机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括谷歌提出的扩展型 BERT 架构 Tapas,以及 GCN 作者的博士论文。
SYNTHESIZER: Rethinking Self-Attention in Transformer Models
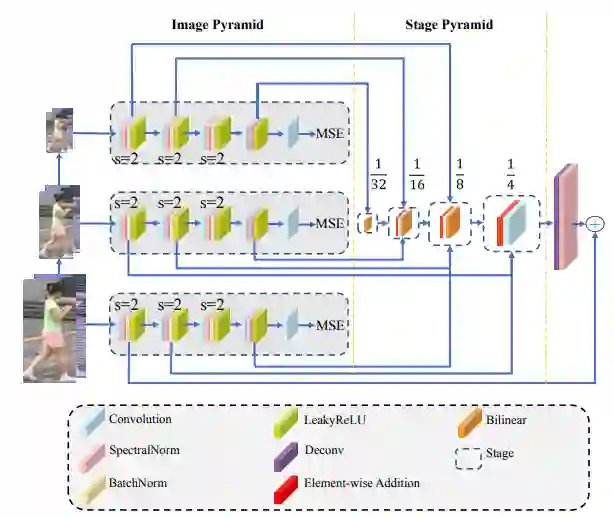
Interactive Video Stylization Using Few-Shot Patch-Based Training
Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person Re-identification With Deep Mis-Ranking
How to Train Your Energy-Based Model for Regression
TAPAS: Weakly Supervised Table Parsing via Pre-training
memeBot: Towards Automatic Image Meme Generation
Deep Learning with Graph-Structured Representations
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)
论文 1:SYNTHESIZER: Rethinking Self-Attention in Transformer Models
摘要:
众所周知,点积自注意力(dot product self-attention)对于 SOTA Transformer 模型是至关重要且不可或缺的。但有一个疑问,点积自注意力真的这么重要吗?
在本文中,来自谷歌研究院的几位作者研究了点积自注意力机制对于 Transformer 模型性能的真正重要点和贡献。通过一系列实验,研究者发现(1)随机对齐矩阵(random alignment matrice)的执行效果出人意料地好;(2)从 token-token(查询 - 键)交互中学习注意力权重并不是那么重要。基于此,研究者提出了 Synthesizer,这是一个无需 token-token 交互即可学习合成注意力权重的模型。
![]()
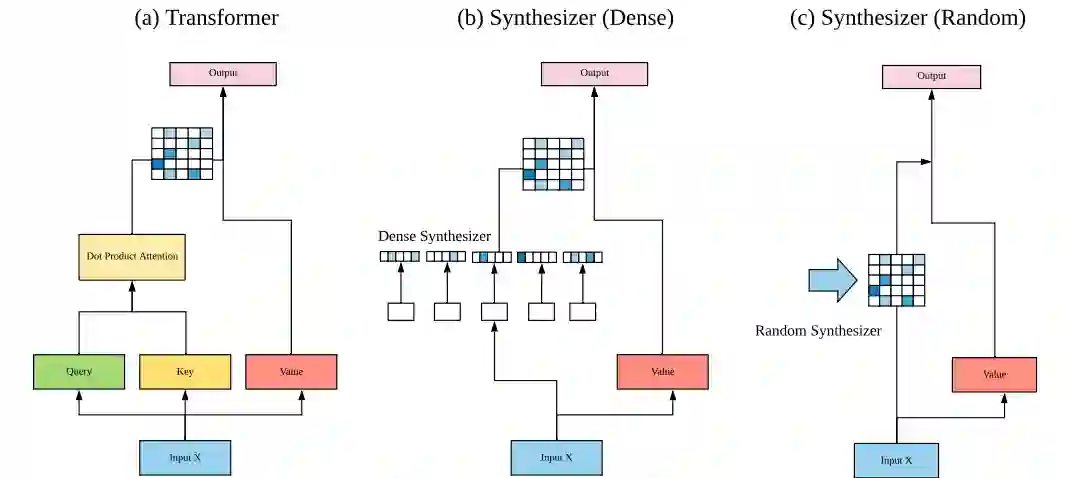
本研究提出的 Synthesizer 模型架构图。
![]()
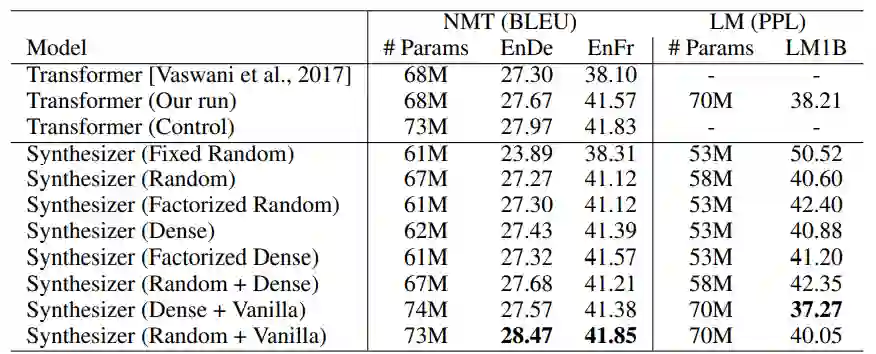
在 WMT’14 英语 - 德语、WMT’14 英语 - 法语机器翻译任务以及 10 亿语言建模(LM1B)任务上的 NMT 和 LM 效果对比。
![]()
在摘要式归纳(CNN / 每日邮报)和对话生成(PersonalChat)任务上归纳和对话效果对比。
推荐:
本研究提出的 Synthesizer 在 MT、语言建模、摘要式归纳、对话生成以及多任务语言理解等一系列任务上的性能
均媲美于最原始的(vanilla)Transformer 模
型。
论文 2:Interactive Video Stylization Using Few-Shot Patch-Based Training
摘要:
在本文中,
捷克理工大学和 Snap 公司的研究者提出了一种用于关键帧视频风格化的学习方法,借助这种学习方法,艺术家可以将风格从少数选定的关键帧迁移至序列其他部分
。这种学习方法的主要优势在于最终的风格化在语义上有意义,也就是说,运动目标(moving object)的特定部分根据艺术家的意图进行风格化处理。
与以往的风格迁移方法相比,本研究提出的学习方法既不需要任何冗长的预训练过程,也不需要大型训练数据集。研究者展示了在仅使用少数风格化范例且隐式保持时序一致性的情况下,如何从零开始训练外观转换网络。由此得出的视频风格化框架支持实时推理、并行处理以及任意输出帧的随机访问。
此外,这种学习方法还可以合并多个关键帧中的内容,同时不需要执行显式混合操作。研究者验证了这种学习方法在各种交互场景中的实用性,在这些场景中,用户在选定关键帧中绘画,并且绘画风格可以迁移至已有的记录序列或实时视频流中。
![]()
![]()
![]()
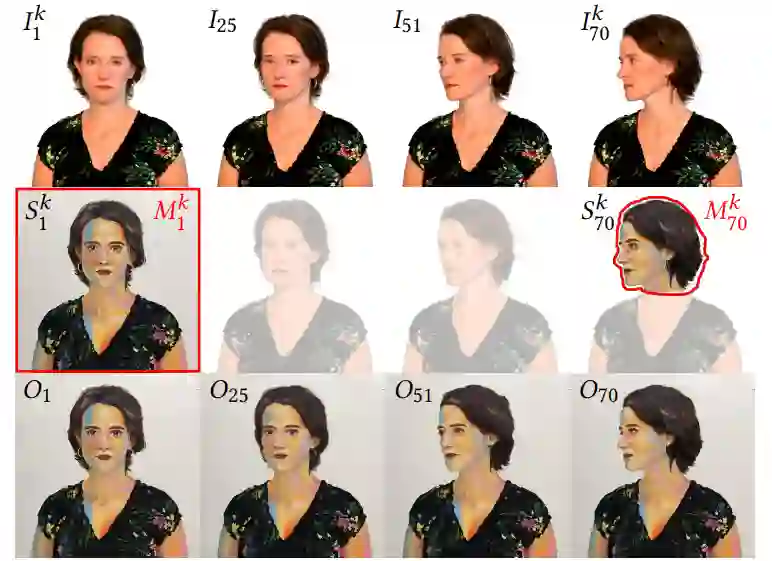
完整帧训练方法与本研究中少样本 Patch 训练方法的效果比较。
推荐:
本研究中少样本 Patch 训练方法的亮点在于它可以
在与帧无关的模式下运行
,这对当前严重依赖随机访问和并行处理的专业视频编辑工具非常有利。
论文 3:Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person Re-identification With Deep Mis-Ranking
摘要:
在本文中,来自
中山大学、广州大学和暗物智能科技的研究者们通过提出以一种学习误排序的模型来扰乱系统输出的排序,从而检验当前性能最佳的 re-ID 模型的不安全性
。
由于跨数据集的可迁移性在 re-ID 域中至关重要,因此作者还通过构建新颖的多级网络体系结构进行半黑盒式攻击,该体系结构将不同级别的特征金字塔化,以提取对抗性扰动的一般和可迁移特征。该体系可以通过使用可微分的采样来控制待攻击像素的数量。为了保证攻击的不显眼性,研究者还提出了一种新的感知损失,以实现更好的视觉质量。
在四个最大的 re-ID 基准数据集(即 Market1501、CUHK03、DukeMTMC 和 MSMT17)上进行的广泛实验不仅显示了该方法的有效性,而且还为 re-ID 系统的鲁棒性提供了未来改进的方向。
![]()
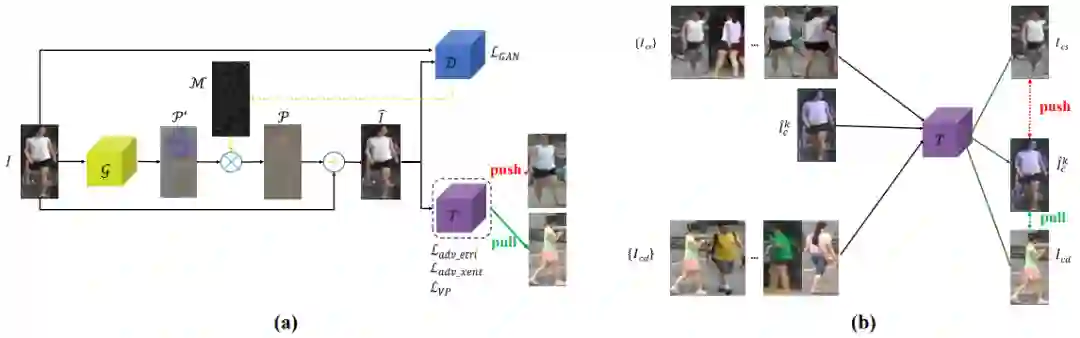
Market-1501 和 CUHK03 上 AlignedReID 被攻击前后的 Rank-10 结果。绿色代表正确匹配。红色代表错误匹配。
![]()
![]()
推荐:
本文的亮点在于将将 SOTA 行人再识别系统精度降至 1.4%,并已被 CVPR 大会接收为 Oral 论文。
论文 4:How to Train Your Energy-Based Model for Regression
摘要:
近年来,基于能量的模型(Energy-based Model,EBM)在计算机视觉领域越来越流行。虽然这些模型通常用于生成图像建模,但最近的研究已经将 EMB 应用于回归任务(Regression Task),并在目标检测和视觉跟踪领域实现 SOTA。但是训练 EBM 不是一件简单的事情。另外,生成式建模(Generative Modeling)可以利用多种多样的方法,但将 EBM 应用于回归任务没有获得充分的研究。因此,如何训练 EBM 实现最佳的回归性能目前尚不清楚。
在本文中,来自
瑞典乌普萨拉大学和苏黎世联邦理工学院的研究者对这些问题展开了详实研究,提出了一种噪声对比估计(Noise Contrastive Estimation, NCE)的简单高效扩展,并与 1D 回归和目标检测任务上的 6 种流行方法进行了性能对比
。对比结果表明,本研究提出的训练方法应被认为实最佳。研究者还将他们的方法应用到视觉跟踪任务上,在 5 个数据集上实现新的 SOTA。
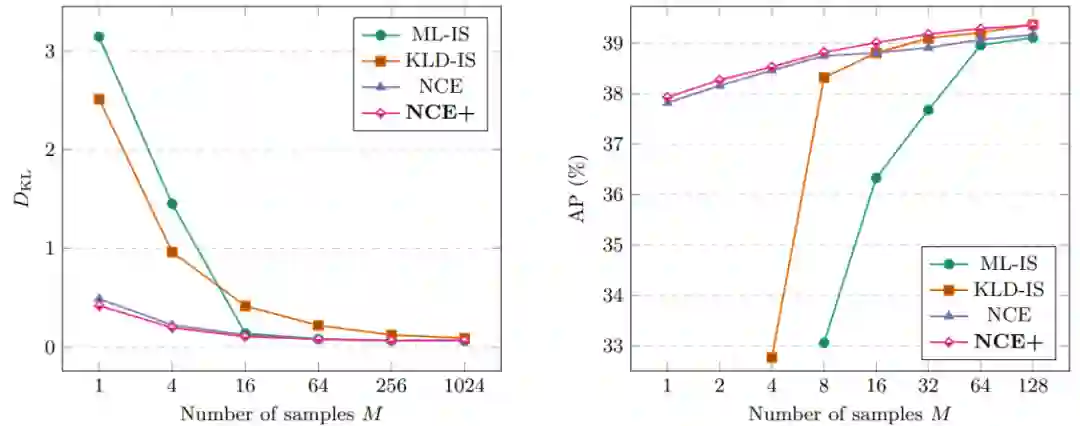
![]()
对于边界框回归等任务,本研究提出以噪声对比估计的简单高效扩展(文中表示为 NCE+)来训练基于能量的模型(EBM)。
![]()
1D 回归实验训练方法的 D_KL 和训练成本对比。
![]()
图左:用于 1D 回归实验的四种表现最佳方法的详细比较;图右:COCO-2017 Val 数据集上,用于目标检测实验的四种表现最佳方法的详细比较。四种方法均分别为 ML-IS、KLD-IS、NCE 和本研究提出的 NCE+。
推荐:
本研究中的跟踪器
在 LaSOT 目标跟踪数据集上实现了 63.7% 的 AUC,在 TrackingNet 目标跟踪数据集上实现了 78.7% 的 Success
。
论文 5:TAPAS: Weakly Supervised Table Parsing via Pre-training
摘要:
谷歌在本文中提出了一种
扩展型的 BERT 架构
。该架构可对问题与表格数据结构进行联合编码,最终得到的模型可直接指向问题答案。并且,这种新方法所创建的模型适用于多个领域的表格。
要想得到优良的模型,优质的数据自然是不可或缺的。谷歌首先使用了数百万个维基百科表格对模型进行预训练,然后又在三个学术级表格问答数据集上进行实验,结果表明新方法的准确度表现极具竞争力。不仅如此,谷歌开源了模型训练和测试代码,还公开分享了他们在维基百科数据上得到的预训练模型。
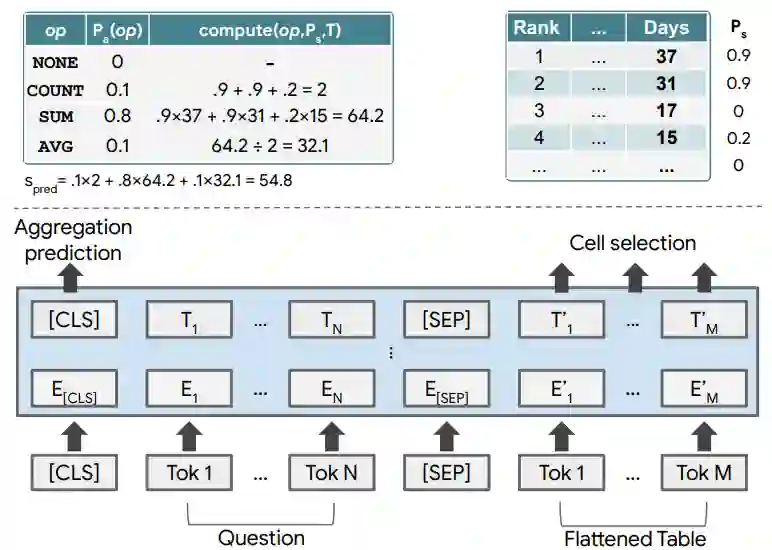
![]()
本研究提出的 Tapas 模型以及对于问题 “排名前二的总天数(total number of days for the top two)” 的示例模型输出。
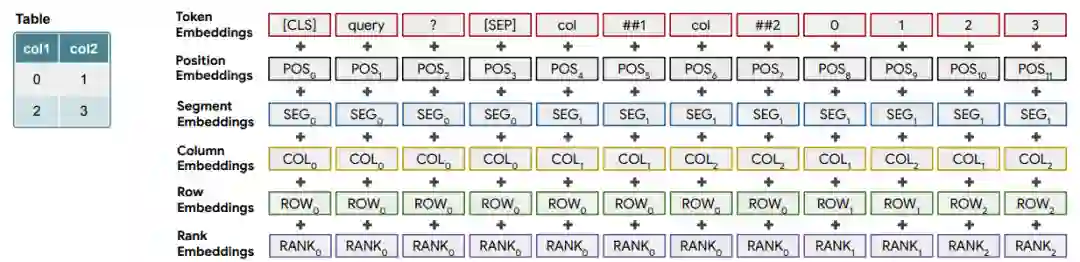
![]()
问题 “查询(query)” 的编码以及使用 Tapas 特定嵌入的简单表格。
![]()
表格(左)与对应的问题示例(右)。问题 5 是会话式。
推荐:
谷歌的这篇论文将 BERT 模型应用到了基于表格的问答场景中,为弱监督式的表格解析性能带来了显著提升。
论文 6:memeBot: Towards Automatic Image Meme Generation
摘要:
近日,来自
美国亚利桑那州立大学的研究者对 meme 图生成方法进行了改进提升
。在这篇论文中,研究者提出了一种根据给定的输入语句来生成匹配图片的方法。这是一项很有挑战性但有趣的 NLP 任务。通过对 meme 图生成机制的深入了解,研究者决定将 meme 图生成与自然语言翻译相结合。
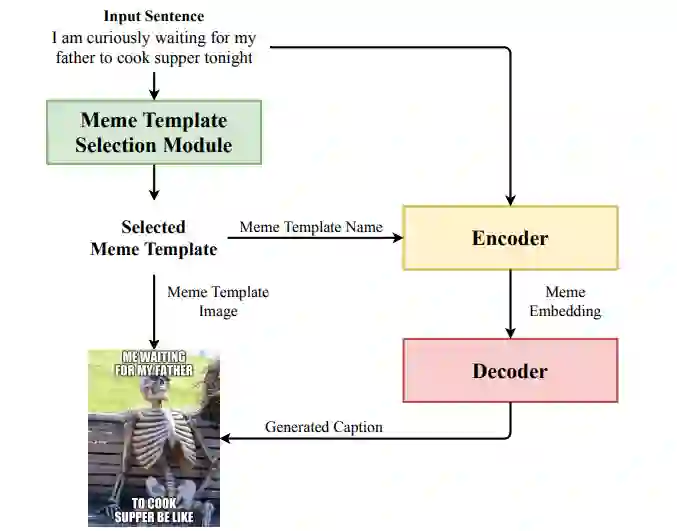
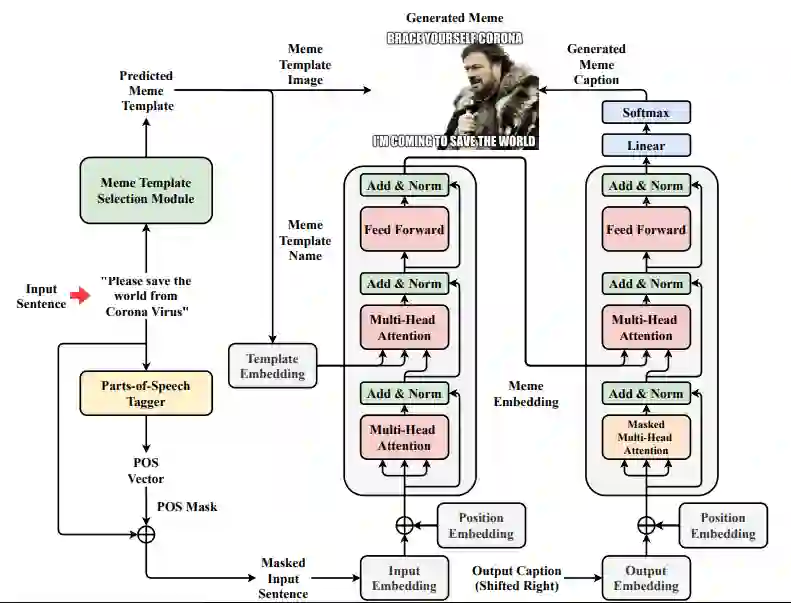
在自然语言翻译工作中,为了将输入的语句转换为目标语言,必须对语句的完整含义进行解码,分析其含义,然后将源语句的含义编码为目标语句。类似地,此处也可以通过将源语句的含义编码为一对图像和标题,传达与源语句相同的含义或情感,从而将语句翻译成「梗」。受到这种方法的启发,研究者提出了一种端到端的编码 - 解码模型「memeBot」,面向任意给定的语句来生成 meme 图。同时在训练的过程中,他们制作出了首个大型 meme 图字幕数据集。
![]()
![]()
memeBot 模型架构图。对于给定输入序列,通过结合模板选择模块(template selection module)选择的和标签生成 transformer(caption generation transformer)生成的表情包标签来创建新的表情包。
![]()
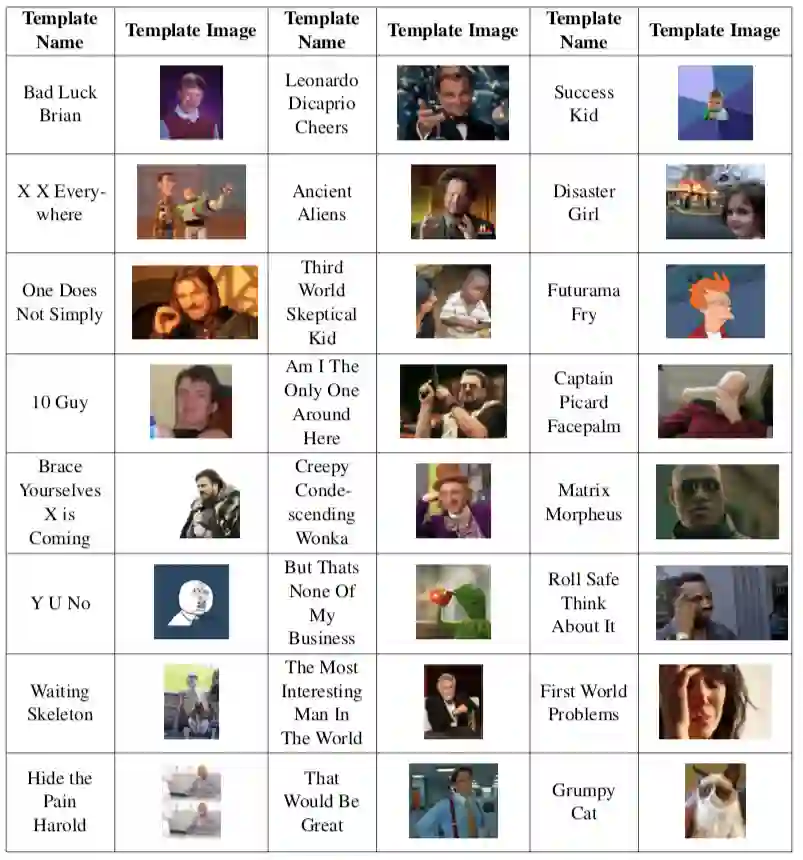
附录 A:实验中所用 meme 字幕数据集包括的模版和图像。
推荐:
在制作沙雕表情包这件事上,AI也略胜一筹。
论文 7:Deep Learning with Graph-Structured Representations
摘要:
近日,
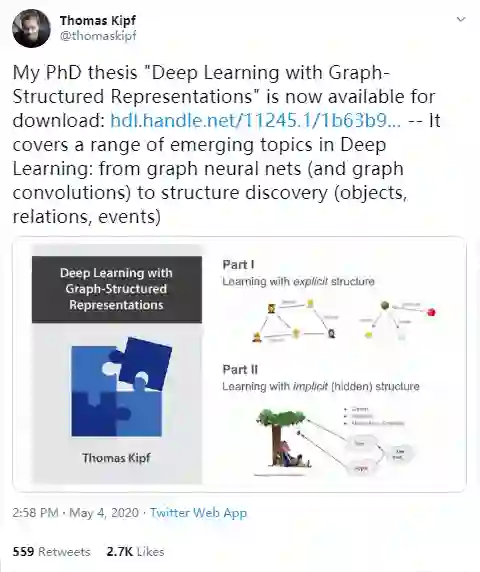
GoogleAI 大脑团队研究科学家、GCN 作者、阿姆斯特丹大学机器学习博士生 Thomas Kipf 宣布其博士论文《深度学习图结构表征》(Deep Learning with Graph-Structured Representations)可以下载了
。在论文中,作者提出了利用结构化数据进行机器学习的新方法,这些方法主要基于结构化表示以及图表示的神经网络模型计算,由此当从具有显式和隐式模块结构的数据学习时可以提升泛化性能。
![]()
GCN 作者 Thomas Kipf 宣布公开其博士论文(178 页)。
![]()
推荐:这篇博士论文
涵盖了深度学习领域的一系列新兴主题
,如图卷积网络和结构发现等。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. A Survey on Dialog Management: Recent Advances and Challenges. (from Yinpei Dai, Huihua Yu, Yixuan Jiang, Chengguang Tang, Yongbin Li, Jian Sun)
2. Topological Sort for Sentence Ordering. (from Shrimai Prabhumoye, Ruslan Salakhutdinov, Alan W Black)
3. Exploring Controllable Text Generation Techniques. (from Shrimai Prabhumoye, Alan W Black, Ruslan Salakhutdinov)
4. CODA-19: Reliably Annotating Research Aspects on 10,000+ CORD-19 Abstracts Using Non-Expert Crowd. (from Ting-Hao 'Kenneth' Huang, Chieh-Yang Huang, Chien-Kuang Cornelia Ding, Yen-Chia Hsu, C. Lee Giles)
5. AdapterFusion: Non-Destructive Task Composition for Transfer Learning. (from Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, Iryna Gurevych)
6. Extracting Headless MWEs from Dependency Parse Trees: Parsing, Tagging, and Joint Modeling Approaches. (from Tianze Shi, Lillian Lee)
7. Soft Gazetteers for Low-Resource Named Entity Recognition. (from Shruti Rijhwani, Shuyan Zhou, Graham Neubig, Jaime Carbonell)
8. Cross-lingual Entity Alignment for Knowledge Graphs with Incidental Supervision from Free Text. (from Muhao Chen, Weijia Shi, Ben Zhou, Dan Roth)
9. TORQUE: A Reading Comprehension Dataset of Temporal Ordering Questions. (from Qiang Ning, Hao Wu, Rujun Han, Nanyun Peng, Matt Gardner, Dan Roth)
10. Structured Tuning for Semantic Role Labeling. (from Tao Li, Parth Anand Jawale, Martha Palmer, Vivek Srikumar)
1. The AVA-Kinetics Localized Human Actions Video Dataset. (from Ang Li, Meghana Thotakuri, David A. Ross, João Carreira, Alexander Vostrikov, Andrew Zisserman)
2. Adversarial Training against Location-Optimized Adversarial Patches. (from Sukrut Rao, David Stutz, Bernt Schiele)
3. Streaming Object Detection for 3-D Point Clouds. (from Wei Han, Zhengdong Zhang, Benjamin Caine, Brandon Yang, Christoph Sprunk, Ouais Alsharif, Jiquan Ngiam, Vijay Vasudevan, Jonathon Shlens, Zhifeng Chen)
4. StereoGAN: Bridging Synthetic-to-Real Domain Gap by Joint Optimization of Domain Translation and Stereo Matching. (from Rui Liu, Chengxi Yang, Wenxiu Sun, Xiaogang Wang, Hongsheng Li)
5. Dual-Sampling Attention Network for Diagnosis of COVID-19 from Community Acquired Pneumonia. (from Xi Ouyang, Jiayu Huo, Liming Xia, Fei Shan, Jun Liu, Zhanhao Mo, Fuhua Yan, Zhongxiang Ding, Qi Yang, Bin Song, Feng Shi, Huan Yuan, Ying Wei, Xiaohuan Cao, Yaozong Gao, Dijia Wu, Qian Wang, Dinggang Shen)
6. CONFIG: Controllable Neural Face Image Generation. (from Marek Kowalski, Stephan J. Garbin, Virginia Estellers, Tadas Baltrušaitis, Matthew Johnson, Jamie Shotton)
7. Self-Supervised Human Depth Estimation from Monocular Videos. (from Feitong Tan, Hao Zhu, Zhaopeng Cui, Siyu Zhu, Marc Pollefeys, Ping Tan)
8. Occlusion resistant learning of intuitive physics from videos. (from Ronan Riochet, Josef Sivic, Ivan Laptev, Emmanuel Dupoux)
9. Multi-Head Attention with Joint Agent-Map Representation for Trajectory Prediction in Autonomous Driving. (from Kaouther Messaoud, Nachiket Deo, Mohan M. Trivedi, Fawzi Nashashibi)
10. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. (from Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo)
1. Partially-Typed NER Datasets Integration: Connecting Practice to Theory. (from Shi Zhi, Liyuan Liu, Yu Zhang, Shiyin Wang, Qi Li, Chao Zhang, Jiawei Han)
2. Time Dependence in Non-Autonomous Neural ODEs. (from Jared Quincy Davis, Krzysztof Choromanski, Jake Varley, Honglak Lee, Jean-Jacques Slotine, Valerii Likhosterov, Adrian Weller, Ameesh Makadia, Vikas Sindhwani)
3. Successfully Applying the Stabilized Lottery Ticket Hypothesis to the Transformer Architecture. (from Christopher Brix, Parnia Bahar, Hermann Ney)
4. Interpreting Rate-Distortion of Variational Autoencoder and Using Model Uncertainty for Anomaly Detection. (from Seonho Park, George Adosoglou, Panos M. Pardalos)
5. Physics-informed neural network for ultrasound nondestructive quantification of surface breaking cracks. (from Khemraj Shukla, Patricio Clark Di Leoni, James Blackshire, Daniel Sparkman, George Em Karniadakiss)
6. Bullseye Polytope: A Scalable Clean-Label Poisoning Attack with Improved Transferability. (from Hojjat Aghakhani, Dongyu Meng, Yu-Xiang Wang, Christopher Kruegel, Giovanni Vigna)
7. Plan2Vec: Unsupervised Representation Learning by Latent Plans. (from Ge Yang, Amy Zhang, Ari S. Morcos, Joelle Pineau, Pieter Abbeel, Roberto Calandra)
8. Demand-Side Scheduling Based on Deep Actor-Critic Learning for Smart Grids. (from Joash Lee, Wenbo Wang, Dusit Niyato)
9. APo-VAE: Text Generation in Hyperbolic Space. (from Shuyang Dai, Zhe Gan, Yu Cheng, Chenyang Tao, Lawrence Carin, Jingjing Liu)
10. EDD: Efficient Differentiable DNN Architecture and Implementation Co-search for Embedded AI Solutions. (from Yuhong Li, Cong Hao, Xiaofan Zhang, Xinheng Liu, Yao Chen, Jinjun Xiong, Wen-mei Hwu, Deming Chen)
![]()