CNCC技术论坛 | 深度强化学习进展、应用与未来

2018中国计算机大会(CNCC2018)将于10月25-27日在杭州国际博览中心(G20会场)举行,大会主题为「大数据推动数字经济」(Big Data Drives the Digital Economy)。
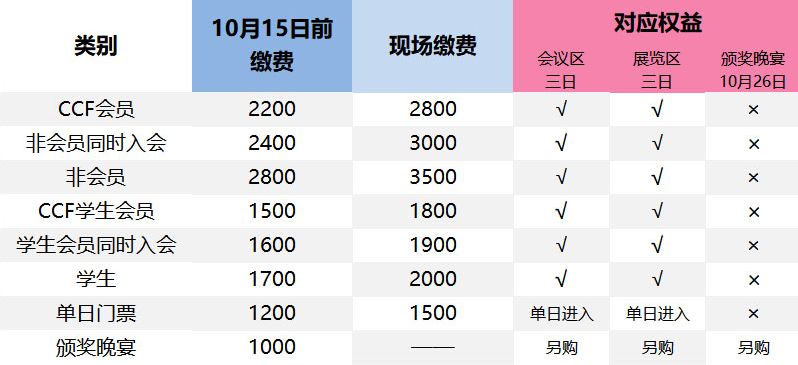
10月15日前报名可享优惠,详见文末信息。
时间:10月25日下午13:30-17:30
地点:杭州国际博览中心会议区 一层多功能厅A
强化学习旨在实现可自主适应环境的智能体,被DeepMind认为是实现其“通用人工智能”理想的主要途径之一,并且在AlphaGo到AlphaGo Zero的演进中起到了越来越重要的作用。然而强化学习技术有较高的应用门槛,虽然近期逐渐受到业界的重视,在落地应用上还有不少局限。论坛有幸邀请到六位来自企业和高校的强化学习专家,介绍强化学习的进展与应用,共同讨论强化学习的潜力与未来。
论坛主席
南京大学计算机科学与技术系
俞扬

简介:俞扬博士,南京大学副教授。主要研究领域为强化学习。于2011年获得南京大学博士学位,学位论文被评为全国优秀博士学位论文、CCF优秀博士学位论文。2011年8月起在南京大学计算机科学与技术系、机器学习与数据挖掘研究所(LAMDA)从事教学与科研工作。入选2018年IEEE Intelligent Systems杂志评选的AI's 10 to Watch,获PAKDD 2018 Early Career Award,受邀在IJCAI 2018做Early Career Spotlight演讲。参与的队伍在2018 OpenAI Retro Contest强化学习竞赛中取得冠军。

特邀讲者
讲者一:蚂蚁金服/佐治亚理工大学
宋乐

简介:Le Song is a Principal Engineer at Ant Financial AI Department, and he is also an Associate Professor in the College of Computing, and an Associate Director of the Center for Machine Learning, Georgia Institute of Technology. He is leading the development of a large scale deep learning platform for financial transaction graphs at Ant Financial with applications to problems such as credit estimation, risk management for micro-loans, and fraud detection in insurance. He received his Ph.D. in Machine Learning from University of Sydney and NICTA in 2008, and then conducted his post-doctoral research as Carnegie Mellon University and Google between 2008 and 2011. His principal research direction is machine learning and AI, especially nonlinear models, such as kernel methods and deep learning, and probabilistic graphical models for large scale and complex problems. He has received many academic awards, such as the Recsys’16 Deep Learning Workshop Best Paper Award, AISTATS'16 Best Student Paper Award, IPDPS'15 Best Paper Award, NSF CAREER Award’14, NIPS’13 Outstanding Paper Award, and ICML’10 Best Paper Award. He has also served as the area chair or senior program committee for many leading machine learning and AI conferences such as ICML, NIPS, AISTATS, AAAI and IJCAI. He is also the action editor for JMLR, and associate editor for IEEE PAMI.
演讲题目:Learning Algorithms over Networks
摘要:The design of good heuristics or approximation algorithms for NP-hard combinatorial optimization problems often requires significant specialized knowledge and trial-and-error. Can we automate this challenging, tedious process, and learn the algorithms instead? In many real-world applications, it is typically the case that the same optimization problem is solved again and again on a regular basis, maintaining the same problem structure but differing in the data. This provides an opportunity for learning heuristic algorithms that exploit the structure of such recurring problems. In this talk, I will present a unique combination of reinforcement learning and graph embedding to address this challenge. The learned greedy policy behaves like a meta-algorithm that incrementally constructs a solution, and the action is determined by the output of a graph embedding network capturing the current state of the solution. I will show that this framework can be applied to a diverse range of optimization problems over graphs, and learns effective algorithms for the Minimum Vertex Cover, Maximum Cut and Traveling Salesman problems.
讲者二:清华大学
苏航

简介:苏航博士,清华大学计算机系助理研究员,中国计算机学会计算机视觉专家委员会委员,中国人工智能学会机器学习专委会委员。主要关注可理解人工智能理论、计算机视觉和强化学习等相关领域,先后CVPR、IJCAI、ECCV和TMI等人工智能顶级国际会议和期刊发表论文将50余篇,并荣获ICME2018“白金最佳论文”,AVSS2012“最佳论文奖”和MICCAI2012的“青年学者奖”,作为主要技术负责人,获得 ViZDoom 2018国际FPS赛事历史上首个中国区冠军。曾30余次受邀担任人工智能顶级国际会议IJCAI、AAAI、CVPR的程序委员会高级委员或委员,以及TPAMI、ICML,NIPS等十余个重要国际会议和期刊的审稿人。近年来,作为项目负责人,受到国家自然科学基金面上项目、中国博士后基金等多个国家级项目资助;并作为核心骨干,参与国家重点研发计划、国家自然科学基金国际合作项目等多个重大国家级项目。
演讲题目:融合知识引导的深度强化学习及其在FPS游戏中的应用
摘要:深度强化学习在围棋等任务上获得了很大成功,引起相关研究者的广泛关注。但是在不确定性、信息不完全、动态博弈等情况下,深度强化学习往往面临决策空间巨大、奖励函数设计困难和探索效率低下等挑战。本报告针对目前深度强化学习所面临的问题,介绍人类领域知识、隐性经验和深度强化学习的融合机制,探讨利用人类知识降低信息不完整性、实现高效探索等问题的解决方案。利用相关方法,我们在多智能体FPS游戏竞赛VizDoom2018上获得了Track 1的预赛和决赛冠军,及Track 2 预赛冠军、决赛亚军,成为该赛事历史上首个中国区冠军,本报告将介绍我们的解决方案。
讲者三:上海交通大学
张伟楠

简介:张伟楠博士,上海交通大学计算机系、约翰·霍普克罗夫特研究中心助理教授,研究方向为深度强化学习、无监督学习及其在数据挖掘问题中的应用。他于2011年毕业于上海交通大学计算机系ACM班,于2016年获得英国伦敦大学学院计算机系博士学位,研究成果在国际一流的会议和期刊上发表50余篇论文,其中5次以第一作者身份在ACM国际数据科学会议KDD上发表;2016年获得由微软研究院评选的“全球SIGKDD Top 20科研新星”称号;2017年获得ACM国际信息检索会议SIGIR的最佳论文提名奖;2017年获得上海ACM新星奖。他曾在KDD-Cup用户个性化推荐大赛获得全球季军,在全球大数据实时竞价展示广告出价算法大赛获得最终冠军。此外他也曾在谷歌硅谷总部、微软剑桥研究院、微软亚洲研究院做人工智能和大数据挖掘方向的研究实习。
演讲题目:面向海量智能体系统的深度强化学习技术
摘要:近年来,机器学习的落地场景有两个发展方向,一是从预测到决策的范式拓展,另一个则是从单智能体到多智能体的场景推广。由此,面向多智能体系统的深度强化学习开始越来越受到学术界和工业界的关注。本次报告,我将从多智能体深度强化学习的几个落地任务切人,由此引入它的基本数学定义和几个经典解决方法。之后我将深入海量智能体场景下的不同场景,探讨在海量智能体的情况下,传统多智能体强化学习方法的不足,并深入介绍基于平均场理论的强化学习和基于因子分解模型的强化学习算法。最后,我将介绍MAgent,一个专为海量智能体场景提供模拟实验的平台,并展示上述算法在该平台上的初步实验效果。
讲者四:纽迈科技(上海)有限公司
吕强

简介:吕强博士,纽迈科技(上海)有限公司研发总监、规划决策部门负责人,扬州大学讲师。中科大计算机科学与技术学院学士、硕士、博士,师从中国科学院院士、博士生导师陈国良教授。2009年至2011年获国家留学基金委资助以联合培养博士生身份在美国圣路易斯华盛顿大学师从陈一昕教授进行访问研究。在校期间,获得中科院朱李月华优秀博士生奖、国家留学基金委联合培养博士生奖在内的一系列奖励资助。博士毕业后以博士后研究员身份参与中科大多智能体系统实验室多机器人系统研制,博士后出站加入扬州大学,主要从事人工智能、机器学习、自动规划与调度研究。作为项目负责人,承担了国家自然科学基金青年基金、江苏省自然科学基金青年基金、江苏省省属高校自然科学基金面上项目、中国博士后基金、中科大青年创新基金等一系列科研项目。并参与多项由中国国家自然科学基金战略基础性研究、美国自然科学基金、微软学院奖学金资助的研究项目。作为第一作者在国际顶级学术会议AAAI、国际顶级期刊ACM TIST,EAAI上发表学术论文,作为实际贡献者在国际顶级期刊IEEE TSC上参与发表学术论文。发表论文20余篇,其中最佳会议论文1篇。
演讲题目:无人驾驶汽车中的前方车辆变道预测
摘要:强化学习(RL)作为机器学习的一个子领域,其灵感来源于心理学中的行为主义理论,即智能体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。它强调如何基于环境而行动,以取得最大化的预期利益。通俗的讲:就是根据环境学习一套策略,能够最大化期望奖励,强化学习的这种普适性为其在自动驾驶领域的应用奠定了广阔的基础。本文介绍了一种基于LSTM模型的前方车辆变道预测算法,并以此作为强化学习框架中计算奖励环节的核心算法。从实验结果来看,该算法在carmaker仿真器和实际车辆上均取得了良好的效果,相比于基于规则的前方车辆变道判断算法能提前1-2秒判断出其是否变道,使得自动驾驶可以提供更加舒适的减速和更加安全的提前急刹车。
讲者五:天壤智能
薛贵荣

简介:薛贵荣博士,天壤智能创始人及CEO,原阿里巴巴旗下阿里妈妈大数据中心负责人、阿里妈妈首席数据科学家、阿里云资深总监,负责研发了阿里搜索引擎、数据管理平台、营销技术平台等。在此之前曾经任职于上海交通大学计算机系。KDD中国分会、CCF人工智能专委会、CCF大数据专委会委员。研究方向主要为深度强化学习、迁移学习、互联网搜索、大数据等,在国际会议和国际期刊发表论文70多篇。2006年于上海交通大学获得博士学位并获得中国计算机学会评选的CCF优秀博士论文奖。
演讲题目:城市大脑中的深度强化学习
摘要:随着人口的快速增长,城市的规模预计将快速增长,城市基础设施的有效管理势在必行,这其中有非常挑战的问题都需要人工智能的技术深度参与。以深度强化学习为代表的人工智能技术发展迅猛,使得机器从基本的预测扩展到了多种多样高难度的决策中。本报告将围绕城市大脑中的多个应用场景,对需要构建的深度强化学习系统、算法和场景等多个方面的问题进行深入阐述,并给出未来的挑战。
讲者六:阿里巴巴
曾安祥

简介:曾安祥,花名仁重,阿里巴巴资深算法专家。于2009年加入阿里巴巴,作为淘宝搜索的创始人之一,先后参与组建了Query分析团队和排序团队等算法团队,和伙伴们一起创造了在全球范围内领先的商品搜索技术。专注于大规模机器学习,在线学习,深度学习强及化学习等技术在电商环境中的大规模实际应用。发表了多篇顶会论文,申请了多个国内外专利。
演讲题目:游戏之外:电商场景下强化学习建模与应用
摘要:近年来,强化学习通过与深度学习结合,解决海量数据的泛化问题,取得了让人印象深刻的成果。包括DeepMind的自动学习玩ATARI游戏,以及AlphaGo在围棋大赛中战胜世界冠军等,其背后的强大武器就是深度强化学习技术。相对于 DeepMind 和学术界看重强化学习的前沿研究,阿里巴巴则将重点放在推动强化学习技术输出及商业应用。在阿里移动电商平台中,人机交互的便捷,碎片化使用的普遍性,页面切换的串行化,用户轨迹的可跟踪性等都要求我们的系统能够对变幻莫测的用户行为以及瞬息万变的外部环境进行完整地建模。平台作为信息的载体,需要在与消费者的互动过程中,根据对消费者(环境)的理解,及时调整提供信息(商品、客服机器人的回答、路径选择等)的策略,从而最大化过程累积收益(消费者在平台上的使用体验)。基于监督学习方式的信息提供手段,缺少有效的探索能力,系统倾向于给消费者推送曾经发生过行为的信息单元(商品、店铺或问题答案)。而强化学习作为一种有效的基于用户与系统交互过程建模和最大化过程累积收益的学习方法,在一些阿里具体的业务场景中进行了很好的实践并得到大规模应用。在这个报告中,我们将介绍强化学习在搜索排序建模、引擎性能优化、流量调控以及跨场景联合优化等方面的应用,同时分享一些我们在实际建模时的一些体会和心得。

更多信息详见大会官网:http://cncc.ccf.org.cn
即日起至10月15日,报名且缴费成功即可按优惠价格参加CNCC2018! CCF会员参会、参展可享优惠。

请扫描二维码报名参会
咨询电话:010-6260 0336 邮箱:cncc_pr@ccf.org.cn
中国计算机学会

长按识别二维码关注我们
CCF推荐
【精品文章】
CNCC技术论坛|新型硬件环境下大数据处理技术
CNCC技术论坛|盘活大数据资产
CNCC技术论坛 | 11位企业高管担任技术论坛主席,四大亮点逐个看
CNCC技术论坛 | 当计算机系统遇上人工智能
CNCC技术论坛| E级处理能力下超级计算与智能计算的融合发展
CNCC技术论坛|智能健康感知与计算
CNCC技术论坛|下一代互联网络,未来已来
CNCC技术论坛|自然语言生成:机器写作背后的技术
CNCC2018技术论坛|AI作恶,是世界末日还是杞人忧天?
CNCC2018讲者|吴军:曾经渴望用算法和代码屹立世界之巅的程序员
CNCC2018技术论坛 | 自主可控软件,如何进行生态建设
CNCC2018讲者|李国杰:发展数字经济值得深思的几个问题
CNCC2018讲者|黄铭钧:企业级区块链系统再思考
CNCC 2018讲者 | 吕建院士:自主提出「网构软件」,致力于探索新型软件方法学
CNCC2018讲者|图灵奖获得者、TCP/IP协议的奠基者:罗伯特·卡恩
点击“阅读原文”,报名参会。




