美国抄中国算借鉴?中国团队「CVPR剽窃案」控诉无果,IBM被判无罪
![]()
新智元报道

新智元报道
【新智元导读】此前,IBM被指巧妙地「借鉴」了中国团队研究成果的CVPR中稿论文,近日,IEEE定案——不构成抄袭。
来龙去脉


(详情可点击阅读:「CVPR再度上演抄袭大戏!IBM中稿论文被指照搬自己承办竞赛第二名的idea」)

对此,一位业内人士解释称:「IEEE基本上不会处理这些在文字上没有明显抄袭的案件。一方面,IEEE的编辑、秘书不是技术专家, 他们在审核的时候也只是看看文字抄没抄。另一方面,在这次的事件中,IEEE也没有邀请外部专家进行审查。」
「所以,只要抄袭者自己不认,而且没留下什么证据(不抄图,不抄字)。出版社是不会处理的。」
双方相继发文回应



不过在此之前,我们先介绍一下牛津大学关于「剽窃」(Plagiarism)的标准定义:
在没有充分承认的情况下将他人的作品或想法复制或转述到自己的作品中。所有已发表和未发表的材料,无论是手稿、印刷品还是电子形式,都属于这一定义的范围。「共谋」(Collusion)是另一种形式的剽窃,涉及学生或其他个人在作品中未经授权的合作。
1 我们没有抄袭idea
-
我们在2019年就提出了「双解码器」的方法,而TableMaster的工作在2021年才发表。
-
EDD4的公共代码包含了边界框回归的想法,这比TableMaster的代码库和论文要早。在定量分析部分,被称为「EDD+BBox」。
-
TableFormer的网络架构与TableMASTER-mmocr并不一样。TableMASTER-mmocr使用的是双Transformer解码器,以及文本线检测(基于PSENET)。但TableFormer使用的是单一的Transformer解码器,其输出结果首先用于注意力网络,然后与DETR头一起预测边界框。
TableMaster团队回应:原理一样,且参考文献里压根没提的方法,怎么实现的?
2 我们没有抄袭模型
-
我们使用原始PDF的内容。
-
我们没有用到TableFormer的「文本行检测」或「文本行识别」。事实上,我们根本不需要这个步骤,因为我们没有用到任何OCR。
-
我们用的是同事开发的原始PDF,来创建PubTabNet数据集。
-
我们用的是同事在2018年发表的方法,来从PDF中提取内容。
TableMaster团队回应:别人是看图像,自己直接读原始数据,您识别了个寂寞?
3 我们没有抄袭可视化实现
-
使用边界框来可视化检测是计算机视觉中的一项标准技术。
-
在TableMaster的文章之前的许多论文,都是用边界框来可视化表格中的检测的。其中一个例子就是IBM在2020年所做的工作。
-
我们的可视化是用Javascript/HTML代码制作的,它具有独特的视觉效果,简化了不同阶段预测的比较过程。
TableMaster团队回应:视觉效果像素级相似,但论文却一眼都没看?
4 我们没有抄袭预处理方法
-
我们的数据准备阶段的一些步骤,是TableMaster的工作中没有的。例如,引入了一个生成缺失边界框的程序。
-
在论文中,我们详细解释了使用512个token的理由。
-
HTML分类token不是由TableMaster的工作所定义的,而是IBM在EDD在2019年首次描述的。
-
甚至TableMaster的截图也显示了,两篇的工作的不同,因为我们使用了「未折叠」的token(「<td>」, 「</td>」),而他们使用的是「折叠」的token(「<td,/td>」)。
TableMaster团队回应:被自己办的竞赛方案吊打,您这是重新发明了SOTA?
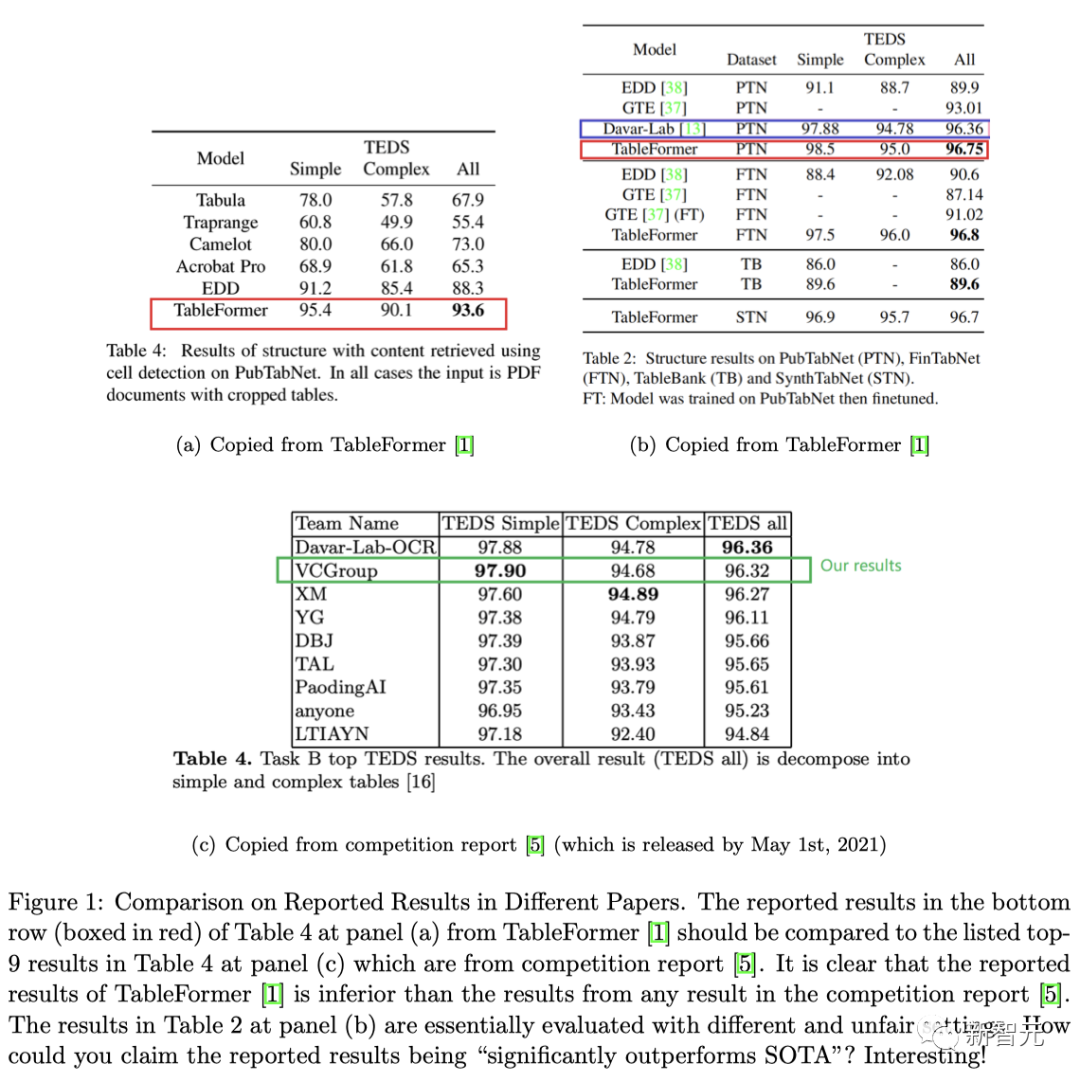
5 我们没有抄袭后处理方法
-
TableFormer直接从PDF文档中提取文本,它没有使用任何OCR。因此,我们模型的输出是不同的,使用的后处理方法也不同。
-
TableFormer的后处理管线比TableMaster的工作更复杂。
-
在推理过程中对自回归方法进行缓存,是大家都知道的方法。它已经由开源神经机器翻译(OpenNMT)实现,并在这篇文章中进行了描述。
TableMaster团队回应:把3个点拆成了9个,就是更复杂的创新了?
6 我们没有混淆视听
-
我们并不知道TableMaster的工作。甚至在论文的审查过程中,也没人提到过有这么一篇TableMaster的论文。
-
正如之前所说,我们是在同事的工作基础上进行的,这些工作比TableMaster要早。
-
在向我们的同事群发电子邮件,以及在Reddit上发表指责的帖子之前,TableMaster团队并没有联系我们。如果TableMaster在公开指责之前联系的话,那么我们会乐意证明我们的观点,并引用TableMaster的工作,比较各种方法。
-
我们愿意与TableMaster进行讨论,以进一步澄清上述所有问题,并证明我们的工作没有抄袭甚至没有受到TableMaster的启发。
-
我们要求撤回对抄袭的指控,并向我们道歉。
-
如果TableMaster团队还不相信,我们不介意他们联系CVPR。我们在代码(git历史)和文档方面有大量的证据,可以证明这些指控完全没有根据,是错误的。
TableMaster团队回应:群众的眼睛是雪亮的!


登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月23日
Arxiv
0+阅读 · 2022年11月22日
Arxiv
17+阅读 · 2018年3月20日
Arxiv
14+阅读 · 2018年3月14日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月23日
Arxiv
0+阅读 · 2022年11月22日
Arxiv
17+阅读 · 2018年3月20日
Arxiv
14+阅读 · 2018年3月14日