业界 | 弱监督学习下的商品识别:CVPR 2018细粒度识别挑战赛获胜方案简介
机器之心原创
作者:李亚洲、思源
细粒度视觉分类(FGCV,Fine-Grained Visual Categorization)即识别细分类别的任务,一般它需要同时使用全局图像信息与局部特征信息精确识别图像子类别。细粒度分类是计算机视觉社区最为有趣且有用的开放问题之一,目前还有很多难题期待解决。
2011 年,谷歌开始赞助举办第一届 FGVC Workshop,之后每两年举办一次,到 2017 年已经举办了第四届。而由于近年来计算机视觉的快速发展,FGVC 活动影响力也越来越大,从去年开始由两年一次改为了一年一次。
从 2017 年开始,FGVC 开始运作两大挑战赛 iNaturalist 与 iMaterialist。今年的 iMaterialist 挑战赛是由国内创业公司码隆科技联合 Google Research、美国知名电商 Wish、Kaggle 举办。值得一提的是,从今年开始 FGVC 开始运行一系列子竞赛:iWildCamp、iFood 等。
在 CVPR 2018 尾声的 FGVC Workshop 上,Google Research 资深工程师兼 FGVC5 联合主席张晓对 iMaterialist 2018 挑战赛与比赛解决方案进行了介绍。
iMaterialist 2018 挑战赛
如何让机器识别达到趋近乃至超过人眼判定的精准度?这是许多计算机视觉科学家们一直致力解决的问题。业内也有许多知名的挑战赛,如 ImageNet、COCO 等。但与 ImageNet 这样的的粗粒度分类竞赛相比,细粒度图像分类技术变得极具挑战性。
以 iMaterialist 2018 挑战赛为例,由于细粒度属性的产品看起来非常相似,且商品在不同光线、角度和背景下拍摄,其识别精度也会受到影响。与此同时,不同商品的相似特征,也为机器识别增加了一定的难度:比如家具中的球椅和蛋椅,从某些特定角度来看十分相似;再比如服饰的宝蓝色和松绿色,在不同的光线条件下也存在一定的相似性。
因此,细粒度识别相比于一般的图像分类不仅需要使用图像的整体信息,同时它应该注意到子类别所独有的局部特征。例如从总整体上确定球椅和蛋椅都从属于椅子,然后再根据局部细节确定具体是哪一种椅子。
「但是相关技术具有更大的实际应用意义」码隆科技表示,「它可以直接转化为工业界的应用,提高效率、减少成本」。
在此挑战赛中,码隆科技与美国知名电商平台 Wish 提供了所需的服装和家具图像数据,并会在之后向学术界开放 120 万带标注的商品图像数据集。此次 iMaterialist 2018 挑战赛分为 iMaterialist - Fashion 和 iMaterialist - Furniture 两个 Track。iMat Furniture 2018 的数据集为清理标注过的干净数据,而 iMat Fashion 2018 的数据集为未清理过的噪声数据。
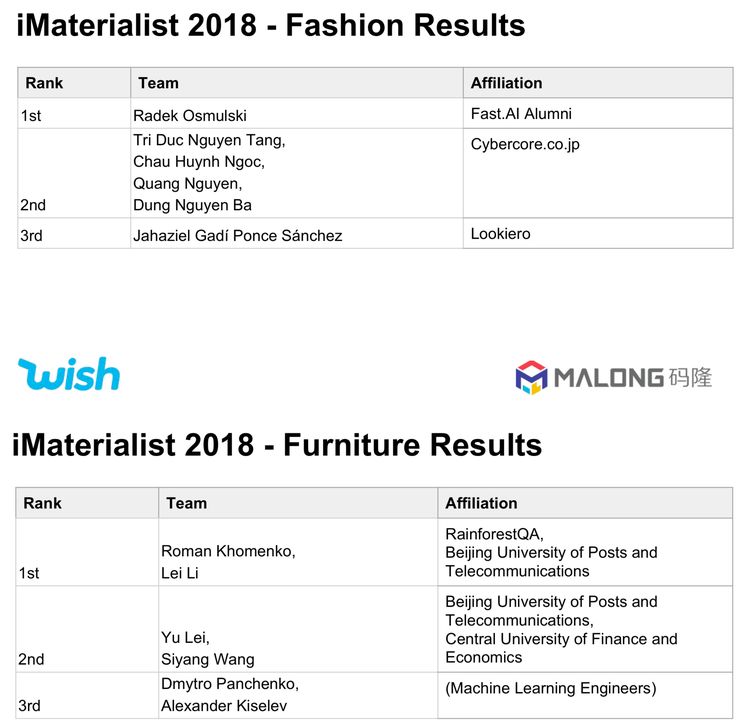
经过 3 个多月的角逐,iMaterialist 2018 挑战赛最终分出胜负:
解决方案
一般细粒度识别可以分为两种,即基于强监督信息的方法和仅使用弱监督信息的方法。基于强监督的细粒度识别通常需要使用边界框和局部标注信息,例如 2014 年提出的 Part-based R-CNN 利用自底向上的候选区域(region proposals)计算深度卷积特征而实现细粒度识别。这种方法会学习建模局部外观,并加强局部信息之间的几何约束。而 iMaterialist 2018 仅使用类别标签,因此是一种弱监督信息的细粒度识别。
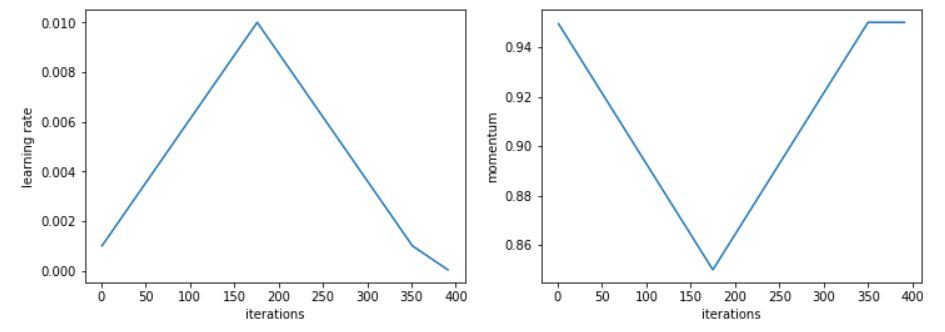
其实在这一次竞赛中,很多不同的方法都有它们各自独特的亮点。例如在服装第一名的解决方案中,虽然它也是利用预训练 resnet152、 xception 和 dn201 等模型并结合 XGBoost 做预测,但 Radek Osmulski 另外使用了 1 Cycle LR Policy 进行精调。
1 Cycle 用两个等长的步骤组成一个 cycle:从很小的学习率开始,慢慢增大学习率,然后再慢慢降低回最小值。Radek Osmulski 在增大学习率的同时降低动量,这也印证了一个直觉:在训练中,我们希望 SGD 可以迅速调整到搜索平坦区域的方向上,因此就应该对新的梯度赋予更大的权重。其实在真实场景中,可以选取如 0.85 和 0.95 的两个值,在增大学习率的时候,将动量从 0.95 降到 0.85,在降低学习率的时候,再将动量重新从 0.85 提升回 0.95。
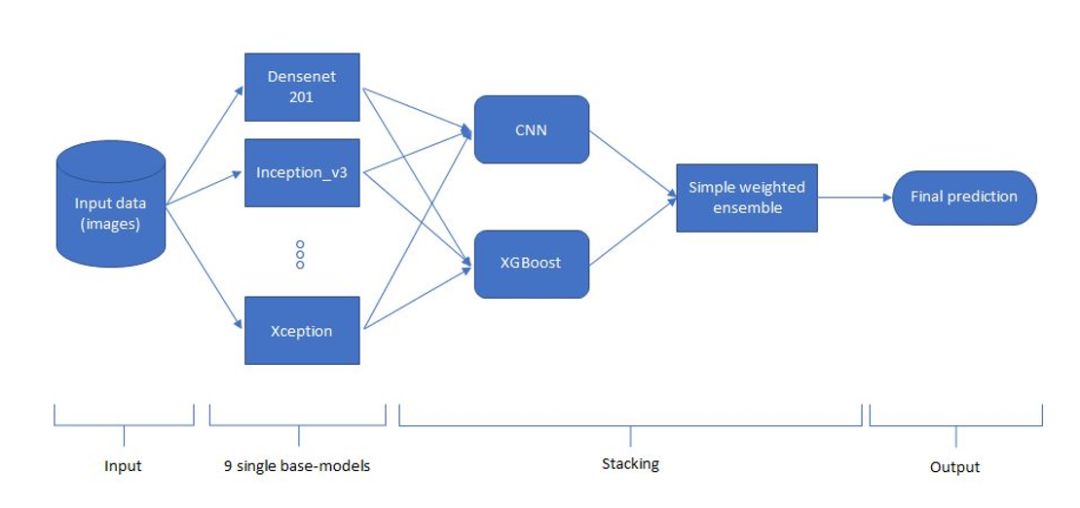
在服装第二名的解决方案中,作者采用了如下网络架构。首先开发者会采用非常多的数据增强方法增加输入图像,例如水平翻转、旋转、高斯模糊、锐化、截取和归一化等方法。然后根据 DenseNet、inception_resnet_v2、Inception-v3、Nasnet 和 ResNet-50 等九个基础卷积网络抽取输入图像的特征,并分别作出预测。最后结合所有基础模型的预测就能得出非常不错的最终结果。
如前所述细粒度识别需要很多局部图像信息才能实现子类别的判断,谷歌(需要确切身份)Xiao Zhang 表示:「选手这些网络最终层的 dimension 都比较小(比如 7x7),这种情况下最终做决策时很难兼顾不同尺度的信息。如果需要兼顾局部和整体需要使用 Feature Pyramid Network,或者类似于编码器/解码器的结构在最终层使用高维的预测。」
在整个流程中,Stacking CNN 是非常有意思的过程。开发者会将九个模型的预测结果叠加在一起为 9×228×1 的张量,其中每一个基础模型提供一张 1×228×1 的张量,它代表了模型对 228 个类别的预测结果。如下所示当叠加为这种张量后,我们可以使用 3×1 的卷积在它上面执行步幅为 1 的卷积运算,这种卷积可以学习到各基础模型原始预测之间的相关性。
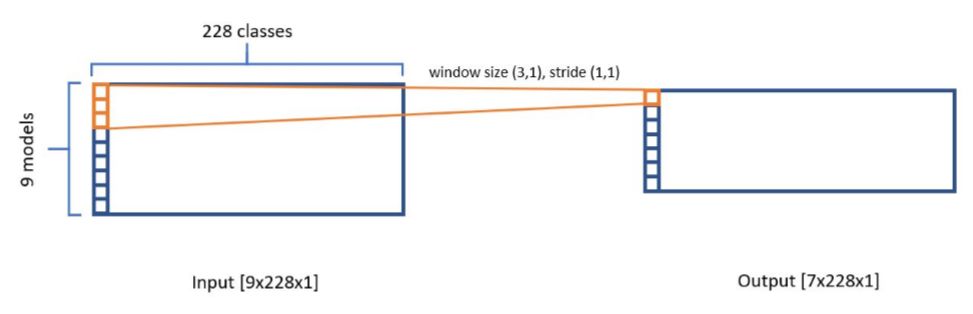
上图输出张量 7×228×8(8 个 3×1 的卷积核),在经过 16 个 3×1 的卷积核执行卷积运算并馈送到全连接层后,就能做出最终的预测。因为 3×1 的卷积其实相当于在同一个类别上,加权三个模型的预测并输出到下一层。所以这也相当于一种集成方法,模型会自动学习不同基础模型预测的重要性,并结合所有基础模型作出最终预测。
家具细粒度分类的两个解决方案也非常有特点,例如 Roman Khomenko 和 Lei Li 设计的家具第一名解决方案使用了一种称之为概率校准的技术。他们表示在训练集中,类别数量是非常不平衡的,但在验证集中类别数量是平衡的,因此我们可能需要使用概率校准以解决这种训练于验证之间的分布差异。
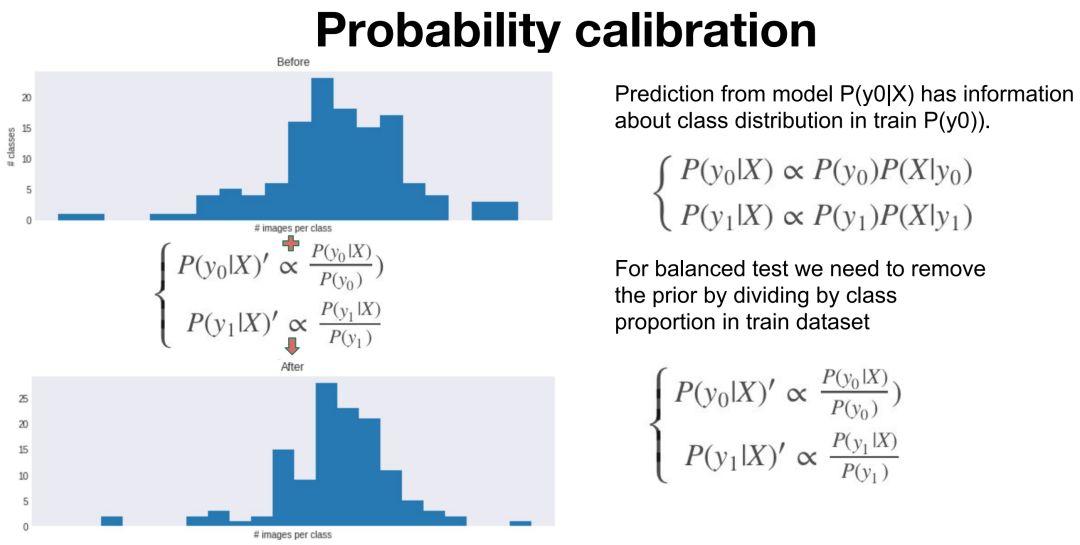
Google Research 张晓表示:「校准分为两步: a) 对于每个 label 的预测概率,除以该类别的物体数,除以对应的先验概率; b) 对所有更新后的 label 的预测概率做归一化(相加得到 1)」
Dmytro Panchenko 和 Alexander Kiselev 设计的解决方案获得了家具第二名,他们其实也使用了多个卷积网络的集成方案。总的来说,这四个解决方案都是使用多个预训练卷积网络,它们会分别在训练集与验证集中进行学习与调参,然后再使用不同的集成方案总结各个模型的预测结果。
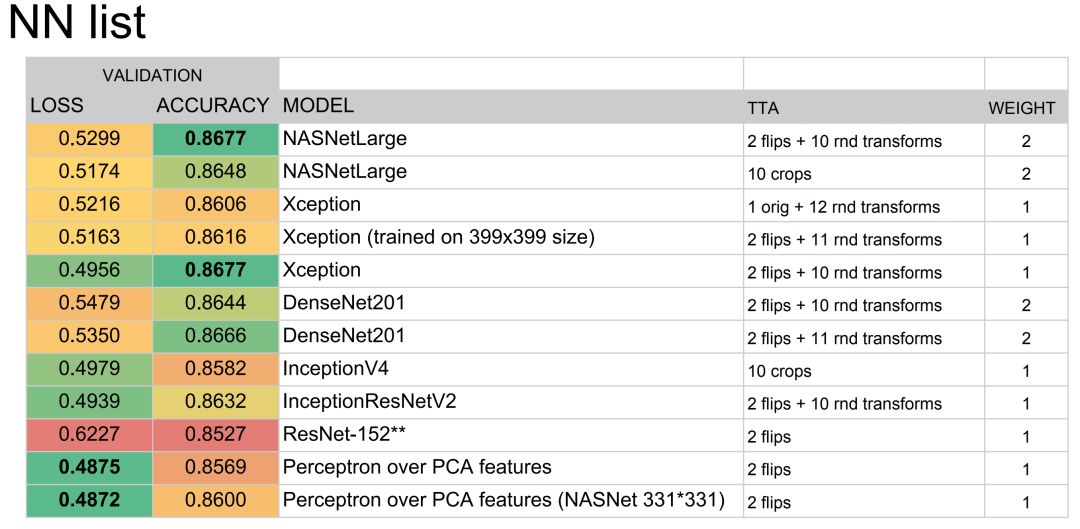
Dmytro Panchenko 等开发者集成的基础模型。
因为细粒度识别很多时候需要使用注意力机制或 Faster R-CNN 等方法抽取局部特征,并用于预测最终细分类别,而挑战赛中的模型很多都是模型集成。因此我们可能会比较好奇为什么不在竞赛中使用前沿和优秀的细粒度识别模型呢?Dmytro Panchenko 团队解答到:「我们其实也考虑了这个问题,并花时间进行调查和查文献,也许我们可以训练出照片上分割目标的网络。但这些方法很多都需要额外的标注,而且我们也不知道哪些特征对不同类型的椅子是最重要的,因此我们只是采用了「默认」的方式(完全不是因为我们懒)。」
此外,他们表示:「照片很多都来自在线购物网站,其中 99% 图像的主要目标都在图像中央,几乎是完美的剪裁。因此我们认为如果训练集足够大,那么 CNN 能从中抽取到足够好的特征。」
最后,作为联合举办单位,码隆科技首席科学家黄伟林博士总结,在多年从事商品识别的研究和实践过程中,面临的三个主要难点。首先,细粒度商品识别,特别是对 SKU 级别的识别是至关重要的。如下图所示,不同种类的益达口香糖,在零售过程中通常价格会不太一样,因此需要作精确区分。其次,除了细粒度分析,SKU 级别的商品识别通常需要识别大量的商品种类,比如超过 10 万类,而常见的 ImageNet 物体识别通常只有 1,000 类。这是商品识别的另一个挑战,而常用的单层 softmax 分类模型很难解决。
这就需要引进多层级联的细粒度分类算法,从而加大细粒度识别的难度。最后,由于商品类别多,就要去更多的海量训练数据和人工标注,比如 10 亿级别的。对于如此数量的人工标注和数据清洗,是很难完成的。因此,如何有效地利用海量网络爬去的商品图片,在没有或者只有少量人工标注和清洗的情况下,训练一个高性能的商品识别模型,成为一个关键的技术。码隆科技最近提出的弱监督学习算法- CurriculumNet,就是专门为训练海量无工人共标注的海量网络图片而设计的。

此次 FGVC5 挑战赛是现实应用场景问题促进算法探究的一次实践,从数据集数量到参赛团队规模都上升到新的台阶,这也说明商品识别这类细粒度识别问题正在引起更多学者、技术从业者关注。据悉,码隆科技和 Google Research 正在积极探究更深入的细粒度人造物识别场景,并期待下一年继续共同举办相关挑战赛。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



