EMNLP2019获奖论文出炉,最佳论文一作华人,导师为NLP公认大神Jason Eisner

作者 | 杨晓凡 & Camel
编辑 | 唐里

EMNLP2019 最佳论文获奖者全家福
一、最佳论文奖

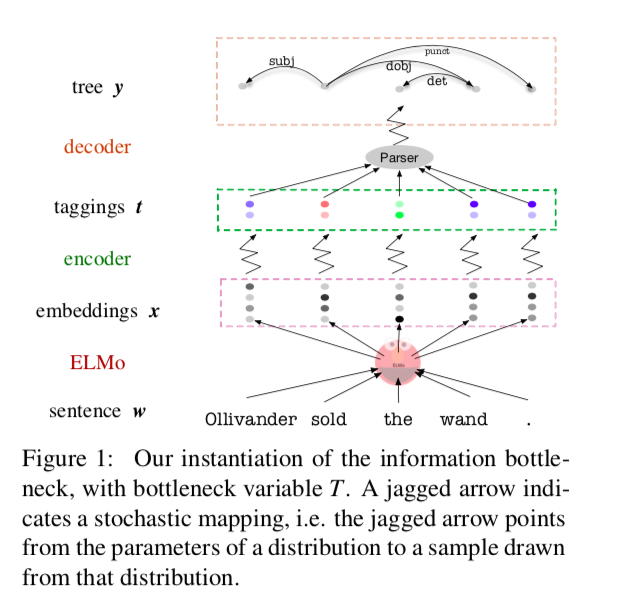 这篇论文中作者提出了一个非常快速的变差信息瓶颈(Variational Information Bottleneck,VIB)方法,它可以非线性地压缩这些嵌入,只保留对辨别性解析器有帮助的信息。作者可以把每个词嵌入压缩成一个个离散的标签,或者是连续的向量。对于离散标签版本,这些自动压缩的标签可以形成一种替代性的标签集合。
这篇论文中作者提出了一个非常快速的变差信息瓶颈(Variational Information Bottleneck,VIB)方法,它可以非线性地压缩这些嵌入,只保留对辨别性解析器有帮助的信息。作者可以把每个词嵌入压缩成一个个离散的标签,或者是连续的向量。对于离散标签版本,这些自动压缩的标签可以形成一种替代性的标签集合。
二、最佳论文第二名

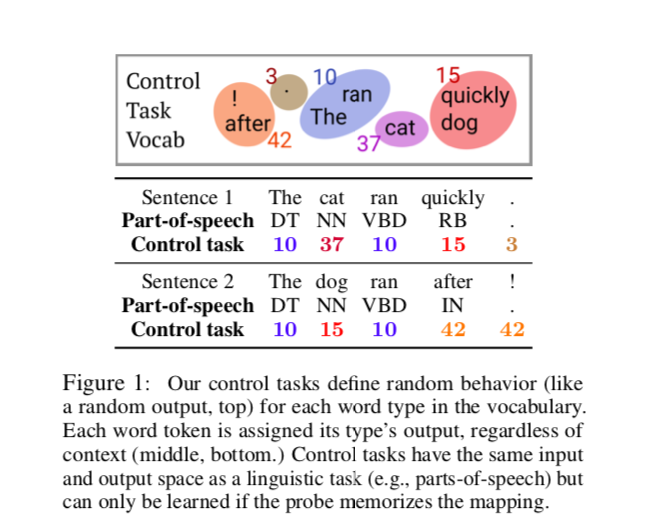 设计这些任务的考虑就是,它们只能够被探针自己学会,也就成为了检验探针能力的方法。所以,一个好的探针(能切实反应表征的内涵的探针),应当是有选择性的,应当能在真正的语言学任务中取得高准确率,而在这个控制任务中取得低准确率。探针的选择性的体现,就是真语言学任务中的准确率和探针记忆单词类型的能力是一致的。
设计这些任务的考虑就是,它们只能够被探针自己学会,也就成为了检验探针能力的方法。所以,一个好的探针(能切实反应表征的内涵的探针),应当是有选择性的,应当能在真正的语言学任务中取得高准确率,而在这个控制任务中取得低准确率。探针的选择性的体现,就是真语言学任务中的准确率和探针记忆单词类型的能力是一致的。

三、最佳资源奖

四、最佳Demo奖




登录查看更多
相关内容

专知会员服务
24+阅读 · 2019年11月20日
Arxiv
4+阅读 · 2018年2月19日
Arxiv
4+阅读 · 2017年8月17日




相关VIP内容
专知会员服务
24+阅读 · 2019年11月20日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年2月19日
Arxiv
4+阅读 · 2017年8月17日