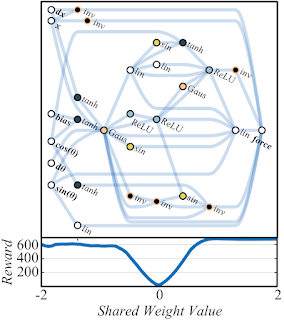
![]()
我们都知道谷歌有庞大的研究机构规模,谷歌的研究人员们有的从事算法理论研究、有的从事算法应用研究,而在两个方向中,谷歌都是重要的中坚力量,每年都会产出许多前瞻性的、或者带来重大改进的、或者有很高应用价值的研究成果。
以谷歌 AI 为核心的谷歌研究院的目标就正是“研究长期的、有重大意义的问题,其中重点关注那些能给普通大众带来更好生活的问题”。
2019 年结束以后,谷歌研究院副总裁、谷歌技术传奇人物 Jeff Dean 和往年一样执笔(键盘)写下了谷歌研究院2019年的年终总结。在这一年中,谷歌在医疗、机器人等新兴领域做出了大量技术应用成果,也给谷歌的产品线增加了许多新成员、新功能。
Jeff Dean的年终总结中同时涵盖了许多产品开发和学术研究成果,我们更关注其中的学术研究成果,这篇文章就把这些学术研究成果翻译介绍如下。
如果量子计算机投入使用,它将可以大大简化材料科学、量子化学、大规模优化等问题的难度。不过目前距离那一步还有很远的距离,我们需要继续做出努力,推动这个领域前进。
谷歌的下一个研究重点是在量子计算中实现量子纠错,这样可以运行耗时更久的运算。除此之外,谷歌还在研究如何让量子算法更容易表达、如何让硬件更容易控制,而且他们已经发现了可以借助深度强化学习之类的机器学习方法,来帮助构建更可靠的量子处理器。
2019年的这些量子计算研究成果给人带来很多激励,也是让量子计算更成熟、能解决世界中的真实问题的早期探索。
在通用算法和理论方面,我们继续开展从算法基础到应用的研究,同时,也做了一些关于图挖掘和市场算法的工作。我们在《图学习算法概述》这篇博客中详细介绍了这项工作。
https://ai.googleblog.com/2019/06/innovations-in-graph-representation.html
VLDB 2019 上,我们发表了一篇论文,标题是《Cache-aware load balancing of data center applications》,它还有一个备选标题——《Increase the serving capacity of your data center by 40% with this one cool trick》。这篇论文描述了我们如何利用图的均衡分割来专门化网络搜索后端服务系统的缓存,从而同样的闪存存储能够支持的查询流量提升了 48%,这让整个搜索后端能支持的查询流量提升了40%。
在 ICLR 2019 的论文《A new dog learns old tricks: RL finds classic optimization algorithms》中,我们发现了算法和机器学习之间的新的联系,这也显示了强化学习是如何有效地为线上匹配和分配此类经典的线上优化组合问题,找到最优(在最坏的情况下,一致的)算法。
我们在可伸缩算法方面的工作涵盖了大数据集的并行、在线和分布式算法:
第一,在最近发表的FOCS 2019 论文《Near-Optimal Massively Parallel Graph Connectivity》中,我们提供了一个接近最优的大型平行计算算法来连接这些部分;
第二,我们还发表了另一组论文《Coresets Meet EDCS: Algorithms for Matching and Vertex Cover on Massive Graphs》、《Distributed Weighted Matching via Randomized Composable Coresets》、《Improved Parallel Algorithms for Density-Based Network Clustering》,在理论和实践中改进了匹配的平行算法的同时,也改进了密度聚类的平行算法;
第三,我们还开展了关于黑箱模型中自适应优化子模块函数的工作(《Categorical Feature Compression via Submodular Optimization》),这项工作目前已在特征选择和词汇压缩等方面得到了一些应用。
我们还在一篇 SODA 2019 《Submodular Maximization with Nearly Optimal Approximation, Adaptivity and Query Complexity》论文中,提出了一个子模块最大化算法,它在近似因子、循环复杂度和查询复杂度这三个方面几乎都是最优的。
另外,在另一篇FOCS 2019 论文《Residual Based Sampling for Online Low Rank Approximation》中,我们提供了首个针对PCA(主成分分析)和列子集选择问题的在线乘法近似算法。
我们在其他的一些工作中,还引入半在线计算模型,假设未知的未来包括一个可预测的部分和一个对抗的部分。对于经典的组合问题,如二部图匹配和缓存,我们通过使用半在线算法,来确保可以在可能最好的在线和离线算法之间流畅地插值。
在市场算法方面,我们最近的研究工作包括,全新地理解了学习和市场之间的相互作用,并在实验设计上实现了创新。
例如,我们在《Strategizing against No-regret Learners》这篇 NeurIPS 2019 Oral 论文中,揭示了策略型智能体在常见的重复两人游戏中与一个学习智能体比赛时,具有令人惊讶的竞争优势。
我们最近聚焦于广告自动化方面的研究工作,增加了我们对于自动竞价和理解广告商的反馈行为的兴趣。在一组 WINE 2019 论文《Response Prediction for Low-Regret Agents》、《Autobidding with Constraints》中,我们研究了最大化代表广告商的对话的最优策略,以及进一步学习拍卖过程中广告商发生任何变化的反馈行为。同时,我们还研究了存在干预行为的实验设计,在此干预下,某一方的行为可能会影响另一方法的结果。
我们在一篇 KDD 2019 论文《Randomized Experimental Design via Geographic Clustering》和一篇 NeurIPS2019 论文《Variance Reduction in Bipartite Experiments through Correlation Clustering》中,展示了如何在保持实验效果的同时,定义单元以及单元群来限制干预。
2019年,我们在机器学习算法的许多领域都进行了探索,一个工作重点是了解神经网络中的训练动力学的性质。在《 Measuring the Limits of Data Parallel Training for Neural Networks》一文中,我们提出了一组实验,表明(通过批量)扩展数据并行量可以有效使模型收敛更快。
![]() 与将数据分布在多个计算设备中的数据并行性相比,模型并行性也是扩展模型的一种有效方法。
GPipe是一个通过类似于流水线CPU处理器所使用的方法的库,它可以使模型并行化更加有效:
当整个模型的一部分正在处理某些数据时,其他部分可以并行计算不同的数据。
这种流水线的结果可以组合在一起,从而来模拟更大的有效批次大小。
当机器学习模型能从原始数据输入中学习到较高级别的“经过解耦”的表征,而且这些表征就是我们希望模型能分辨的属性(猫vs卡车vs牛羚,癌组织vs正常组织)时,机器模型就能发挥出很好的效果。
推进机器学习算法的重点,主要是鼓励学习更好的表示形式,这些表示形式可以更好地推广到新的样本、问题或领域。2019年,我们在许多不同的背景下研究了这个问题:
1、《Evaluating the Unsupervised Learning of Disentangled Representations》
在这篇文章中,我们检查了哪些属性会影响从无监督数据中学习的表示形式,以便更好地理解什么才能造就良好的表示和有效的学习。
2、《Predicting the Generalization Gap in Deep Neural Networks》
在这篇文章中,我们表明可以使用边缘分布的统计来预测泛化差距(模型在数据上的性能来自训练数据的分布与其他数据分布之间的差距),这有助于我们可以更好地了解哪种模型能够更有效地泛化。
与将数据分布在多个计算设备中的数据并行性相比,模型并行性也是扩展模型的一种有效方法。
GPipe是一个通过类似于流水线CPU处理器所使用的方法的库,它可以使模型并行化更加有效:
当整个模型的一部分正在处理某些数据时,其他部分可以并行计算不同的数据。
这种流水线的结果可以组合在一起,从而来模拟更大的有效批次大小。
当机器学习模型能从原始数据输入中学习到较高级别的“经过解耦”的表征,而且这些表征就是我们希望模型能分辨的属性(猫vs卡车vs牛羚,癌组织vs正常组织)时,机器模型就能发挥出很好的效果。
推进机器学习算法的重点,主要是鼓励学习更好的表示形式,这些表示形式可以更好地推广到新的样本、问题或领域。2019年,我们在许多不同的背景下研究了这个问题:
1、《Evaluating the Unsupervised Learning of Disentangled Representations》
在这篇文章中,我们检查了哪些属性会影响从无监督数据中学习的表示形式,以便更好地理解什么才能造就良好的表示和有效的学习。
2、《Predicting the Generalization Gap in Deep Neural Networks》
在这篇文章中,我们表明可以使用边缘分布的统计来预测泛化差距(模型在数据上的性能来自训练数据的分布与其他数据分布之间的差距),这有助于我们可以更好地了解哪种模型能够更有效地泛化。
3、 《Learning to Generalize from Sparse and Underspecified Rewards》
在这篇文章中,我们研究了为强化学习指定奖励功能的方法,这些方法使学习系统可以更直接地从真实目标中学习,且不会因较长的、不理想的动作序列而分心。
AutoML,可以使学习算法实现自动化,并且在某些类型的机器学习元决策方面,与最好的人类机器学习专家相比,通常可以取得更好的结果。2019年我们继续这样方面的研究。
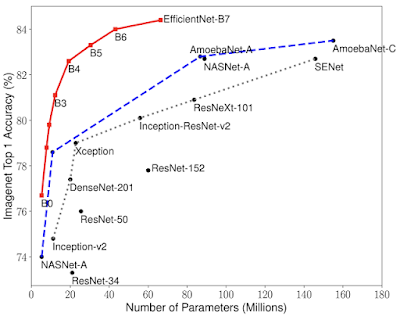
1、《EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling》
在这篇文章中,我们展示了如何将NAS技术应用到CV问题上,从而获得更好的结果,包括在ImageNet上获得最佳结果(84.4% top-1的准确度),且参数相较于此前最先进的模型少了8倍。
2、《EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML》
这项工作,我们展示了神经NAS方法如何找到针对特定硬件加速器的高效模型,从而能够在移动设备上运行高精度、低计算量的模型。
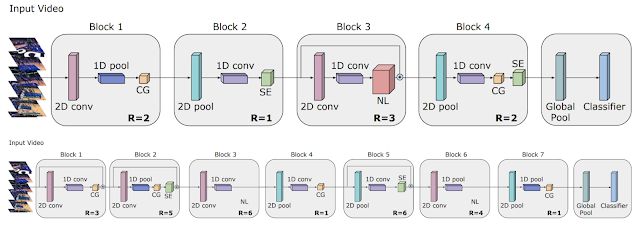
3、 《Video Architecture Search》
这篇文章,我们描述了如何将AutoML工作扩展到视频模型的领域,如何找到可实现最新结果的体系结构,以及与手工模型的性能相匹配但计算量减少50倍的轻型体系结构。
4、《
An End-to-End AutoML Solution for Tabular Data at KaggleDays
》
我们开发了用于表格数据的AutoML技术,许多公司和组织在关系数据库中都拥有一些非常有趣的数据,并且经常希望能够基于这些数据来开发机器学习模型,我们这项工作解锁了这个新的领域。我们将这项技术作为一个谷歌云 AutoML Tables的产品进行了发布。(剧透一下:AutoML Tables在74个专家数据科学家团队中获得了第二名的排名)。
5、《Exploring Weight Agnostic Neural Networks》
在这篇论文中,我们展示了如何不需要任何训练步骤,便可以更新有趣的神经网络架构,从而来更新评估模型的权重。这个工作可以使体系结构搜索的计算效率提高。
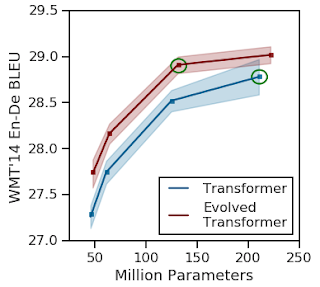
6、《Applying AutoML to Transformer Architectures 》
这篇论文探索了用于NLP任务的体系结构,这个结构在性能上远超最初的Transformer模型,大大降低了计算成本。
7、《SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition》
这里我们将自动学习数据增强方法扩展到语音识别模型当中。与现有的「ML专家」驱动的数据增强方法相比,所学习的增强方法可以用更少的数据实现更高的准确性。
8、《keyword spotting and spoken language identification using Au
toML
》
我们推出了第一款语音应用程序,使用AutoML进行关键字识别和口语识别。在我们的实验中,我们发现了一种比人工设计更好的模型(效率更高,性能更高)。
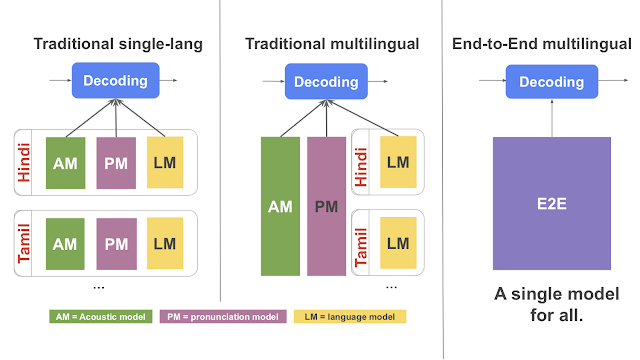
在过去的几年中,自然语言理解、翻译、对话、语音识别和其他一些相关任务的模型都取得了显著的进步。2019年,我们工作的主题之一是通过结合各种方式或任务来提高技术水平,以训练出更强大的模型。下面是一些研究案例:
1、《Exploring Massively Multilingual, Massive Neural Machine Translation》
![]()
![]()
在这项工作中,我们训练了一个模型,能够在100种语言之间进行翻译(注意并不是 100 个单独的模型),这个模型能够显著提高翻译质量。
2、《Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model》
![]()
在这篇论文中,我们展示了将语音识别和语言模型结合在一起,并在多种语言上进行训练,结果可以显著提高语音识别精度。
3、《 Translatotron: An End-to-End Speech-to-Speech Translation Model》
在这个工作中,我们证明了可以训练一个联合模型来很好地(通常是分别)完成语音识别、翻译和文本到语音生成的任务,例如在生成的翻译音频中保留说话者的声音。
4、《Multilingual Universal Sentence Encoder for Semantic Retrieval》
在这篇论文中,我们展示了如何将许多个不同的目标组合在一起,从而得到一个在语义检索方面更好的模型(相较于简单的单词匹配技术)。例如在Google Talk to Books中,查询“
What fragrance brings back memories?
”,得出的结果是:“And for me, the smell of jasmine along with the pan bagnat, it brings back my entire carefree childhood.”
5、《
Robust Neural Machine Translation
》
在这篇论文中,我们用对抗程序显著地提高了语言翻译的质量和鲁棒性。
随着对seq2seq、Transformer、BERT、Transformer-XL和ALBERT模型等的研究,我们的语言理解能力不断得以提升,这些技术都相继应用在我们的核心产品或功能中(例如Google Translate、Gmail、谷歌搜索等)。
2019年,我们将BERT嵌入在我们的核心搜索和排名算法当中,实现了在过去五年中搜索质量最大的改进(也是有史以来最大的改进之一)。
在过去的十年中,用来理解静止图像的模型有了翻天覆地的进展。下一个重大研究前沿就是要理解动态变化的世界,而且要有更细的粒度、更多的细节。这不仅包括对图像和视频有更细致的理解,也包括要有实时的、符合情境的感知;这代表着,理解世界的速度要足够快,要来得及和世界互动,同时也要设身处地地理解用户所在的空间位置。
2019年中,谷歌探索了这个领域中的许多方面,包括:
-
Lens app 中的细粒度视觉理解,它让视觉搜索功能变得更强大
-
智能照相功能,比如 Quick Gestures 摆姿势照相、Face Match 人脸匹配以及Nest Hub Max上的智能视频通话
-
Lens app 能实时感知空间信息,就可以用现实增强为用户提供帮助
-
-
通过时序循环一致性学习进行的细粒度时序视频理解中也有了更好的表征
-
从无标注视频中学习时序一致的、包括了文本、声音、视频多种模态的表征
-
-
能更好地理解视频中的动作序列的模型,在谷歌相册中使用以后能更好地追踪吹蜡烛、滑雪之类的特别瞬间
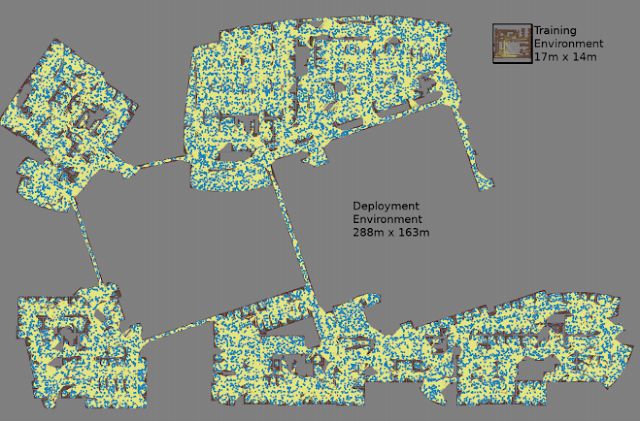
用机器学习技术来控制机器人是我们非常重视的一个研究方向。我们相信这是让机器人能在复杂的真实世界环境(比如办公室、家里)里有效运行的必不可少的手段。2019 年中,我们的相关研究成果包括:
1、《Long-Range Robotic Navigation via Automated Reinforcement Learning》
论文展示了可以把强化学习和长距离规划结合在一起,让机器人更高效地在复杂环境中导航(下图中的例子是谷歌的办公楼)
2、《PlaNet: A Deep Planning Network for Reinforcement Learning》
论文展示了如何仅仅从图像像素中高效地学习世界模型,以及如何利用这个模型学到的世界运行的知识,以便用更短的学习过程掌握各种任务。
3、《Unifying Physics and Deep Learning with TossingBot》
论文表明机器人可以通过在环境中的反复尝试学习到“直觉式”的物理知识,可以不需要先通过编程的方式为他们输入环境信息和物理规律。
4、《Soft Actor-Critic: Deep Reinforcement Learning for Robotics》
论文展示了一种可以同时让预期回报(标准的强化学习策略)和策略的熵(让智能体学到更随机的行动)最大化的强化学习算法,可以让智能体学习得更快,而且对环境中的变化更鲁棒。
5、《Learning to Assemble and to Generalize from Self-Supervised Disassembly》
论文中,机器人可以用自监督的方式先学会如何拆解东西,然后再学会如何组装,就和小孩拆东西装东西一样。
谷歌还开发了低成本机器人测试平台 ROBEL,帮助学术研究人员和企业开发人员更便捷地开发真实世界中工作的机器人硬件。
“开源”并不仅仅代表着代码,更重要的是社区中做出贡献的人。对于整个开源大家庭来说,2019年有许多值得庆祝的时刻。
在这一年中,我们正式发布了TensorFlow2.0,这是目前最大最先进的TensorFlow,它也让机器学习系统、应用的构建前所未有地简单;我们在TF Lite中加入了GPU硬件推理的支持;我们还发布了 Teachable Machine 2.0,这是一个基于网页的快捷、便于使用的工具,不需要敲代码,只需要点点鼠标就可以训练机器学习模型。我们也发布了 MLIR,这是一个开源的机器学习算法编译器,作为一个基础设施,它的设计目标是缓解软件、硬件日趋明显的碎片化现象,让AI应用的构建更容易。
这也是高性能机器学习研究工具 JAX 发布后的第一年。就在NeurIPS 2019上,我们和更多的开源社区成员们展示了从 NTK 神经正切核到贝叶斯推理到分子动力学等等各种各样的使用JAX开发的模型,我们也发布了云TPU上运行的JAX的预览版。
我们也开源了用来构建多模态感知机器学习应用流水线的框架设计工具MediaPipe,和含有各种高效的浮点神经网络推理操作符的库 XNNPACK。截止2019年底,我们已经通过TensorFlow Research Cloud赞助了超过1500名研究人员免费使用云TPU。我们的TensorFlow入门Coursera课程也迎来了超过10万名学生。我们在11个不同国家举办了TensorFlow推广活动,借机接触了上千名用户;我们还举办了首个TensorFlow世界大会。
在TF的帮助下,全世界各种各样背景的人也做出了各种各样的成果,2019年里有一位大学本科生发现了两个新的行星,他也开源了这个模型,让更多的人可以用这个方法发现更多的行星;一位尼日利亚裔的数据科学家训练了一个GAN来生成代表了非洲面具风格的图像;乌干达的一位开发者用TF编写了Farmers Companion app,帮助当地农民对付一种伤害庄稼的毛毛虫。
在白雪覆盖的爱荷华州,研究人员们和政府部门联手用TF编写了根据车流行为、视觉数据以及其它数据判断道路安全状况的程序;在晴朗干燥的加州,大学生们也用TF来发现洛杉矶一带的路面凹坑和危险碎石。
具有明确和可测量目标的开放数据集,往往对推动机器学习领域的发展非常有帮助。为了帮助研究界找到有趣的数据集,我们继续通过使用Google Dataset Search索引了来自多个不同组织发布的各种公开的数据集。
我们还认为很重要的是,要为社区创建新的数据集用以探索和开发新的技术,并确保能够有责地共享公开的数据集。这一年,我们先后新发布了涵盖多个不同领域的数个公开数据集:
Open Images V5:这是常用的Open Images数据集的更新版本,包括面向 350 个类中的280万个对象的分割掩膜(所以现在该数据集拥有图片级标签、对象边框、对象分割掩膜和视觉关系标注的 900 万张图像)。
Natural questions:这是首个使用自然发出的查询,并通过读取整个篇章找到答案而非从短段落中提取答案的数据集。
Data for deepfake detection:我们为 FaceForensics 基准贡献了视觉 deepfakes 的大型数据集(如上文所提到的)。
Google Research Football: 这是一个新颖的强化学习环境,在此环境中,智能体的目标就是掌握世界上最热门的运动——足球。强化学习智能体要实现其目标,实现足球射门的目标很重要!
Google-Landmarks-v2:该数据集拥有超过 200万个不同路标的超过500万张图片(是发布的首个版本的两倍)。
YouTube-8M Segments:这是一个分类和实时间定位的大型数据集,拥有 YouTube-8M视频的5秒分割级的人工验证标签。
Atomic Visual Actions (AVA) Spoken Activity:这是一个用于对话感知的音频+视觉的多模态数据集。此外,我们还面向 AVA 动作识别和 AVA: Spoken Activity 数据集举办了一些学术挑战赛。
PAWS and PAWS-X:为了推动复述识别的进步,这两个数据集都包括了具有高词汇重叠的格式正确的句对,复述约一半的句对,而另一半则不复述。
Natural language dialog datasets:CCPE 和 Taskmaster-1都使用让两个人一组进行口语对话的 Wizard-of-Oz平台,来最小化数字助理的对话水平和人类的差距。
The Visual Task Adaptation Benchmark:VTAB这一基准遵循和ImageNet和 GLUE相同的准则,但是它基于的一个原则是:在域内数据的限制下,未见过任务上更好的性能优先于更好的表征。
Schema-Guided Dialogue Dataset:这是最大的面向任务的对话公开语料库,拥有横跨17个领域的18000多组对话。
2019年,我们也活跃于更广阔的学术界和研究界。这一年,谷歌研究人员发表了数百篇论文,参加了多场学术会议,并获得了许多奖项和其他荣誉:
-
在CVPR 上,谷歌研究者展示了40余篇论文、演讲、海报并举办了研讨会以及其他活动。
-
在 ICML上,谷歌研究者展示了100余篇论文、演讲、海报并举办了研讨会以及其他活动。
-
在ICLR 上,谷歌研究者展示了60余篇论文、演讲、海报并举办了研讨会以及其他活动。
-
在ACL 上,谷歌研究者展示了40余篇论文,举办了研讨会以及教学讲座。
-
在Interspeech 上,上百位谷歌研究者在现场一起展示了30余篇论文。
-
在ICCV 上,200多位谷歌研究者在现场一起展示了40余篇论文,更有数位谷歌研究人员拿下 ICCV 三个奖项。
-
在NeurIPS上,500多位谷歌研究人员合作发表了超过 120 篇论文,并在现场参加了各类研讨会和其他活动。
我们还召集了来自全球各地的数百名谷歌研究人员和教职员工,参加了在谷歌办公室举办的15个独立的研究研讨会。这些研讨会的主题涵盖了从改善全球洪灾预警,到如何使用机器学习建立能更好地为残疾人服务的系统,到加速开发用于有噪声的中等规模量子(NISQ)处理器的算法、应用程序和工具。
为了支持谷歌以外的学术界和研究界,我们通过“年度博士奖学金计划”在全球范围内支持了50多名博士生,与此同时,我们还成立了158个项目基金作为“2018年谷歌职工研究奖”的一部分,并举办了第三届“ Google AI Residency Program”,还为人工智能初创企业提供了指导帮助。
过去的十年见证了机器学习和计算机科学领域的长足发展,我们现在已经让计算机有了比以前更好的看、听和理解语言的能力(更多详细可参考《The Decade of Deep Learning》一文,
https://leogao.dev/2019/12/31/The-Decade-of-Deep-Learning/
现在我们拥有了唾手可得的先进的计算设备,从而可以利用这些能力更好地帮助我们完成日常生活中的许多任务。我们通过开发出专门的硬件,已经围绕这些机器学习方法从根本上重新设计了现有的计算平台,从而使我们能够解决更大的问题。
这改变了我们对于既存在于数据中心、同时也搭载于低功耗移动环境中的计算设备的看法(前者如以推理为中心的TPUv1和以训练和推理为中心的TPUv2和TPUv3,后者如边缘 TPU)。
与此同时,现在也还有许多我们尚且无法回答的问题以及尚未解决的挑战。以下是我们在 2020年及以后要解决的一些问题以及感到兴奋的一些研究方向:
第一,如何建立能够处理数百万任务并且能够主动学习顺利完成新任务的机器学习系统?
目前,我们基本上都需要为每个新任务训练单独的机器模型,从头开始或者顶多基于为一个或几个高度相关的任务训练的模型开始。因此,我们训练的模型虽然确实擅长某个任务或者某几个任务,但并不擅长其他任务。
然而,我们真正想要训练的模型,是那些善于利用它们的专业知识来完成很多任务的模型,这样这些模型就能够学会用相对较少的训练数据和计算,来完成一个新的任务。
这是一个真正的巨大挑战,需要具备横跨包括固态电路设计、计算机体系结构、以ML为中心的编译器、分布式系统、机器学习算法在内的多个领域的专业知识和进展以及其他多个领域的领域专家,来开发出具备能够独立解决整个应用领域中的新任务的泛化能力的系统。
第二,如何推动如避免偏见、增加可解释性和可理解性、改善隐私和确保安全等当前非常重要的 AI 研究领域的进步?随着我们人类在社会上越来越多地使用机器学习,这些领域的进步将是至关重要的。
第三,如何应用计算和机器学习来促进重要的新科学领域的进展?AI 领域通过与例如气候科学、医疗健康、生物信息学和许多其他领域的专家进行精诚合作,可以获得一些重要进展。
第四,如何才能确保机器学习和计算机科学研究界所追求的理念和方向,是由多种多样的研究人员共同提出和探索的?
计算机科学和机器学习研究界正在从事的工作,对数十亿人都有着广泛的影响,我们希望从事 AI 领域的研究人员能够代表世界上所有人的经历、观点、关注点和创造热情。
那我们如何才能最好地支持来自不同背景的新研究人员进入该领域呢?
总而言之,2019年对于谷歌和整个研究界而言,是研究工作取得巨大进展的令人兴奋的一年。我们很高兴将在 2020 年以及以后继续迎接这些研究挑战,也期待能够与大家分享我们后续的研究进展。
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上交大] 基于图像查询的视频检索,代码已开源!
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页


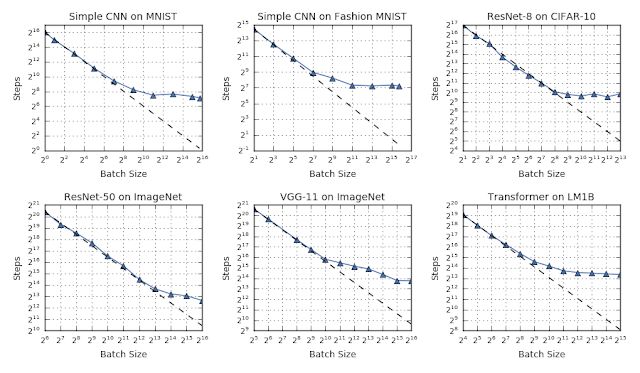 与将数据分布在多个计算设备中的数据并行性相比,模型并行性也是扩展模型的一种有效方法。
GPipe是一个通过类似于流水线CPU处理器所使用的方法的库,它可以使模型并行化更加有效:
当整个模型的一部分正在处理某些数据时,其他部分可以并行计算不同的数据。
这种流水线的结果可以组合在一起,从而来模拟更大的有效批次大小。
与将数据分布在多个计算设备中的数据并行性相比,模型并行性也是扩展模型的一种有效方法。
GPipe是一个通过类似于流水线CPU处理器所使用的方法的库,它可以使模型并行化更加有效:
当整个模型的一部分正在处理某些数据时,其他部分可以并行计算不同的数据。
这种流水线的结果可以组合在一起,从而来模拟更大的有效批次大小。