有货移动端DevOps-自建APM系统

得益于智能手机的发展,当下我们对用户的体验追求已经到了几乎极致的程度。主流的监控 OneAPM,New Relic… 由于面向广大用户,强调数据共性,很难通过 UDID 或者 UID 来定位一些比较难以复现或局部的问题。同时由于数据保密性等原因,对事件上报的信息量也是非常的有限。随着用户规模的增长,特殊问题,局部问题覆盖的用户越来越来,自建监控就一个必然的选择。
需求是迫切的,资源是有限的。为了尽快的上线监控系统。有货 iOS 和 Android 的小伙伴们本着“流自己的汗,吃自己的饭,自己的事情自己干”的原则,不强调客观条件,自己撸出了一套 App 的 APM 监控系统。
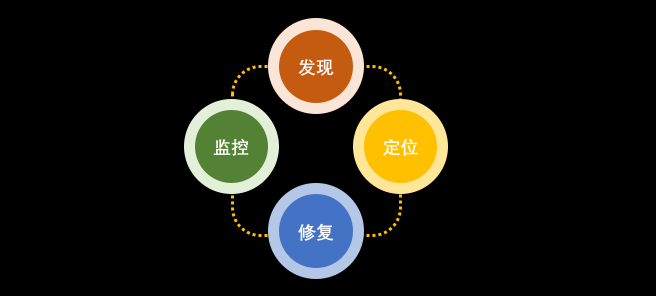
我们把问题处理的流程大致梳理为“持续监控”、“发现问题” 、“定位问题”、“修复问题”。这往复的四个步骤,其中“监控”,“发现”和“定位”都依赖于系统的采集和上报。
通过对需求的分析,我们把数据以事件的形式上报,上报后数据根据场景分为两类:
指标类数据
日志类数据
指标类数据主要是对用户上报的信息根据我们需要的维度做聚合,便于我们掌握 app 的整体情况,比如用户整体的网络错误,网络延时。从整体的角度观察我们 app 的健康程度。 这个过程概括为“发现问题”。
日志类数据则记录完整的上报数据,用于我们对问题的诊断。 这个过程概括为“定位问题”。
围绕这两类数据的采集和分析,我们启动了第一阶段的项目。
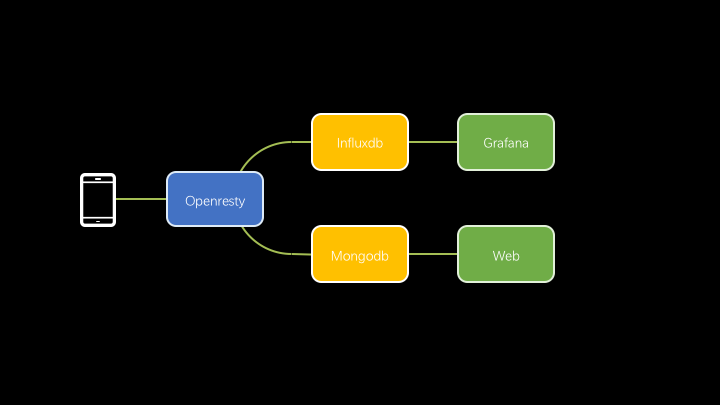
App 将事件数据上报至 OpenResty,在 OpenResty 中对请求进行简单的处理和封装,拆分成指标和日志,然后将处理完成的数据分别写入 InfluxDB 和 MongoDB 中。再通过 Grafana 实现数据可视化。通过一个 Web 页面来查询存储在 MongoDB 中的日志。
App 上报的数据转换为有意义的指标, 这个过程是靠“聚合”来实现的。这套系统中“聚合”则是借助 InfluxDB 完成的。
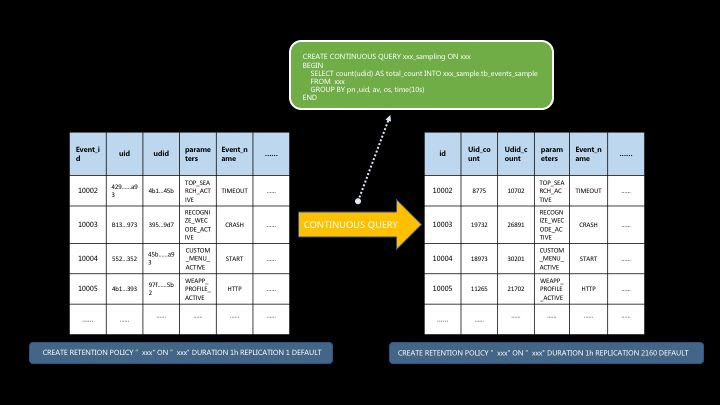
在 InfluxDB 中,我们先将所有数据写入不同类型的事实表中,然后通过多个 Continuous Query 对数据进行聚合处理,把大量的明细数据聚合成一定时间周期的聚合数据(主要的周期为 30 秒或 1 分钟),再通过 Retention Policy 来控制不同类型表的数据有效期,达到资源最高效利用的目的。
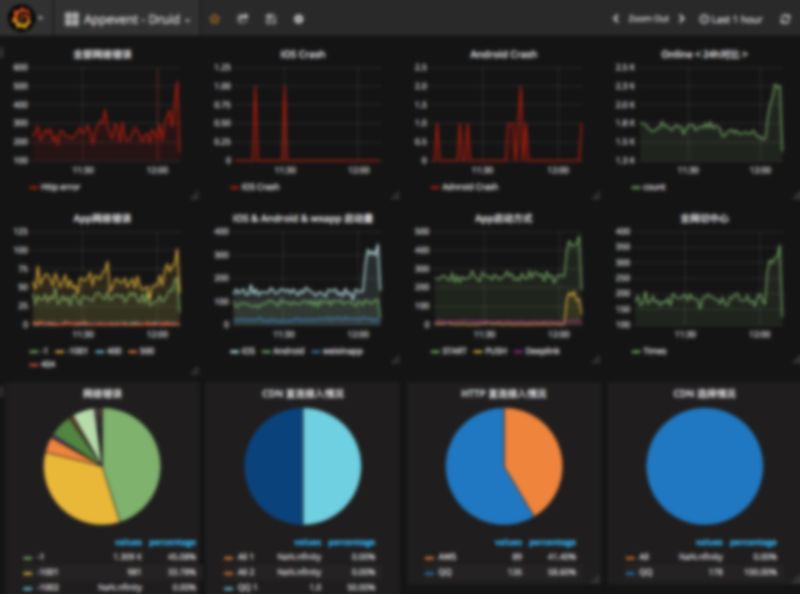
数据可视化部分则用 Grafana 来支撑的,我们的 Main Dashboard 通过 20 张的图表来展示整体的健康状况,同时在这 20 张图表背后,还有数个更加详细的图表支撑微观方面数据。
比如有张图表绘制的是当前全网用户设备发生的网络错误率。 通过这个指标和 24 小时前的对比,我们能够直观了解整体的网络健康状况。当该指标超过某个阈值或相比昨天同时段对比有明显上升,则触发告警。实现 “发现问题”。
当出现告警后,通过网络相关的 dashboard 查看是由哪个接口发生的,什么类型的错误。再根据错误类型去日志平台查询日志。完成“定位问题”。
对于日志数据我们直接将上报的 json 内容逐条拆分后写入 Mongodb。直接通过 web 页面从 Mongodb 查询对应时间的 App 日志。
这套系统的优势体现在架构非常的轻盈,成本很低。只需要简单的 OpenResty 的开发以及对 InfluxDB 做一些连续查询。在日志量不大的情况下,完全可以满足基本的移动端性能监控以及异常监测的需求。
在运行了一段时间后,我们有了新的需求。
中国有 23 个省,5 个自治区,4 个直辖市,以及香港、澳门 2 个特别行政区。电信、联通、移动三大运营商。网络制式从 2G、3G、4G 到 WiFi,还有各种各样的移动设备。这些条件构成了数量难以想象的场景。当仅仅在个别场景下发生问题,或是部分场景下发生问题的时候。我们“发现问题”的即时性会变差,“定位问题”所用的时间也越发的变长。
为了缩短“定位问题”的时间。提高发现问题和解决问题的效率。多维分析能力是我们所渴望的,如果在原有的系统上做多维分析,存在如下问题:
InfluxDB 缺乏合理免费的集群方案,我们在建立了自己的 APM 以后,客户端同学对数据和监测的需求突飞猛进,数据量每天以几何级数增长,再对其进行多维分析,单机的 InfluxDB 很难满足性能要求。
MongoDB 在数据量很大的场景下,直接查询速度很慢。由于我们日志数据的多样性,在对多个维度建索引后,整体索引效率很低。
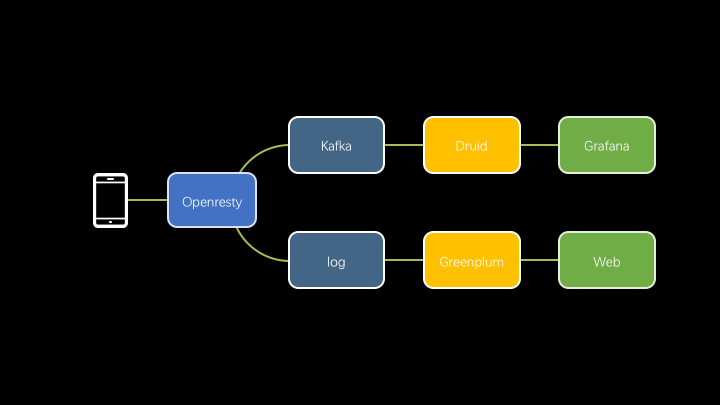
为了满足大量(这里暂时不成为海量)数据的多维实时查询的需求,我们对架构中数据库和数据摄入过程进行了升级,InfluxDB 变更为 Druid, MongoDB 变更为 Greenplum, 数据也不再由 OpenResty 直接插入,而是通过了 Kafka 和 log 文件把写入过程解耦,减少数据写入次数,提升处理数据的量级。
Druid 是在海量时序数据上面提供实时分析查询的开源 OLAP 数据存储。
Druid 本身对于 join 这样的操作很不友好,所以我们没有考虑用一些模型(星型或者雪花型),而是采用大的事实表,其中包含了一次事实关联的所有维度,看着很臃肿,但是查询的性能让人满意。在随时变更维度的情况下,Druid 实时查询依然维持在秒级。这不得不让人刮目相看。
同时丰富的查询组件和聚合函数,让复杂的查询得以简单的实现。所以在查询性能、便捷性、数据量等方面的综合考量下,我们选择了 Druid 作为 InfluxDB 的升级方案。
不同于 InfluxDB,我们不再通过连续查询来做数据聚合,Druid 自身在摄入的过程中可以对指定的 Dimension 进行 roll-up 操作。极大的压缩了数据量。我们的数据经过 roll-up,每分钟从 25 万条压缩到了 8 万多条,效果比较显著。不过压缩数据是以牺牲原始数据为代价的,预聚合仅保留指定的 Dimension 及 Aggregations 结果,所以请妥善设置 Dimension。 Dimension 会发生 SQL 中 Group By 的效果,参数维度多势必降低聚合效果。尤其需要的注意 Dimension 的选择,如果一不小心选择了高基字段作为 Dimension,那么压缩效率会低的惊人。我们曾经因为数据处理的失误,将一个 Dimension 的 Value 数从 2000 变成了 200W, 直接导致当天的 segments 占用的空间比以往大 22 倍。通过摄入周期的调整,还可以做到更大的压缩比,这个取决 queryGranularity 字段,它决定了压缩后的数据最小时间粒度,目前我们使用的是分钟。
在使用 Grafana 接入 Druid 的时候还是遇到一些小坑,由于 Grafana 官方集成的 Druid 插件实在是功能太有限,比如对 Time Range 的限制,我们不得不在源码的基础上做了部分调整。
Druid 两种数据摄入源:
流式数据
静态文件数据
这两种数据源又都有两种方式摄入,分别为 pull 方式和 push 方式。我们采用了 real time index(push 的一种)方式,启动实时 task 来从 kafka 中摄取数据。
Greenplum 相比我们原先使用的 MongoDB, 支持列式存储, 并行查询效率更高。在不建索引的情况下,50 列千万级别的数据在 1,2 秒能查完,完全满足我们对日志查询的需求。
起初我们使用 Http 的方式批量插入 Greenplum,但是当写入速度超过 6 千条每秒时,查询速度直线下降。
明显写入不是 Greenplum 的强项,为了解决这个问题,我们是把日志以文件的形式写入 NFS 中, 由 Greenplum 定时摄入。
同时为了保证性能和简化写入,还对 OpenResty 的写入进行了优化,利用 nginx 的 subrequest 写 access.log 的功能来实现日志写入,并且整个过程封装到协程中执行。调整后每分钟能够轻松写入 50 万条。
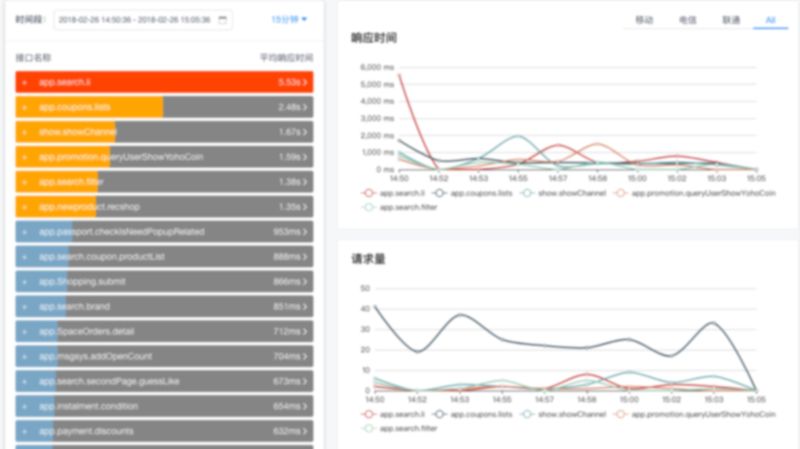
这套系统对个性问题,共性问题的快速甄别起到了关键性的作用,也极大的提升了定位问题的速度。在针对某些维度或特征做针对性的优化的时候,效果也更容易监控。
通过不同类型事件的采集,我们还实现了页面响应时间(多维)、http 请求分阶段响应时间(多维)、页面卡顿分析、页面加载性能监控等多方位的监控系统,为我们的优化工作指明了方向。对于 iOS 或者 Android 开发的同学,这样一套系统既能满足需求,也易于开发,相比传统 ELK 日志分析在实时性和简易性都提升很多。
如果技术团队的资源比较紧张,移动端的同学自己动手实践下 DevOps 也是不错的选择。
活动推荐
8 月 18 日,我们将在一场面向技术人的区块链大会,大会关注目前区块链领域前沿技术与落地应用,将邀请国内外一线技术专家交流分享,和你一起探索区块链技术的更多可能!目前大会 6 折最后一周,火热招募中!扫描二维码进入官网查看大会议题。





