TDM: 基于树的深度学习模型在阿里推荐系统中的应用

广告推荐算法系列文章:
-
莫比乌斯: 百度的下一代query-ad匹配算法 -
百度凤巢分布式层次GPU参数服务器架构 -
DIN: 阿里点击率预估之深度兴趣网络 -
基于Delaunay图的快速最大内积搜索算法 -
DIEN: 阿里点击率预估之深度兴趣进化网络 -
EBR: Facebook基于向量的检索 -
阿里巴巴电商推荐之十亿级商品embedding -
TDM: 基于树的深度学习模型在阿里推荐系统中的应用(本篇)
Overall
推荐系统一般分为两个部分,即matching和ranking,matching层负责从大规模的商品中找出最相关的数百个,而ranking层则对这几百个商品进行更准确的排序。
前面我们也介绍过几篇阿里推荐相关的论文。其中,DIN: 阿里点击率预估之深度兴趣网络和DIEN: 阿里点击率预估之深度兴趣进化网络是在ranking层的工作,而阿里巴巴电商推荐之十亿级商品embedding则是在matching层的工作,本文所介绍的工作也是在matching层,是和十亿级商品embedding是并行的工作,同样都是在KDD 2018上发表的论文。
本文提出了一种基于树的深度推荐模型,为的是将在ranking层工作的很好的神经网络算法下沉到matching层,同时又不要带来计算瓶颈问题。
系统架构
淘宝的广告推荐系统如下图,在收到用户的请求后,系统会将用户特征,商品特征,上下文特征结合起来去生成一个小的候选集合,TDM就是在这个过程中起作用。在得到候选集合后,real-time prediction部分就会使用比较复杂的模型对CTR和转化率进行预测。然后再经过排序策略,候选集合就被展示给用户了。
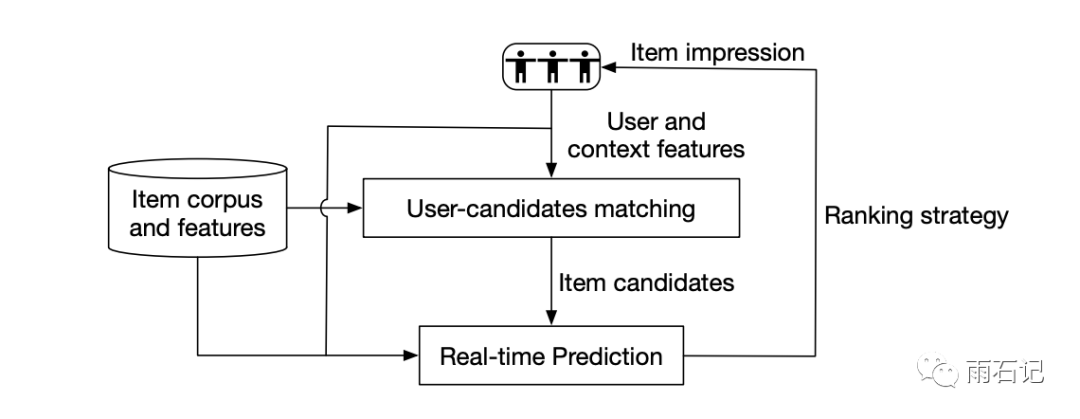
作为最初始的步骤,matching层非常重要,它直接决定了系统CTR的上限。且这一层因为要处理大规模数据,所以效果和性能都是需要解决的问题。
推荐系统中的树结构
首先需要对推荐系统中的树结构进行定义,整棵树包含N个节点,每个节点代表叶子节点或者非叶子节点。其中具体的某个商品必须对应的是叶子节点。
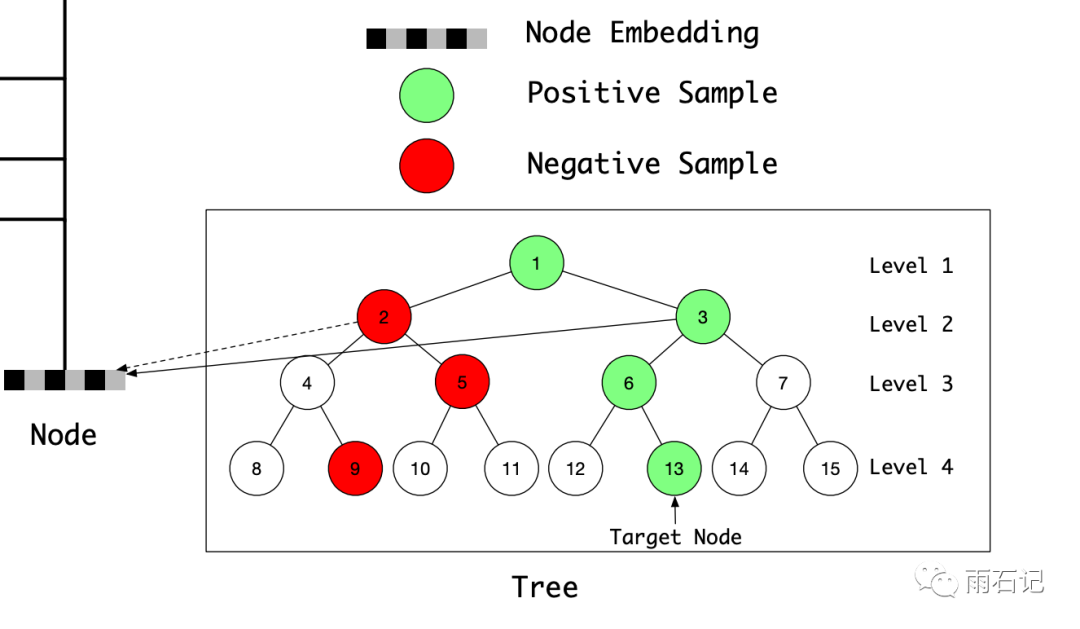
为了通用性,我们定义n1为整棵树的根节点。下图给出了一个例子,每个节点都有一个索引编号,例子中的这棵树有四层八个叶子节点。注意,虽然例子是一个完全二叉树,但是并没有这个要求。
树模型的形式化
更具体的,这棵树有什么性质呢?
将这棵树定义为最大堆类似的结构,不过每个节点上的值是概率。公式如下,公式中j代表树的层数索引,αj是第j层的归一化系数,可以保证第j层所有节点的概率值加起来是1。
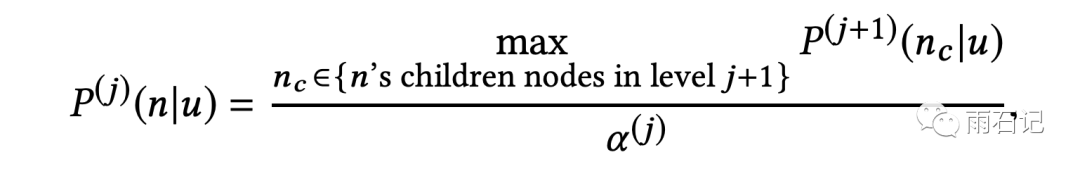
这个公式的含义如下:对于第j层的一个节点,其概率值是其所有子节点的最大值除以归一化系数。
根据这个性质,如果我们想找top-K结果,可以在树的每一层找top-k节点,然后将这k个节点的所有子节点都找出来排序取top-k,以此类推,最后得到的叶子节点就是top-K结果。
损失函数
根据我们刚才所讲的过程,在每层中,我们需要知道的是节点的顺序,具体的概率值则并不那么重要。而对顺序进行估计,使用二分类模型和负例采样就可以了。
还是如上图的那个二叉树,其中,我们需要找到的节点是13,那么13以及它的祖先都是正例,即上面绿色背景的节点。然后再随机采样出负例,即上面红色的节点。
因此,损失函数如下,就是标准的二分类损失。
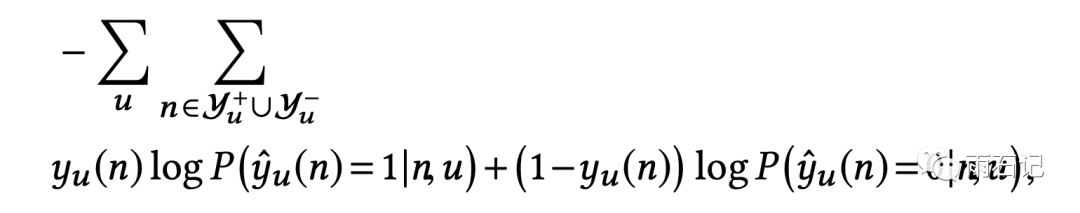
用这种方法构建了模型以后,在inference的时候,只需要对每一层的候选做二分类概率估计,用得到的概率去排序即可。
假如使用的树是二叉树,需要得到的结果是k个,那么整个搜索过程中,需要遍历的节点数则是 2 x k x log|C|,C是样本数目。
搜索算法
有了上面的树结构和损失函数,整个搜索过程如下,正如我们刚才所言,需要在每层找到top-K结果,直到叶子节点。

模型结构
整个模型结构如下图,受DIN的启发,在这里我们为每一个节点学习一个embedding。同时使用类似attention的机制来获得更好的用户表达。
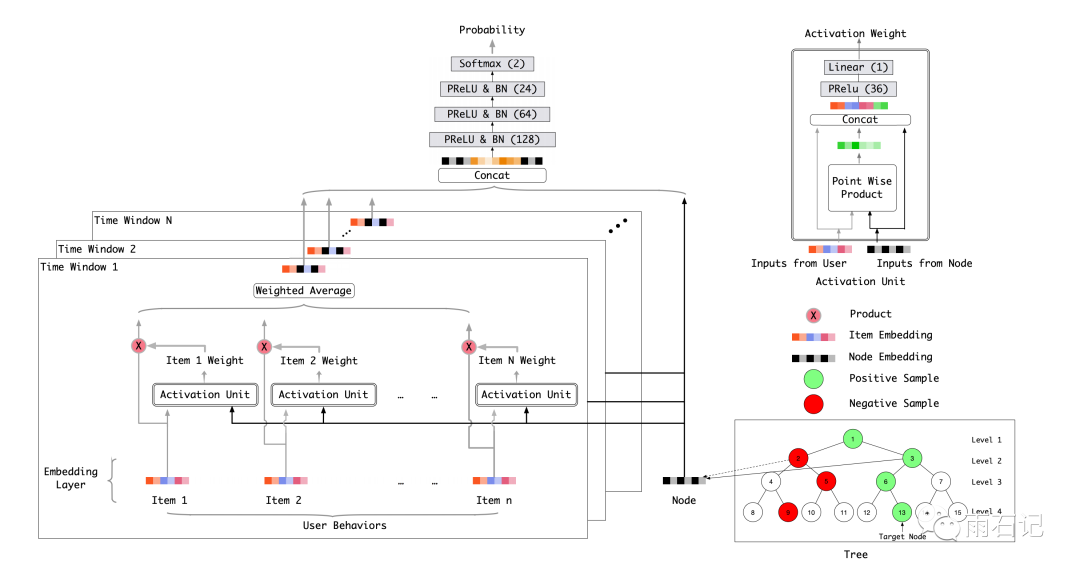
用户的特征就是用户之前的行为数据,在这里,使用时间窗口对用户行为进行划分,得到N个窗口。然后进行如下操作:
-
对于每个窗口,用Node的embedding和用户行为中商品的embedding进行attention权重的计算,得到加权的平均值。 -
将不同窗口的结果和Node的embedding一起拼接起来 -
将拼接后的embedding输入给DNN,得到分类估计。 -
用上述的Loss进行反向传播。
在这个图中,只显示了用户特征,其他特征也可以很方便的引入到模型中来。可以这样说,在树结构的前提下,几乎任何在ranking层使用的深度模型都可以集成到matching层来。
树的构建和学习
前面讲了那么多,那么这个树是如何构建的呢?
首先,使用商品原来的分类结构进行树的初始化,将所有种类随机排序,然后对于所有的商品,将其划到其对应的分类中去,如果一个商品属于多个分类,那么就随机选一个。这样就得到的按照类别分好的商品集合,对于每个类别中的商品,一路随机二等分,构建一个完全二叉树。这样就得到了一个树结构,其中第一层是多叉(有多个类别),再之下的每一层都是二叉树。
这里以二叉树为例,但可以轻松扩展到k叉树上。
得到初始的树结构之后,就可以进行embedding的学习。
得到embedding之后,再用K-means来进行聚类,这样相近的embedding就聚合在一起。聚类的时候,每一次都聚成两类,这样,就得到一个新的二叉树。然后再重新学习embedding。
实验效果
与其他算法的对比,以及与自身算法的变种的对比结果如下,可以看到,本文提出的模型表现最为优异。
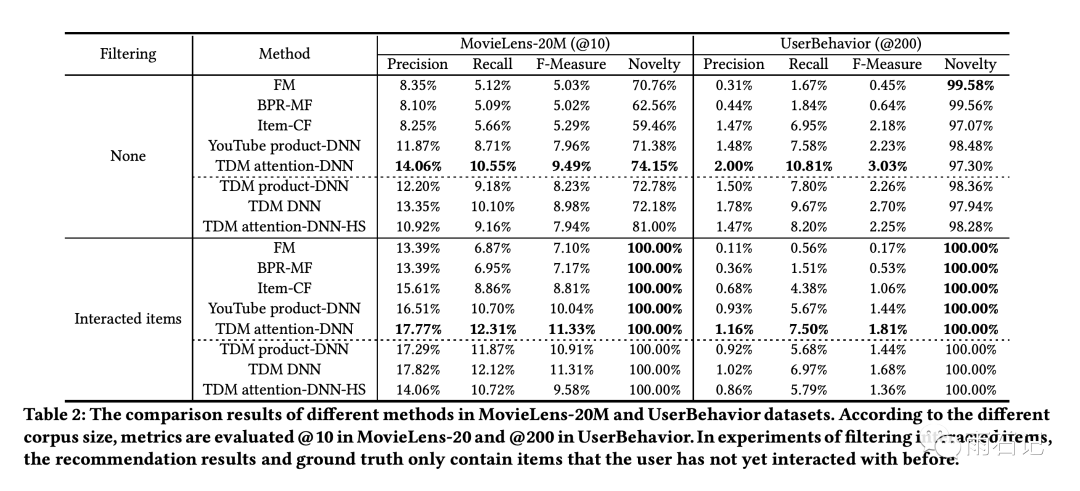
其中,TDM算法的变种有三个:
-
TDM product-DNN:将模型中的attention模块去掉,同时node embedding也从输入中去掉,将用户行为embedding输入给DNN后得到的embedding和node embedding做内积的结果经过sigmoid作为输出 -
TDM DNN: 只移除attention模块,这个可以验证attention的影响 -
TDM attention-DNN-HS: HS是Hierarchical softmax的缩写,在这个版本中,使用正例相邻的样本作为负例而不是随机选择的样本。
线上效果如下,提升CTR 2.1%,提升千次展示收益 RPM达到6.4%。

总结与思考
本文的核心依然是通过提高召回效果来提升最后的结果,为了将ranking层的复杂模型结构高效的应用到matching层,论文巧妙的提出了基于树的模型,并提出了一套模型结构和训练方法,可以很好的训练节点的embedding。
勤提问,多思考是Engineer的良好品德。
-
TDM和层次Softmax的区别是什么?
参考文献
-
[1]. Zhu, Han, et al. "Learning tree-based deep model for recommender systems." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


