如何使用大蒙版修复LaMa隐藏图像中的对象?

重建图像中缺失的区域,使得观众不能辨别出哪些区域是否被修复,称为图像修复。这种方法通常用于删除图片中不需要的内容,或者还原老照片的受损部分。
图像修复是一种有数百年历史的技术,是由人类艺术家手工完成的。它涉及填补艺术品的受损、变质或缺失区域,从而创造一幅完整的图像。油画或丙烯酸颜料、化学照片版画、雕塑、数字照片和视频都是可以用于这种方法的物理和数字艺术载体的例子。要解决图像修复问题,逼真地填补缺失的部分,就需要“理解”自然图像的大尺度结构,并对其进行图像合成。
近年来,学者们提出了各种自动化的修复方法。除了图像之外,这些算法中大多数都需要一个蒙版来显示修复区域作为输入。这个主题在深度学习出现之前就已经被研究过,近年来由于深入的、广泛的神经网络以及对抗学习的应用,发展加快了。
修复系统通常在一个庞大的自动生成的数据集上进行训练,该数据集通过随机掩蔽真实图像建立。复杂的两阶段模型结合中间预测,如经常被使用的平滑图像、边缘和图像分割。
这种修复网络是基于最近发展起来的快速傅立叶卷积(Fast Fourier Convolutions,FFC)。即使在网络的早期阶段,FFC 也允许一个横跨整个图像的感受野。
研究人员表示,FFC 的这一特性提高了感知质量和网络参数效率。有趣的是,FFC 的归纳偏好使得网络能够得到高分辨率,这在训练期间是不存在的。这一发现具有重要的实际意义,因为它减少了所需的训练数据量和计算量。
它还采用了感知损失,这是基于一个具有较大感受野的语义分割网络。这是基于一个发现,一个不足的感受野影响着修复网络和知觉损失。这种损失支持全局结构和形状的一致性。
一种积极的训练蒙版生成技术,可以利用前两个组成部分的高感受野的潜力。这种方法生成了大量的、庞大的蒙版,使得网络能够充分利用模型和损失函数的高感受野。
所有这些促成了大蒙版修复(LaMa),即一种划时代意义的单阶段图像修复技术。高感受野架构 (i) 具有高感受野损失函数 (ii) 和激进的训练掩模生成算法 LaMa (iii) 的核心组成部分。我们将 LaMa 和目前的基准进行了严格的对比,并且对每一个建议组成部分的效果进行了评估。
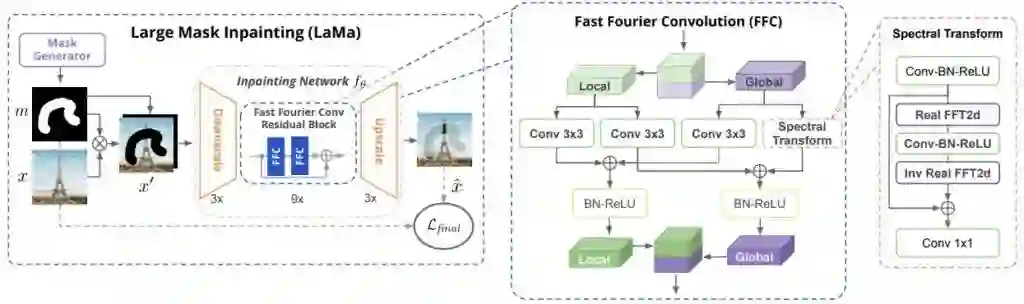
大蒙版修复方案如上图所示(LaMa)。可以看出,LaMa 是基于一种前馈 ResNet 类修复网络,该网络采用了以下技术:最近提出的快速傅立叶卷积 (FFC),一个结合了对抗性损失和高感受野感知损失的多分量损失,以及一个训练时间较长的蒙版生成过程。
在本节中,我们将了解 LaMa 的官方实现,以及它是怎样有效地掩蔽用户标记的对象的。
让我们通过安装并导入所有的依赖关系来创建环境。
# Cloning the repo
!git clone https://github.com/saic-mdal/lama.git
# installing the dependencies
!pip install -r lama/requirements.txt --quiet
!pip install wget --quiet
# change the directory
% cd /content/lama
# Download the model
!curl -L $(yadisk-direct https://disk.yandex.ru/d/ouP6l8VJ0HpMZg) -o big-lama.zip
!unzip big-lama.zip
# Importing dependencies
import base64, os
from IPython.display import HTML, Image
from google.colab.output import eval_js
from base64 import b64decode
import matplotlib.pyplot as plt
import numpy as np
import wget
from shutil import copyfile
import shutil
为了方便用户在给定的图像中掩蔽所想掩蔽的对象,我们需要编写 HTML 代码。

现在,我们将上传我们想要掩盖其中的对象的图片,为其设置为 fname=None,蒙版将掩盖该对象。
if fname is None:
from google.colab import files
files = files.upload()
fname = list(files.keys())[0]
else:
fname = wget.download(fname)
shutil.rmtree('./data_for_prediction', ignore_errors=True)
! mkdir data_for_prediction
copyfile(fname, f'./data_for_prediction/{fname}')
os.remove(fname)
fname = f'./data_for_prediction/{fname}'
image64 = base64.b64encode(open(fname, 'rb').read())
image64 = image64.decode('utf-8')
print(f'Will use {fname} for inpainting')
img = np.array(plt.imread(f'{fname}')[:,:,:3])
draw(image64, filename=f"./{fname.split('.')[1]}_mask.png", w=img.shape[1], h=img.shape[0], line_width=0.04*img.shape[1])

现在,我们将掩蔽图像中的鹿,就像我们通常在 Paint 应用程序中做的那样。

下面我们可以看到该模型是如何将被掩蔽的图像与原始图像进行卷积。

现在我们将进行推理。
print('Run inpainting')
if '.jpeg' in fname:
!PYTHONPATH=. TORCH_HOME=$(pwd) python3 bin/predict.py model.path=$(pwd)/big-lama indir=$(pwd)/data_for_prediction outdir=/content/output dataset.img_suffix=.jpeg > /dev/null
elif '.jpg' in fname:
!PYTHONPATH=. TORCH_HOME=$(pwd) python3 bin/predict.py model.path=$(pwd)/big-lama indir=$(pwd)/data_for_prediction outdir=/content/output dataset.img_suffix=.jpg > /dev/null
elif '.png' in fname:
!PYTHONPATH=. TORCH_HOME=$(pwd) python3 bin/predict.py model.path=$(pwd)/big-lama indir=$(pwd)/data_for_prediction outdir=/content/output dataset.img_suffix=.png > /dev/null
else:
print(f'Error: unknown suffix .{fname.split(".")[-1]} use [.png, .jpeg, .jpg]')
plt.rcParams['figure.dpi'] = 200
plt.imshow(plt.imread(f"/content/output/{fname.split('.')[1].split('/')[2]}_mask.png"))
_=plt.axis('off')
_=plt.title('inpainting result')
plt.show()
fname = None
下面是修复后的图像:

真是令人振奋的结果。
我们在本文中讨论了一个基本的、单阶段的解决方案的用法,用于大部分掩蔽部分的修复。我们认为,只要有合适的架构、损失函数和蒙版生成方法,这样的方法将会极具竞争力,从而促进图像修复技术的发展。特别是当涉及重复性像素时,这种方法能取得很好的效果。我建议大家用自己的照片多做实验,或者也可以在论文中找到更多的信息。
官方研究论文(https://arxiv.org/pdf/2109.07161.pdf)
官方 GitHub 仓库(https://github.com/saic-mdal/lama)
本文代码的链接(https://colab.research.google.com/drive/1aIcNFWOGL1jjCWH_AExgqyROVOBNsY-s?usp=sharing)
作者介绍:
Vijaysinh Lendave,机器学习和深度学习的爱好者。熟练掌握机器学习算法,数据操作,处理和可视化,模型构建。
原文链接:
https://analyticsindiamag.com/how-to-hide-objects-in-images-using-large-mask-inpainting-lama/

你也「在看」吗?👇


