浅谈微信AI在通用图像搜索领域的探索


文章作者:lincolnlin
内容来源:微信AI
导语
微信识物

首先我们会对query的图片做目标检测,去除背景干扰。
然后以图像主体进行检索,拿到图像召回的列表。
最后一步是进行信息提炼,得到商品的标题,品牌,主体,主图等。

微信图像搜索
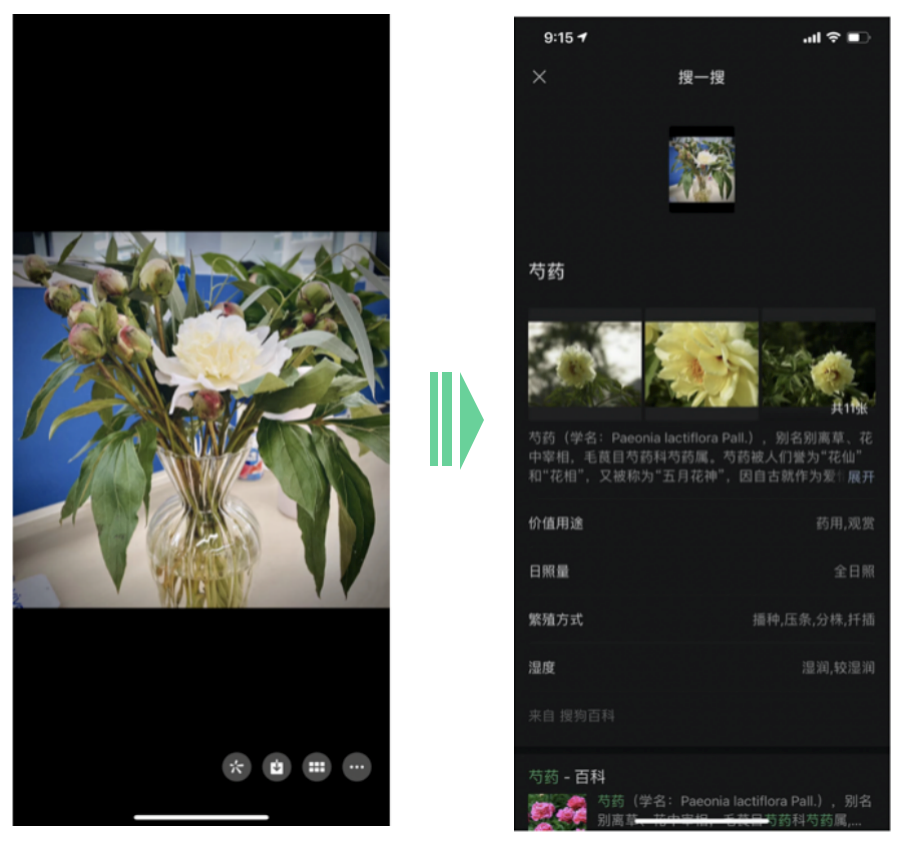
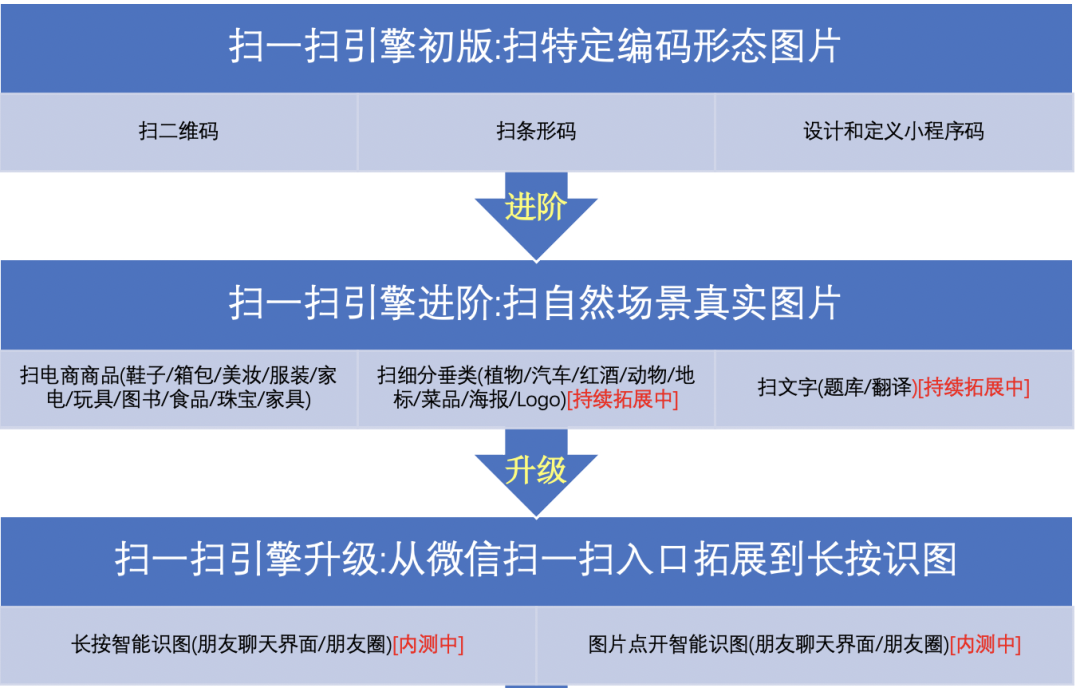
识物搜索的现状
微信识图
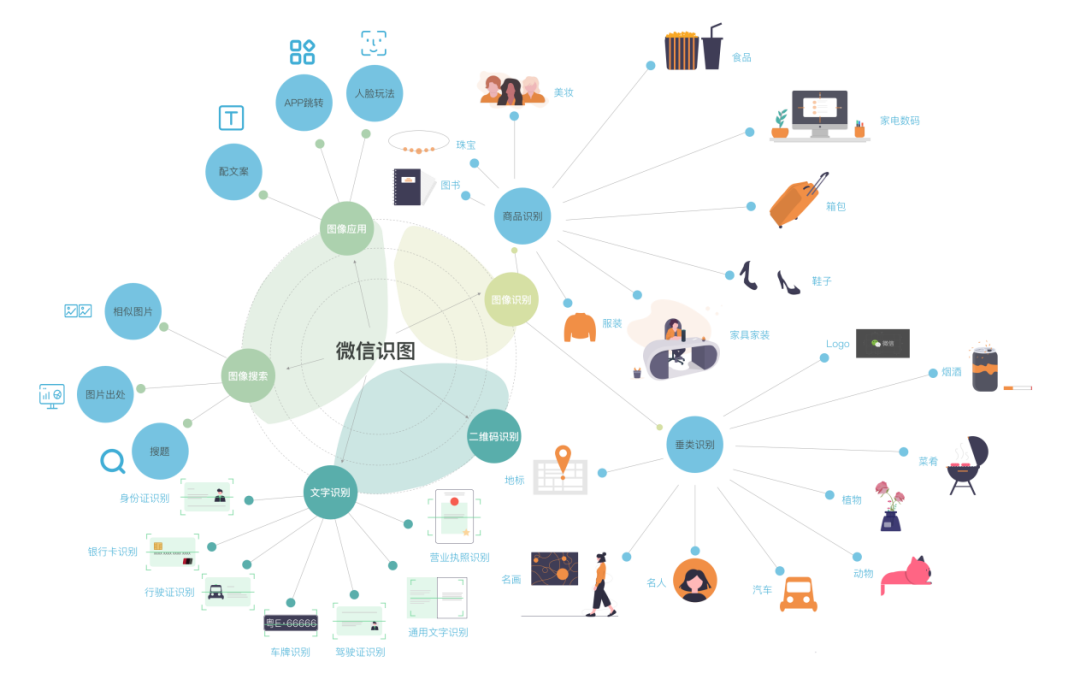
微信图像识别的入口,拓展各类识别能力,包含图像识别、图像搜索、二维码识别、文字提取,以及各种图像的应用及玩法。
接下来,我会介绍一下识图的一些具体应用场景。
商品识别
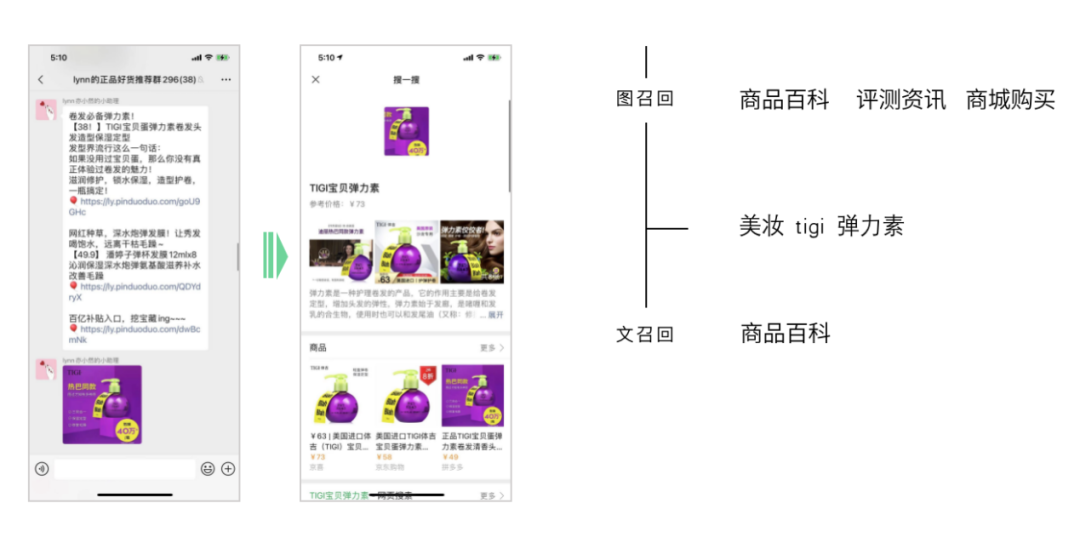
细分类识别
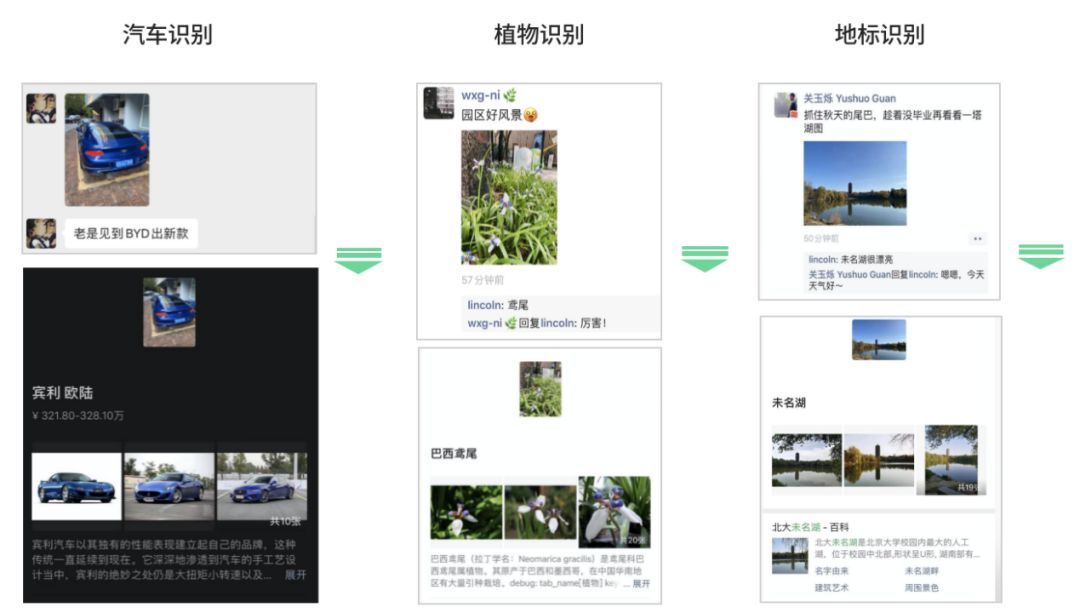
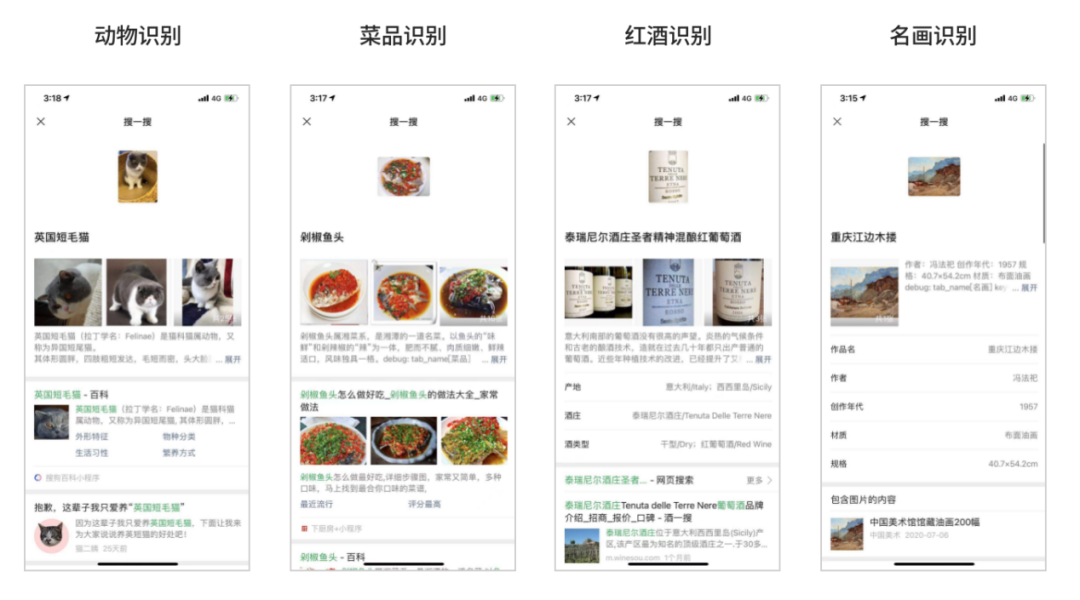
以图搜图的拓展

以图搜图的系统实现
分类篇 | 图片内容标签体系
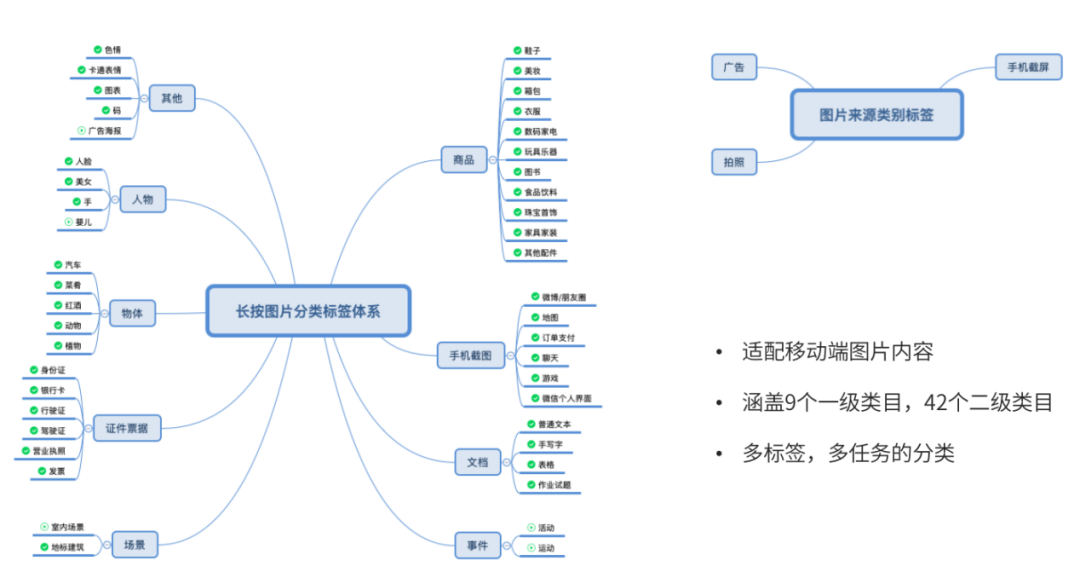
分类篇 | 多标签分类

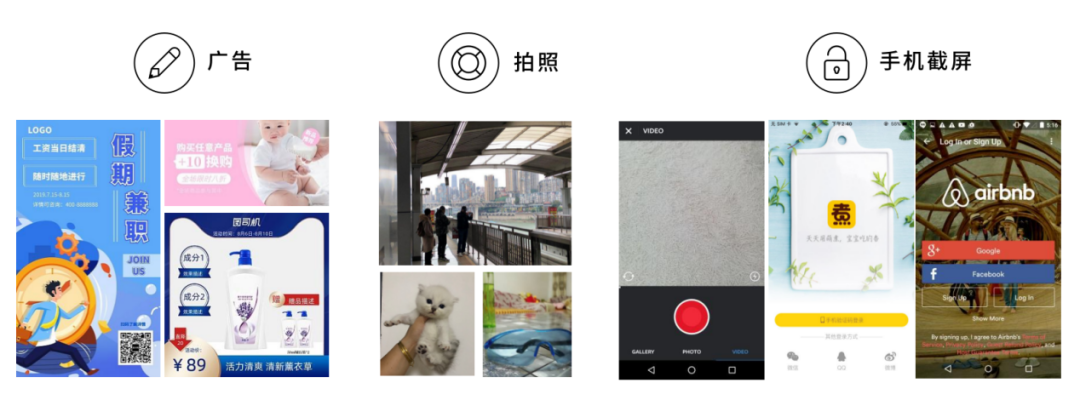
分类篇 | 细分类的应用
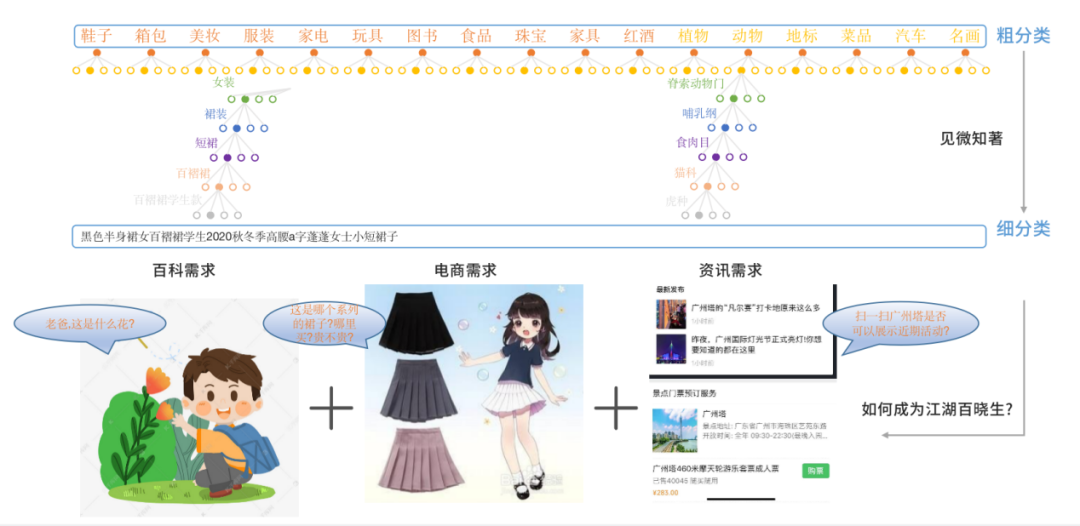
电商场景:我们要识别的集合是无限大的,而且还是动态的。所以我们是通过动态图像召回。从召回的结果上推断出商品的具体款式。
动植物汽车这种场景:集合是相对固定的。而且需要一些专业的数据库。我们采用分类+检索的方法,在具体的处理逻辑上,也依据具体的场景不同而不同。目前我们支持了动物/植物/菜品/地标/汽车/名画/红酒识别。
检测篇 | 移动端主体检测
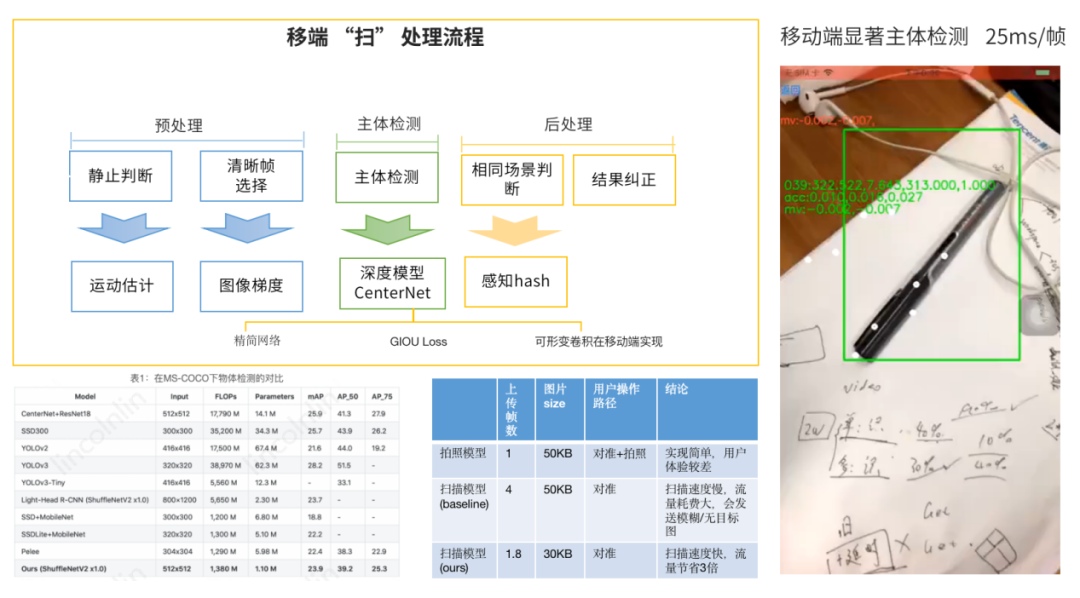
检测篇 | 服务端物品检测
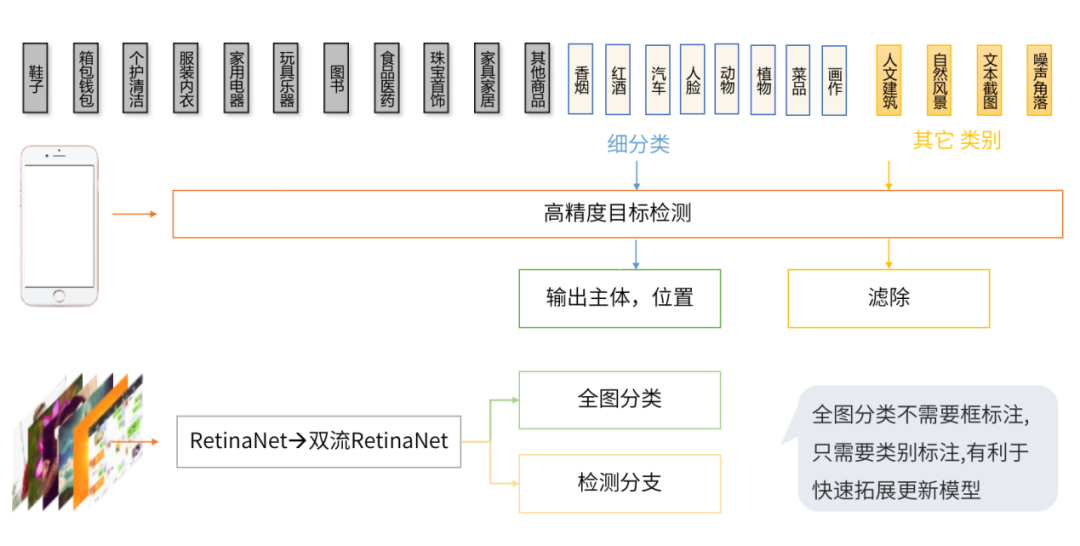
检测篇 | 目标检测的应用

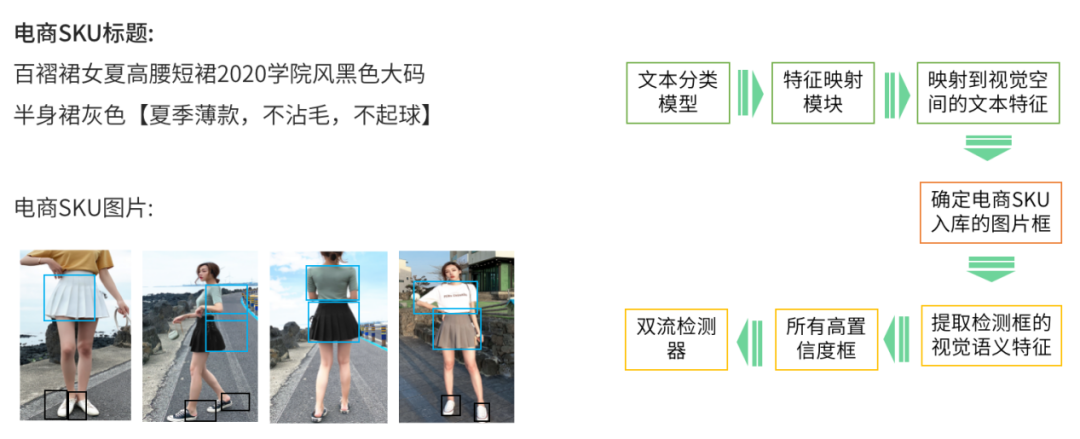

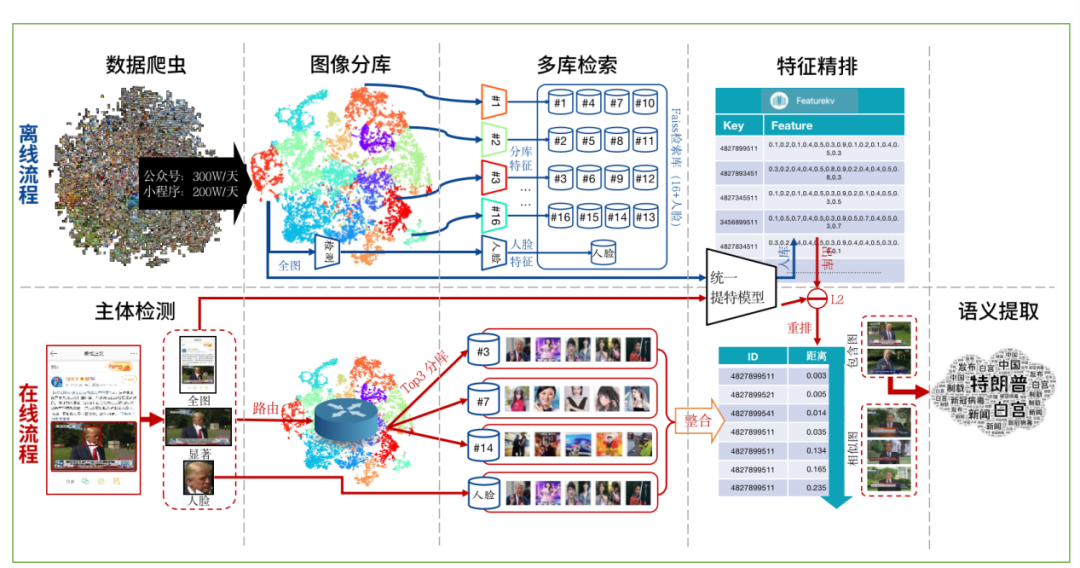
检索篇 | 大规模检索系统之分库实现

检索篇 | 识物引擎系统框架
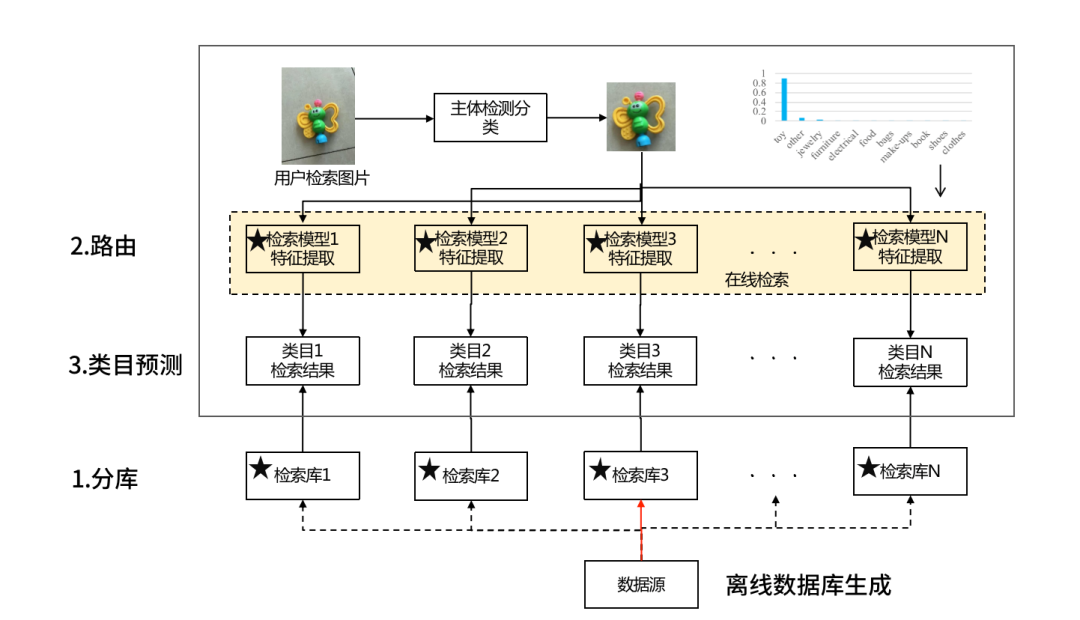
检索篇 | 识物引擎之分库路由
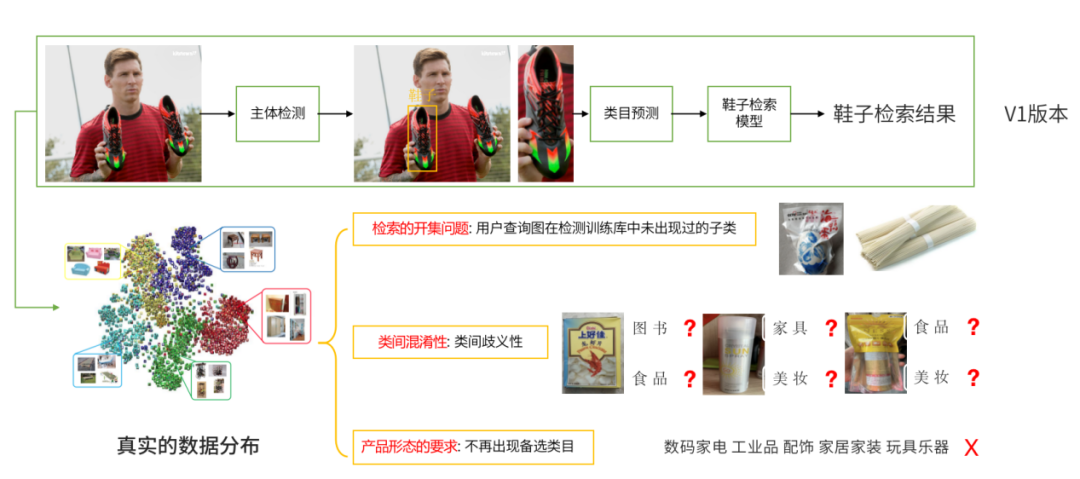
检索的开集问题,比如未出现过的子类容易分错;
类间混淆性,从视觉上存在歧义。
检索篇 | 识物引擎之类目预测
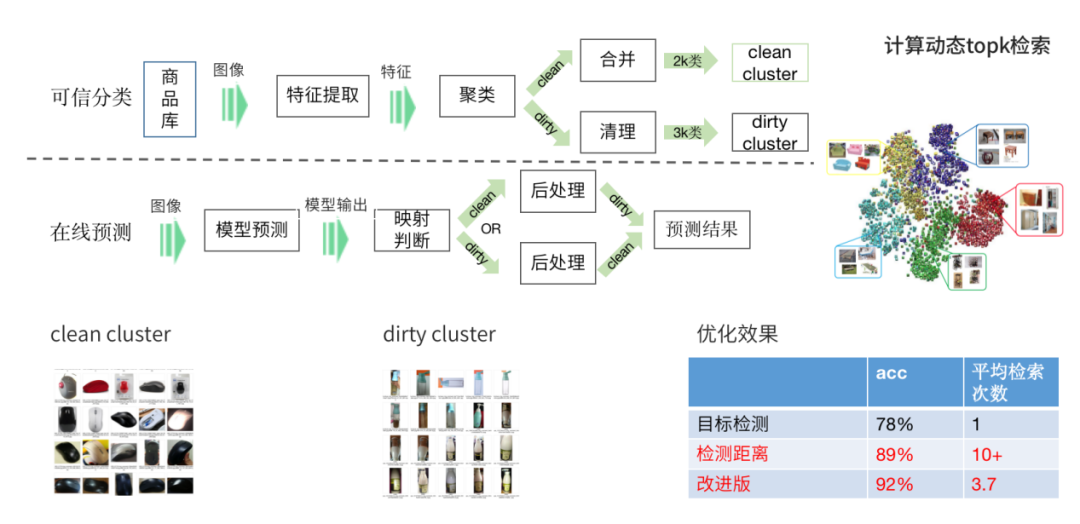
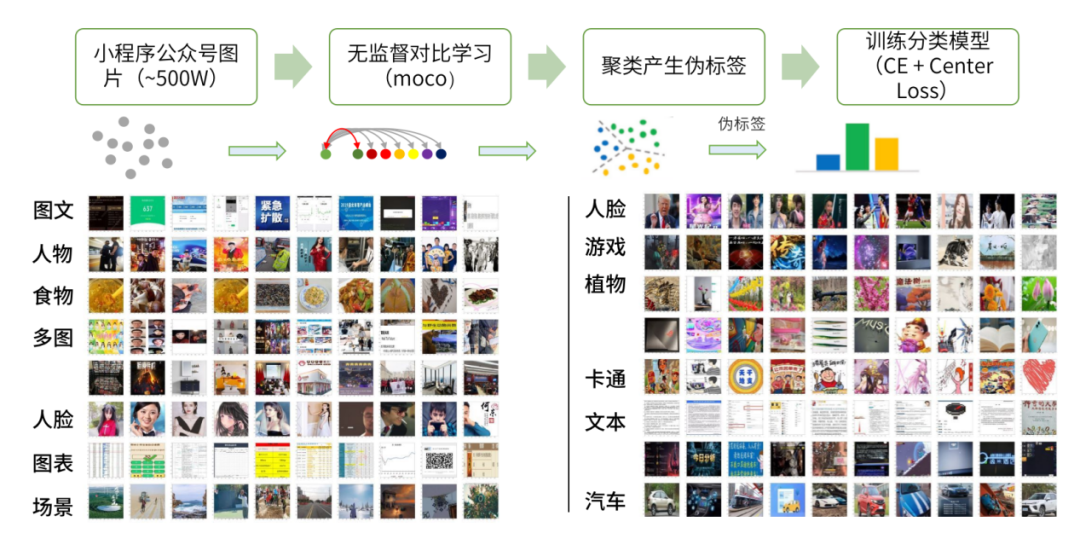
检索篇 | 通用以图搜图之无监督的分库
检索篇 | 图搜流程框架
结语



🧐分享、点赞、在看,给个3连击呗!👇
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文