刚刚获得软银中国2.2亿人民币B轮投资的码隆科技,到底是一家怎样的公司?| 独家
作为软银中国在中国人工智能领域投下的第一家公司,码隆科技的技术产品究竟如何?未来将把这笔融资应用在何处?黄鼎隆给出了答案。
撰文 | 高静宜
11 月 10 日,国内专注于深度学习与计算机视觉技术的创业公司码隆科技(下简称码隆)宣布获得来自软银中国资本领投的 B 轮融资,融资金额共计 2.2 亿人民币。此前,码隆科技曾在 2015 年 3 月获得 1200 万天轮投资,于 2016 年 10 月完成 6200 万人民币 A 轮融资。
对于接下来的拓展计划,码隆科技 CEO 黄鼎隆说:「最重要的是节制地招纳 AI 人才,进一步完善团队建设,其次是公司正在拓展包括美国、日本、以及南美洲等海外市场,将把这笔资金用于加快国际化市场的开拓。此外,公司还计划组建自己的数据中心,加大硬件方面的投入。」
值得注意的是,这是软银中国在中国人工智能领域投下的第一家公司。此前,软银中国曾成功投资了国内的阿里巴巴、淘宝网等一系列项目,并从去年开始,着手在全球范围内大规模投资人工智能领域。软银中国主管合伙人宋安澜认为,码隆拥有顶级人才团队及国际化视野,看好和期待接下来公司在国际化布局方面的进展。
这家被软银中国率先锁定的中国人工智能初创公司,在技术和产品方面又有哪些独到之处?为此,机器之能采访了黄鼎隆,对这家公司一探究竟。
深度学习是打开金矿的一把钥匙
2014 年 7 月,黄鼎隆和他的「黄金搭档」码特(Matt Scott)开始创业,并取了各自名字中的一个字,将公司命名为码隆科技。
这并不是二人的首次合作。7 年前,黄鼎隆和码特还是微软同事,联手开发了必应词典,这也是微软在亚洲最成功的互联网产品之一。黄鼎隆负责产品与市场,码特负责研究与开发,当年的分工延续也一直到现在。

码隆科技CTO码特与CEO黄鼎隆
「当时这个产品成功走通了从研究开发、产品市场到销售变现的整个闭环。」黄鼎隆笑着说道,「所以那时我们就有过这种内部创新的经历,只是工资不用我们自己发而已。」
创业的想法是从必应词典的研发开始。当时流行的词库还只拥有百万量级的词汇量,而必应词库就率先实现了千万量级的词汇量,这背后,团队在挖掘和抓取互联网上的中英词汇文本信息方面付出了大量精力。「我们发现,很多互联网信息有很大价值,图像就是一个未被开采的巨大金矿。我博士研究方向是人机交互,也非常关注基于视觉的项目。可惜那时候,技术还达不到现在这样的水平。」黄鼎隆说道。
直到 2014 年,深度学习火花溅起,解决图像问题的技术手段愈发成熟。黄鼎隆意识到,之前所留意到的图像金矿开始有机会被挖掘出来了,深度学习技术正是打开这个宝库的钥匙。「这是一个很好的方向,我们一拍即合,决定义无返顾地去创业。」黄鼎隆说。
在基于深度学习与计算机视觉技术进行探索的道路上,码隆科技选择聚焦在商品识别领域,并将这一定位从成立贯穿至今。而专注于细分方向并建立足够的护城河,也是吸引软银中国领投 B 轮融资的重要原因之一。
开发弱监督式学习方法,跨越真实场景中的数据难题
商品识别,也就是让计算机像各个行业的专家一样识别出各种商品,比如像零售业专家一样认识各种品类的快消品,像时装设计师一样根据图片掌握、分析各种时尚信息。3 年来,公司把商品识别深入覆盖到纺织、时尚、图像版权、家具、医药、营销等多个垂直行业。
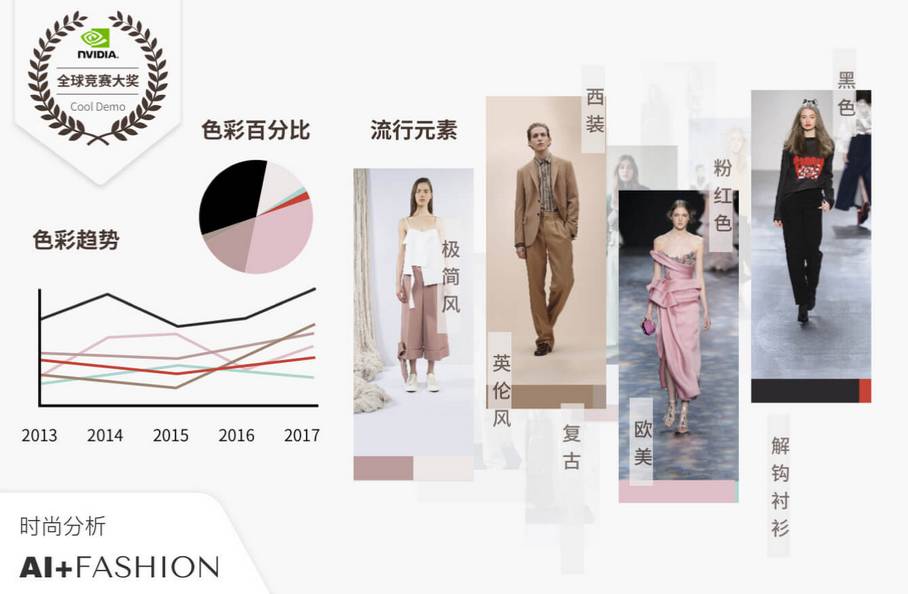
需要一提的是,识别商品与识别物体不同,不仅要知道识别的对象是什么,还要从不同的维度理解识别的对象,例如商品的各种属性,包括风格、颜色、材质、面料等。除此之外,不同应用场景下的商品也有具体不同的特性。
「我们遇到了两大技术难点,」黄鼎隆表示。
团队在研发过程中发现,有许多商品是柔性的,会随着外界影响发生形变而且没有固定的特征。很明显,相比五官特征有规律的人脸,衣服形态特征差异巨大,比如被穿在身上、平铺在桌面以及揉成一团的时候,训练所需的特征都不一样,给识别带来的挑战极大。为了提高识别力,团队采用深度学习技术,训练计算机自己学习如何进行识别。
但与此同时,第二个问题也随之而来——用于模型训练的商品数据往往是「不干净、不均衡」的。
众所周知,对有监督学习来说,标准数据至关重要。但无论是从互联网上抓取到还是由企业提供的商品数据标签,可能并不准确。另外,一些商品数据较为稀缺,会产生数据不平衡的问题。为改善有监督学习效果,码隆科技开发了一套弱监督式学习方法,能够有效利用含有「噪音」——也就是不规整的数据,并且基于此训练出一个能够与人类媲美的 AI 模型。

为了验证这个方法,码隆科技在今年 7 月参加了 CVPR (IEEE Conference on Computer Vision and Pattern Recognition,IEEE国际计算机视觉与模式识别会议)的 WebVision 竞赛。WebVision 被誉为接棒 ImageNet 的图像识别竞赛,主要区别在于其数据集直接从互联网上抓取,没有经过人工标注,含有大量的噪音,而且不同类别的数据量十分不平衡。这种更贴近于真实应用场景的数据环境,使得比赛的挑战难度也更大。码隆科技利用自主研发的弱监督式学习夺得冠军,并且大幅度领先第二名。
「在 ImageNet 这种理想化数据集上的提升已经基本接近于极限值,近几年内也没有出现太过创新的算法,更多是把比拼放在在算力方面。我想这也是 WebVision 提出不干净、不平衡数据的原因,需要有新的算法出现。」黄鼎隆补充道,「无监督学习是一个美好的未来,但在短期内全世界范围还没有看到一个可行的方案。所以在这种情况下,弱监督式学习是最佳的落地方案。」
聚焦三大领域,积极拓展应用平台
不过,任何产品的商业落地都是一个系统工程。技术之外,找到行业中的真实需求,然后定义好这个问题本身才是技术落地的关键。

码隆科技的办法是搭建一个普适性的自助式人工智能应用平台 ProductAI,让不同行业的客户用更简单高效的方式使用其技术方案。另一方面,码隆优先选择人工智能、计算机视觉技术应用价值较大的领域,也就是所谓的头部行业,尝试与这些领域内的客户深度结合,挖掘他们的真实需求,最后提供一个端到端的解决方案方案。
这是黄鼎隆口中的「一横一纵」策略,横向基于 ProductAI 平台不断向外拓展,纵向则将产品与各垂直行业需求紧密结合,为企业提供端到端的解决方案从而这些帮助行业上百倍地提升效率。
当然,在挖掘行业需求的过程中不可避免地会出现一些「伪需求」。曾有一个公司想用 AI 技术来解决穿衣搭配问题,让机器从那些时尚博主、明星的穿搭经验中摸索出规律。码隆团队琢磨之后,明确这种应用算不上真正的「刚需」,提出以图搜图的方案。因为搭配效果是落在图片上,明星街拍照片、社交媒体上点赞较多的穿搭图片已经非常直观,只需要用以图搜图的方式找到某一件单品都在什么图片中出现过,就可以帮助用户解决搭配的问题。相较于文字这种需要用户消化理解的形式,图片反而更加简洁清晰,也就是所谓的「一图胜千言」。
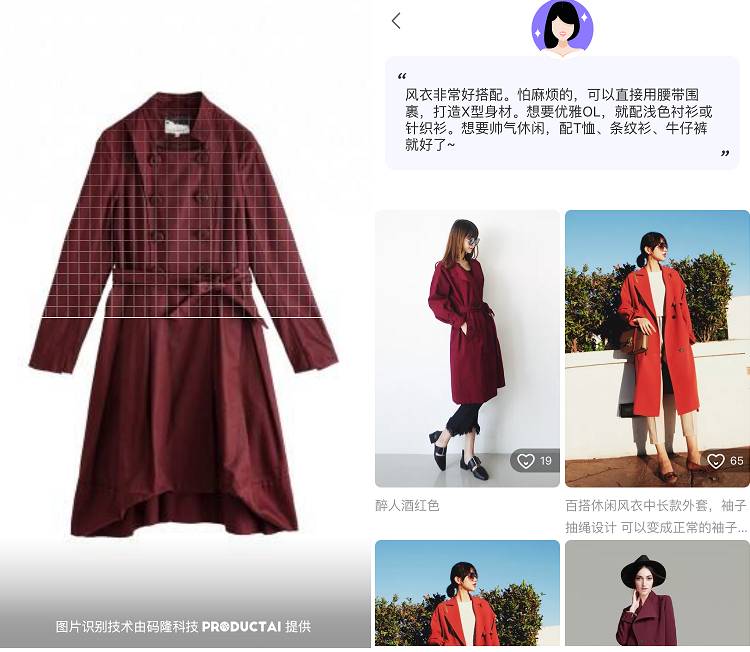
码隆科技与穿衣助手合作,让消费者可以通过搜索服饰照片,找到对应的服装搭配推荐
根据码隆的说法,自 2016 年 10 月发布至今,ProductAI 平台上的企业客户累积超过 200 个,并与中国纺织信息中心、京东商城、唯品会、卷皮、可口可乐、优料宝、家图网等合作,商品识别覆盖超过 20 多个垂直领域,能够在各领域的图像中找出图中所包含的商品并给出多达 20000 个以上的标签。在服装属性识别方面,ProductAI 的标准准确率甚至超越人类相关专家的水准。
目前,公司核心业务聚焦在服装纺织、家居家装以及新零售三个领域。其中,服装纺织是码隆科技 2014 年创业之初最先切入的领域,已经开始积极开拓海外市场。
「眼下人工智能的发展还处于早期阶段,真正的大机会其实还没有出现。我们会一直专注在商品识别方向,这是一个很大的空间。」黄鼎隆说。


往期文章
大公司:微软、亚马逊、阿里、百度、腾讯、英伟达、苏宁、西门子、浪潮
创业公司:商汤科技、依图科技、思必驰、竹间智能、三角兽、极限元、云知声、奇点机智、景驰科技、思岚科技、追一科技、海知智能、出门问问、钢铁侠科技、体素科技、晶泰科技、波士顿动力、弘量研究、小源科技、中科视拓
人物报道:吴恩达、陆奇、王永东、黄学东、任小枫、初敏、沈威、肖建雄、司罗、施尧耘
自动驾驶:传统变革、Uber、图森未来、速腾聚创、驭势科技、全球汽车AI大会






