大规模中文概念图谱CN-Probase正式发布
历时多年的研发,复旦大学知识工场实验室正式推出大规模中文概念图谱——CN-Probase,用于帮助机器更好的理解人类语言。概念图谱中包含实体(比如“刘德华”)、概念(比如“演员”),实体与概念之间的类属关系(又称isA关系,比如 “刘德华 isA 演员”),概念与概念之间的 subclass of 关系(比如 “电影演员”是“演员”的子类)。通常后面两类关系,又统称为 isA 关系。如果 A isA B,通常称A为B的下位词(hyponym),或者B为A的上位词(hypernym)。
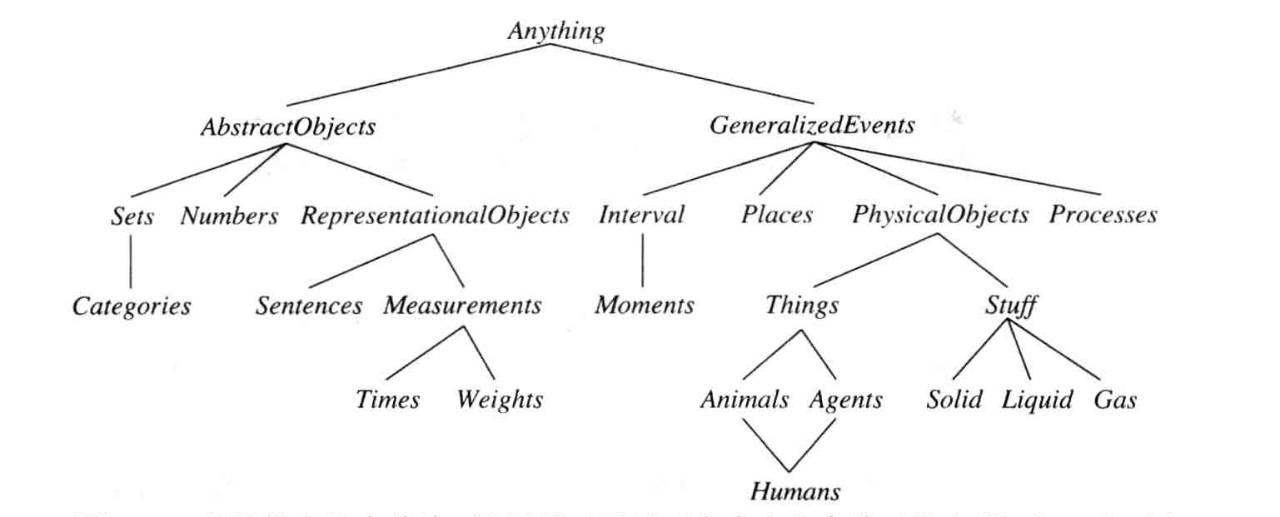
概念的形成是人类认知从具体进入抽象的第一步。人类通过概念认知世界,概念是人类认知世界的基石。概念是人脑对客观事物本质的反映,是思维活动的结果和产物,是思维活动借以开展的基本单元。比如“恐龙”这一概念让我们能够认知形形色色的恐龙,把握其共性本质,而无需纠缠于不同特定恐龙的细微差别。建立概念分类体系,并为数以千万计的实体建立概念图谱,是我们在让机器具备认知能力的征程中所迈出的至关重要的一步。
人类通过分类结构(Taxonomy)来组织和表示概念。最早可以追溯到亚里士多德时代。随后的几千年来,人类一直在不断完善概念的分类体系,并于近些年涌现了很多分类体系,如Cyc,WordNet等,这些概念分类体系大都由专家手工构建,质量精良,但是构建代价高昂,规模有限。
现在知识工场采用自动的方法,基于CN-DBpedia以及海量中文网页语料等多个数据源,构建了大型中文概念知识图谱——CN-Probase。针对中文语言的特性,采用了全新的抽取策略,达到质和量的全面升级。
CN-Probase是由复旦大学知识工场实验室研发并维护的大规模中文概念图谱,是目前规模最大的开放领域中文概念图谱和概念分类体系,isA关系的准确率在95%以上。相比较于其他概念图谱,CN-Probase具有两个显著优点:
一、规模巨大,基本涵盖常见实体和概念。包含约1700万实体、27万概念和3300万isA关系。
二、严格按照实体进行组织,有利于精准理解实体的概念。例如,“刘德华”这个名字,可能对应很多叫“刘德华”的人,在CN-Probase里搜索“刘德华”,会出现按照典型性排序的很多实体,排在第一个的是大家提及名字都会联想到的歌手“刘德华”。

有了CN-Probase,计算机就能像人类一样具有常识。例如,计算机可以知道鲤鱼和鲨鱼都是鱼,但鲤鱼是一种淡水鱼,而鲨鱼是一种海水鱼。
与此同时,CN-Probase还可以广泛应用于各种场景:
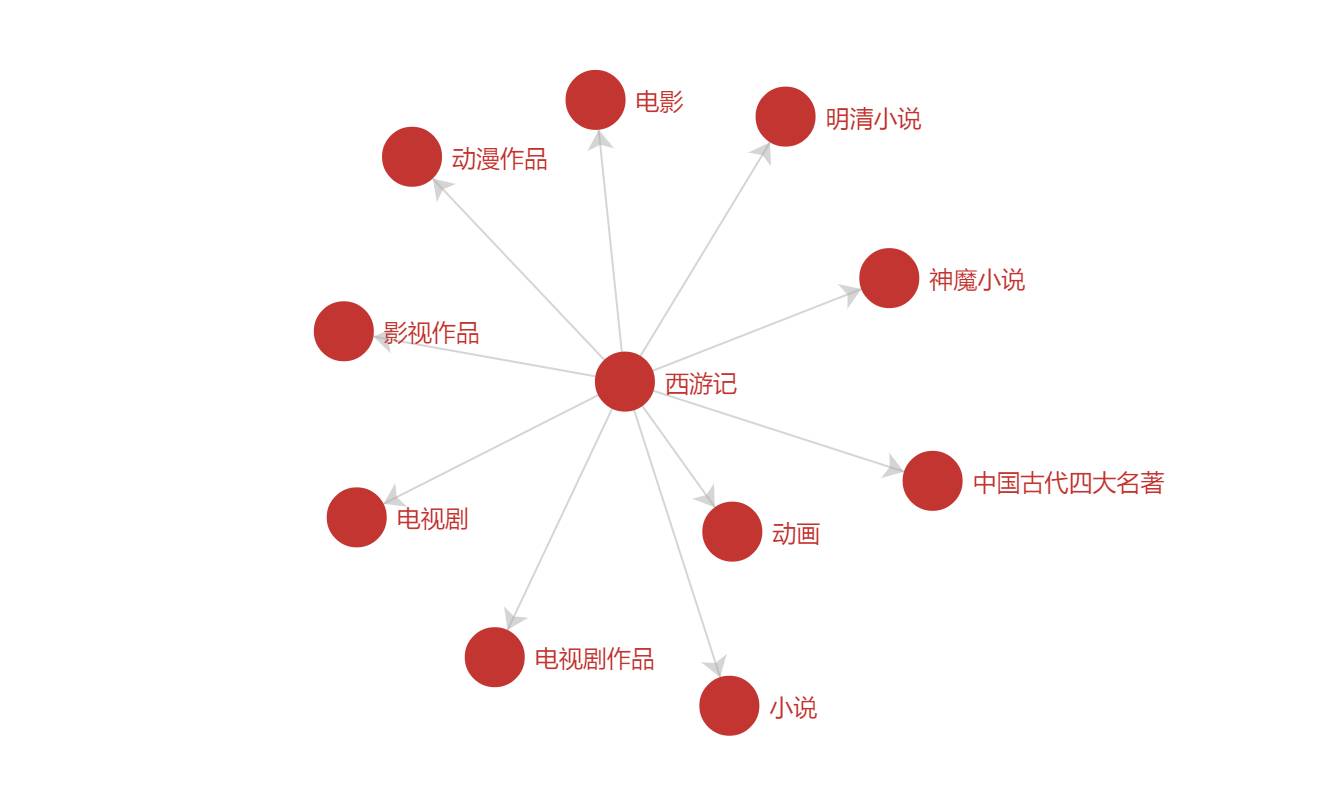
例一:搜索意图理解
用户搜索“西游记”,我们通过它的概念“中国古代四大名著”、“小说”可以理解用户是在搜索小说类名著。对于用户搜索意图的精准理解可以进一步帮助改进检索、排序与推荐。
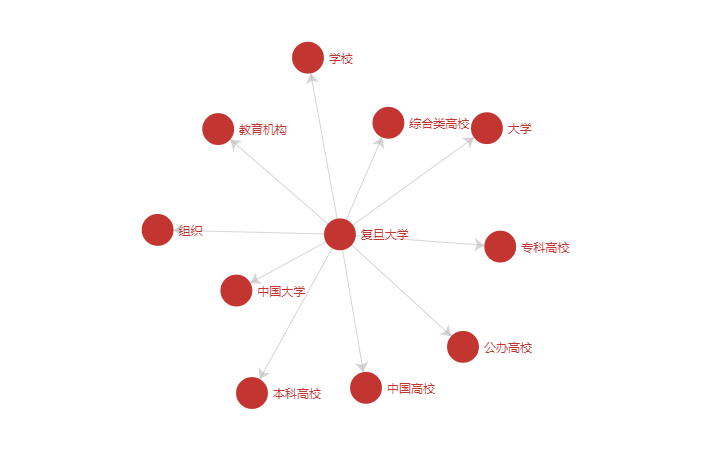
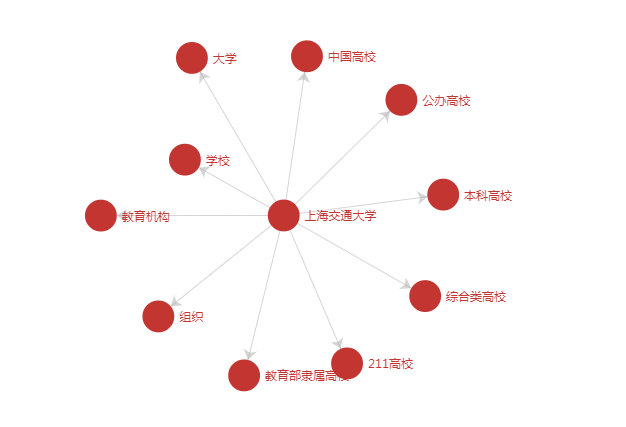
例二:实体相似性判断
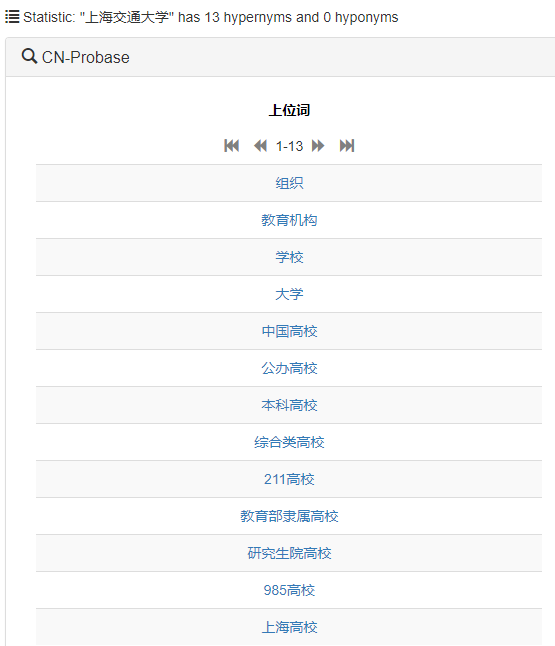
当用户需要判断“复旦大学”和“上海交大”是否相似时,仅仅根据字面相似性,很难知道它们是相似实体。但是通过CN-Probase,我们可以看到它们的概念是差不多的(如下图),从而可以判断它们在语义上是相似的。

例三:可解释实体推荐
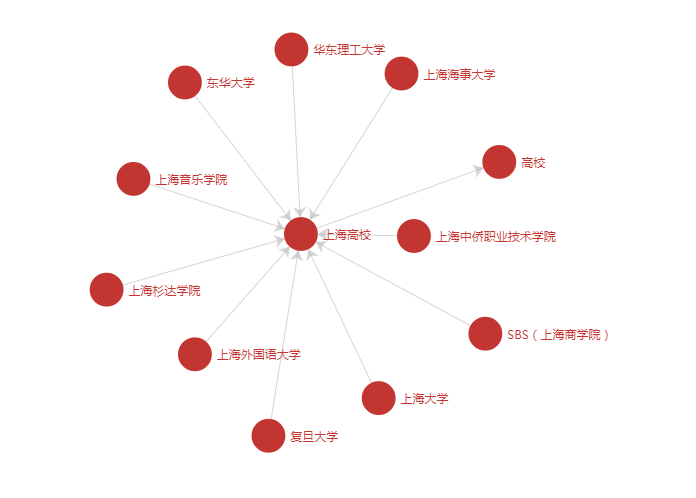
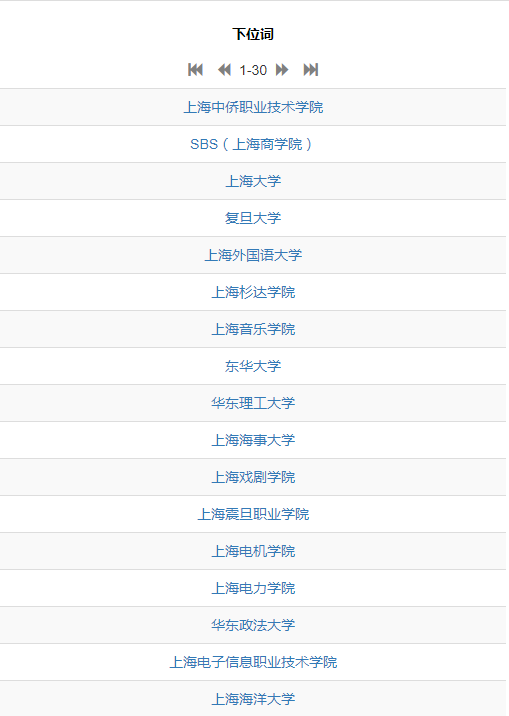
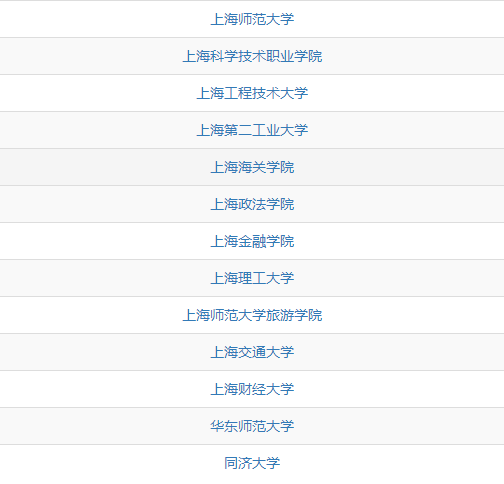
当用户先后搜索“复旦大学”、“上海交通大学”,“上海理工大学”时,我们人类可以自然地推断用户是在搜索上海高校。如今,机器通过检索CN-Probase,发现这三个实体共享“上海高校”这个概念,从而也可以准确识别用户的搜索意图,进一步推荐“上海外国语大学”,“同济大学”等实体,并给出用户是在搜索上海高校这一解释。
目前,知识工场提供两种方式访问CN-Probase:
页面直接访问。进入http://kw.fudan.edu.cn/cnprobase即可访问CN-Probase页面。
API接口访问。我们提供了全套数据访问API,大家可以访问http://kw.fudan.edu.cn/apis/cnprobase/ 查看具体访问方法。
值此发布之际,特向大规模概念图谱的“前辈们”,包括德国马普研究所的Yago、微软亚洲研究院的Probase、微软的概念图谱以及哈尔滨工业大学的大词林,表示崇高的敬意。
点击“阅读原文”查看CN-Probase页面
更多产品试用请点击知识工场网站主页:http://kw.fudan.edu.cn/
合作意向、反馈建议请联系我们:
info.knowledgeworks@gmail.com
或直接联系知识工场负责人肖仰华教授:
shawyh@fudan.edu.cn
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






