谷歌开源强化学习框架 Dopamine
强化学习是一种AI技术,使用奖励(或惩罚)机制来驱动代理(agent)实现特定的目标。经过强化学习训练的系统击败了Alpha Go世界冠军,并在Valve开发的热门游戏《刀塔2》(Dota 2)中击败了人类。强化学习还是谷歌子公司DeepMind的深度Q网络(DQN)的核心组成部分,深度Q网络可以在多个worker节点当中分配学习任务,以实现某个具体的目标,比如说在Atari 2600游戏中获得“超人类”性能。可问题在于,强化学习框架需要时间才能达成目标,往往缺乏灵活性,而且并不总是很稳定。
这就是为什么现在谷歌提出了一种替代方案:基于其机器学习库TensorFlow的开源强化学习框架。从今天开始,该框架可以从Github获得(https://github.com/google/dopamine/tree/master/docs#downloads)。
谷歌Brain团队的两名研究人员巴勃罗•塞缪尔•卡斯特罗(Pablo Samuel Castro)和马克•G•贝勒马尔(Marc G. Bellemare)在一篇博文中写道:“该平台受到大脑中奖赏激励行为的主要部分之一的启发,体现了神经科学与强化学习研究之间紧密的历史联系,旨在能够实现有望带来重大发现的那种纯理论研究。这次发布的内容还包括一组阐明如何使用我们框架的colab,colab是谷歌用于数据科学的一种内部研究工具。”
他们和谷歌Brain团队开发了强化学习框架,恪守三大原则:灵活性、稳定性和重现性。
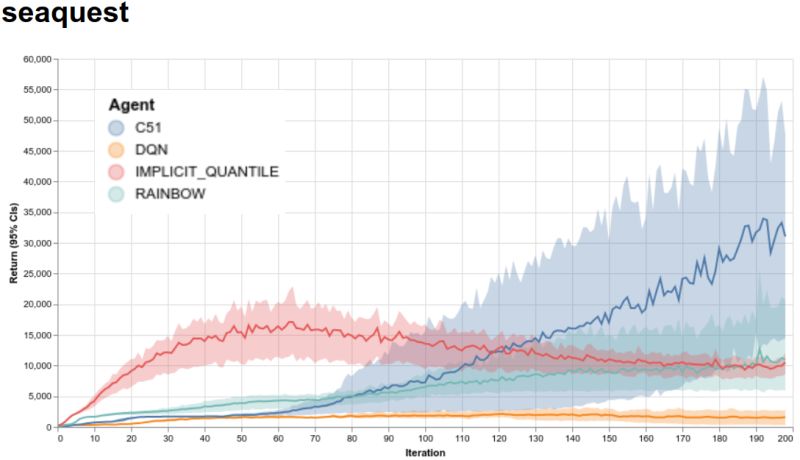
该图直观地显示了使用强化学习训练的AI代理(图片来源:谷歌)
为此,它包含一套紧凑的文档完备的代码(15个Python文件),专注于Arcade Learning Environment(街机学习环境)――这个平台用于用视频游戏来评估AI技术,还包含四种不同的机器学习模型:上述的DQN、C51、简化版本的Rainbow代理以及隐式分位数网络(Implicit Quantile Network)。为了确保重现性,除了代码外还附有面向街机学习环境支持的60款游戏的完整测试覆盖范围和训练数据(采用JSON和Python pickle格式),并遵循结果实现标准化以用于经验评估方面的最佳实践。
除了发布增强学习框架外,谷歌还推出了一个网站,允许广大开发人员迅速直观地显示多个代理的训练运行。谷歌还提供经过训练的模型、原始统计日志和TensorFlow事件文件,以便用TensorBoard来绘图,而TensorBoard是这家总部位于芒廷维尤的公司为TensorFlow程序开发的可视化工具套件。
贝勒马尔和卡斯特罗写道:“我们希望,我们的框架具有的灵活性和易用性将造福广大研究人员,便于他们尝试新的想法,包括渐进和激进的新想法。我们已经积极地将它用于我们的研究,发现它让我们能够灵活地快速迭代许多想法。我们很高兴看到更广大的社区能够从中得益。”



