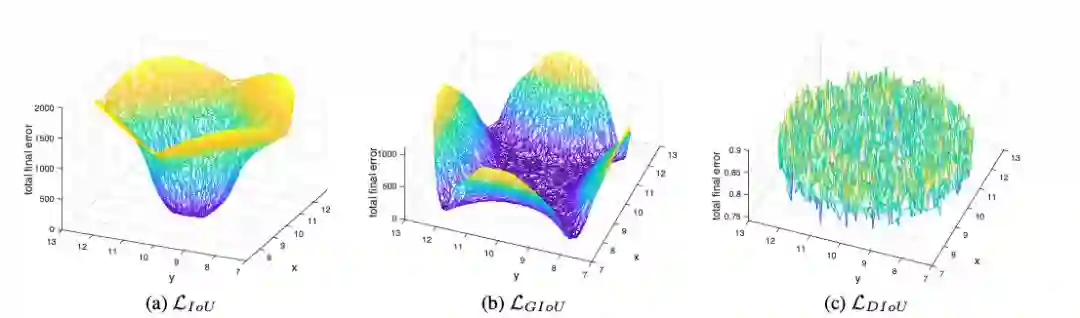
![]()
图 4
论文将5000个中心点上的bbox在最后阶段的total error进行了可视化。
IoU loss只对与target box有交集的bbox有效,因为无交集的bbox的
为0。
而GIoU由于增加了惩罚函数,盆地区域明显增大,但是垂直和水平的区域依然保持着高错误率,这是由于GIoU的惩罚项经常很小甚至为0,导致训练需要更多的迭代来收敛。
三、方法
![]()
一般而言,IoU-based loss可以定义为公式5,
是预测box
和
的惩罚项。
1、Distance-IoU Loss
![]()
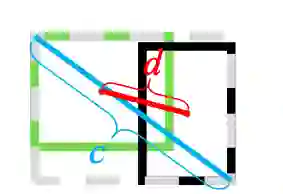
论文提出了能减少两个box中心点间的距离的惩罚项,
和
分别表示
和
的中心点。
是欧氏距离,
是最小包围两个bbox的框的对角线长度。
![]()
![]()
图 5
DIoU loss的惩罚项能够直接最小化中心点间的距离,而GIoU loss意在减少外界包围框的面积 DIoU loss保留了IoU loss和GIoU loss的一些属性:
-
DIoU loss依然是尺寸无关的,不会大尺寸产生大的loss,小尺寸产生小的loss那样;
-
类似于GIoU loss,DIoU loss能够为无交集的bbox提供梯度方向;
-
在模拟实验中,发现DIoU loss也有一些独有的属性:
-
如图1和图3所示,DIoU loss能够直接最小化bbox的中心点距离。
因此,他的收敛很快;
-
在包含的情况下,或垂直和水平的情况下,DIoU loss的收敛非常快,而GIoU loss则几乎退化成了IoU loss。
2、Complete IoU loss
![]()
![]()
论文考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。
其惩罚项如公式8,其中
是权重函数,而
用来度量长宽比的相似性。
![]()
![]()
α 的定义如公式11,重叠区域能够控制权重的大小。
![]()
最后,CIoU loss的梯度类似于DIoU loss,但还要考虑
的梯度。
在长宽在
的情况下,
的值通常很小,会导致梯度爆炸,因此在实现时将
替换成1。
3、Non-Maximum Suppression using DIoU
在原始的NMS中,IoU指标用于抑制多余的检测框,但由于仅考虑了重叠区域,经常会造成错误的抑制,特别是在bbox包含的情况下。
因此,可以使用DIoU作为NMS的标准,不仅考虑重叠区域,还考虑了中心点距离。
![]()
其中
是分类置信度,
为NMS阈值,
为最高置信度的框。
DIoU-NMS倾向于中心点距离较远的box存在不同的对象,而且仅需改几行代码,DIoU-NMS就能够很简单地集成到目标检测算法中。
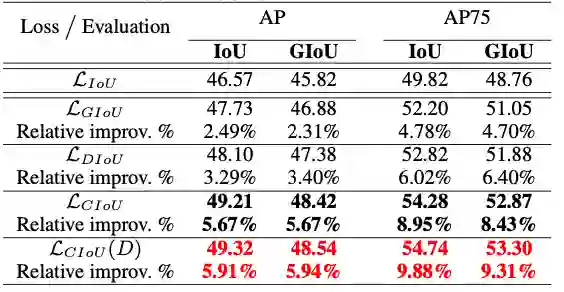
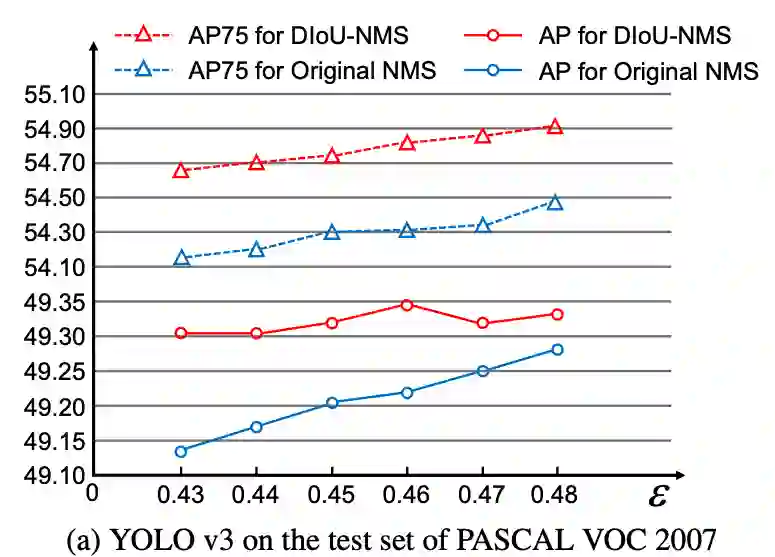
1、YOLO v3 on PASCAL VOC
![]()
在YOLOv3上进行实验对比,DIoU loss和CIoU的效果都很显著,mAP分别提升3.29%和5.67%,而AP75则分别提升6.40%和8.43%,而使用DIoU-NMS则能进一步提升,幅度达到5.91%和9.88%。
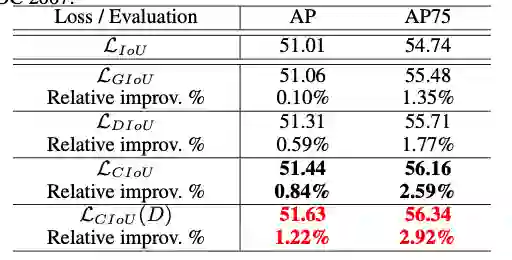
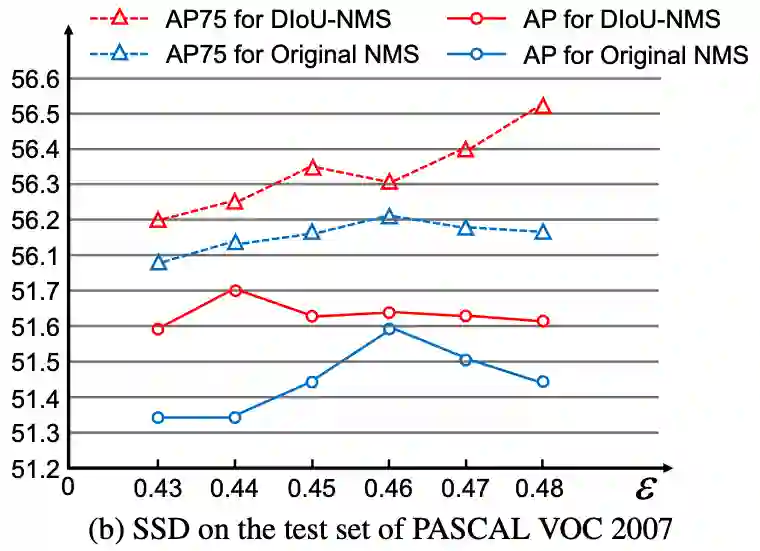
2、SSD on PASCAL VOC
![]()
在SSD-FPN上进行实验对比,因为本身模型已经精度很好了,DIoU loss和CIoU的效果不是很显著,但仍有提升。
mAP分别提升0.59%和0.84%,而AP75则分别提升1.77%和2.59%,而使用DIoU-NMS则能进一步提升效果。
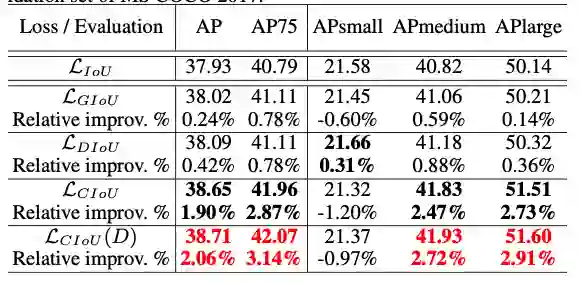
3、Faster R-CNN on MS COCO
![]()
在Faster R-CNN ResNet-50-FPN上,由于Faster R-CNN本身提供的bbox质量都比较高(即在图4的盆地),因此,GIoU的优化都很小,但此时DIoU和CIoU则表现了不错的优化效果。
注意到,CIoU在小物体上的性能都有所下降,可能由于长宽比对小物体的检测贡献不大,因为此时中心点比长宽比重要。
![]()
![]()
![]()
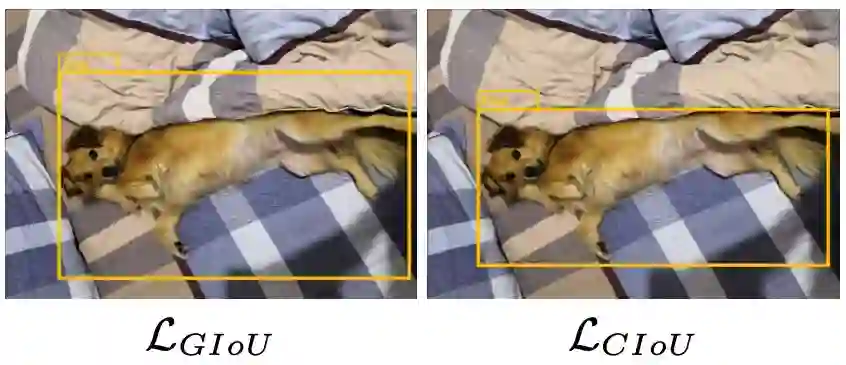
图 6
图6对GIoU和CIoU的结果进行了可视化,可以看到,在中大型物体检测上,CIoU的结果比GIoU要准确。
4、Discussion on DIoU-NMS
![]()
图 7
如图7所示,DIoU-NMS能够更好地引导bbox的消除。
![]()
![]()
图 8
为了进一步验证DIoU-NMS的效果,进行了对比实验。
如图8所示,DIoU-NMS的整体性能都比原生的NMS效果要好。
论文提出了两种新的IoU-based损失函数,DIoU loss和CIoU loss:
DIoU loss最小化bbox间的中心点距离,从而使得函数快速收敛;
CIoU loss则在DIoU loss的基础上加入长宽比的考量,能够进一步地快速收敛和提升性能。
另外论文提出DIoU-NMS来代替原生的NMS,充分地利用IoU的特性进行优化,从实验结果来看,效果也是很好的。
新型冠状病毒疫情下,AAAI2020 还去开会吗?
美国拒绝入境,AAAI2020现场参会告吹,论文如何分享?
AAAI 最佳论文公布
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
![]()
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页